 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscape dynamics and implicit bias of one-pass SGD in overparameterized quadratic networks
Apr 03, 2026We analyze the one-pass stochastic gradient descent dynamics of a two-layer neural network with quadratic activations in a teacher--student framework. In the high-dimensional regime, where the input dimension $N$ and the number of samples $M$ diverge at fixed ratio $α= M/N$, and for finite hidden widths $(p,p^*)$ of the student and teacher, respectively, we study the low-dimensional ordinary differential equations that govern the evolution of the student--teacher and student--student overlap matrices. We show that overparameterization ($p>p^*$) only modestly accelerates escape from a plateau of poor generalization by modifying the prefactor of the exponential decay of the loss. We then examine how unconstrained weight norms introduce a continuous rotational symmetry that results in a nontrivial manifold of zero-loss solutions for $p>1$. From this manifold the dynamics consistently selects the closest solution to the random initialization, as enforced by a conserved quantity in the ODEs governing the evolution of the overlaps. Finally, a Hessian analysis of the population-loss landscape confirms that the plateau and the solution manifold correspond to saddles with at least one negative eigenvalue and to marginal minima in the population-loss geometry, respectively.
From Zero to Hero: How local curvature at artless initial conditions leads away from bad minima
Mar 04, 2024



We investigate the optimization dynamics of gradient descent in a non-convex and high-dimensional setting, with a focus on the phase retrieval problem as a case study for complex loss landscapes. We first study the high-dimensional limit where both the number $M$ and the dimension $N$ of the data are going to infinity at fixed signal-to-noise ratio $\alpha = M/N$. By analyzing how the local curvature changes during optimization, we uncover that for intermediate $\alpha$, the Hessian displays a downward direction pointing towards good minima in the first regime of the descent, before being trapped in bad minima at the end. Hence, the local landscape is benign and informative at first, before gradient descent brings the system into a uninformative maze. The transition between the two regimes is associated to a BBP-type threshold in the time-dependent Hessian. Through both theoretical analysis and numerical experiments, we show that in practical cases, i.e. for finite but even very large $N$, successful optimization via gradient descent in phase retrieval is achieved by falling towards the good minima before reaching the bad ones. This mechanism explains why successful recovery is obtained well before the algorithmic transition corresponding to the high-dimensional limit. Technically, this is associated to strong logarithmic corrections of the algorithmic transition at large $N$ with respect to the one expected in the $N\to\infty$ limit. Our analysis sheds light on such a new mechanism that facilitate gradient descent dynamics in finite large dimensions, also highlighting the importance of good initialization of spectral properties for optimization in complex high-dimensional landscapes.
Complex Dynamics in Simple Neural Networks: Understanding Gradient Flow in Phase Retrieval
Jun 12, 2020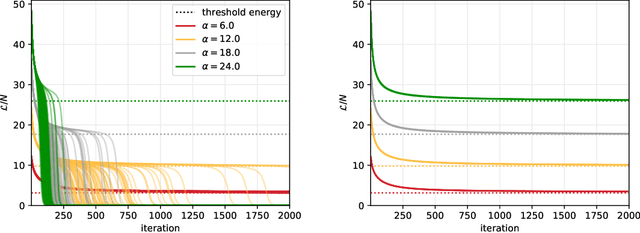
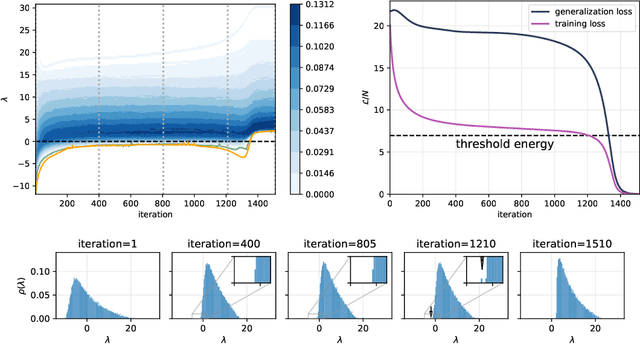
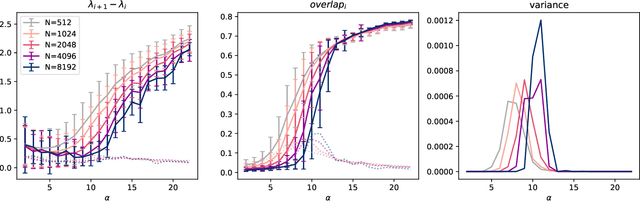
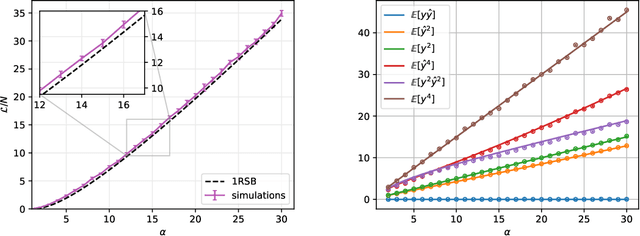
Despite the widespread use of gradient-based algorithms for optimizing high-dimensional non-convex functions, understanding their ability of finding good minima instead of being trapped in spurious ones remains to a large extent an open problem. Here we focus on gradient flow dynamics for phase retrieval from random measurements. When the ratio of the number of measurements over the input dimension is small the dynamics remains trapped in spurious minima with large basins of attraction. We find analytically that above a critical ratio those critical points become unstable developing a negative direction toward the signal. By numerical experiments we show that in this regime the gradient flow algorithm is not trapped; it drifts away from the spurious critical points along the unstable direction and succeeds in finding the global minimum. Using tools from statistical physics we characterize this phenomenon, which is related to a BBP-type transition in the Hessian of the spurious minima.
Who is Afraid of Big Bad Minima? Analysis of Gradient-Flow in a Spiked Matrix-Tensor Model
Jul 22, 2019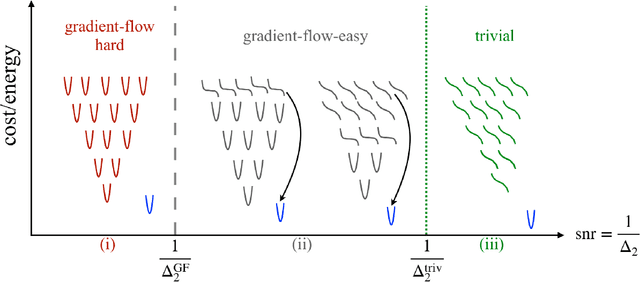
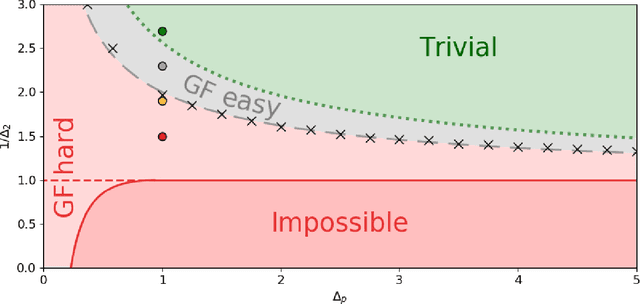
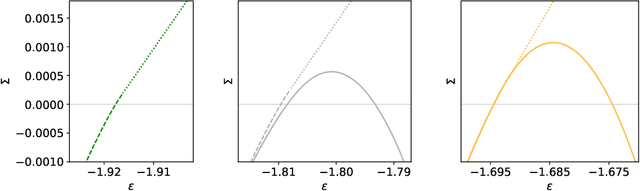
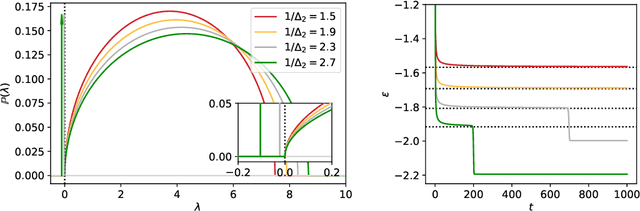
Gradient-based algorithms are effective for many machine learning tasks, but despite ample recent effort and some progress, it often remains unclear why they work in practice in optimising high-dimensional non-convex functions and why they find good minima instead of being trapped in spurious ones. Here we present a quantitative theory explaining this behaviour in a spiked matrix-tensor model. Our framework is based on the Kac-Rice analysis of stationary points and a closed-form analysis of gradient-flow originating from statistical physics. We show that there is a well defined region of parameters where the gradient-flow algorithm finds a good global minimum despite the presence of exponentially many spurious local minima. We show that this is achieved by surfing on saddles that have strong negative direction towards the global minima, a phenomenon that is connected to a BBP-type threshold in the Hessian describing the critical points of the landscapes.
How to iron out rough landscapes and get optimal performances: Replicated Gradient Descent and its application to tensor PCA
May 29, 2019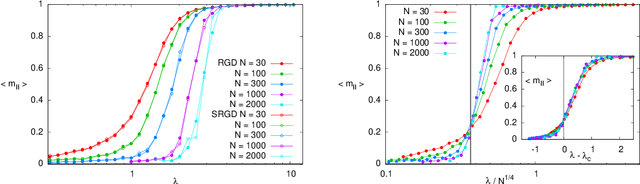
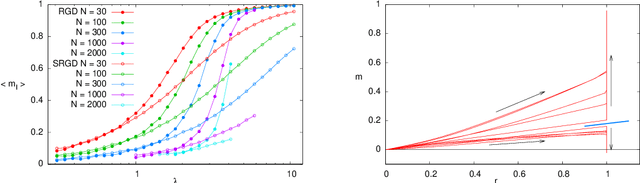
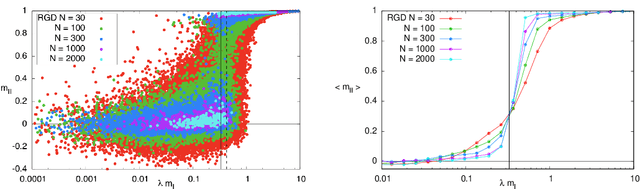
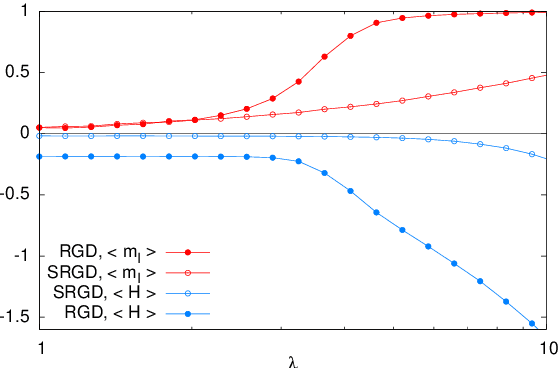
In many high-dimensional estimation problems the main task consists in minimizing a cost function, which is often strongly non-convex when scanned in the space of parameters to be estimated. A standard solution to flatten the corresponding rough landscape consists in summing the losses associated to different data points and obtain a smoother empirical risk. Here we propose a complementary method that works for a single data point. The main idea is that a large amount of the roughness is uncorrelated in different parts of the landscape. One can then substantially reduce the noise by evaluating an empirical average of the gradient obtained as a sum over many random independent positions in the space of parameters to be optimized. We present an algorithm, called Replicated Gradient Descent, based on this idea and we apply it to tensor PCA, which is a very hard estimation problem. We show that Replicated Gradient Descent over-performs physical algorithms such as gradient descent and approximate message passing and matches the best algorithmic thresholds known so far, obtained by tensor unfolding and methods based on sum-of-squares.
Marvels and Pitfalls of the Langevin Algorithm in Noisy High-dimensional Inference
Dec 21, 2018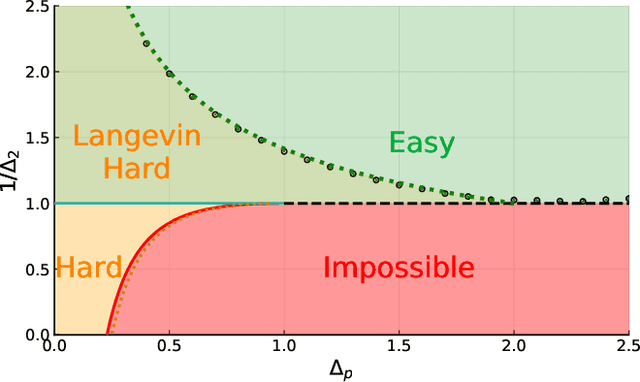
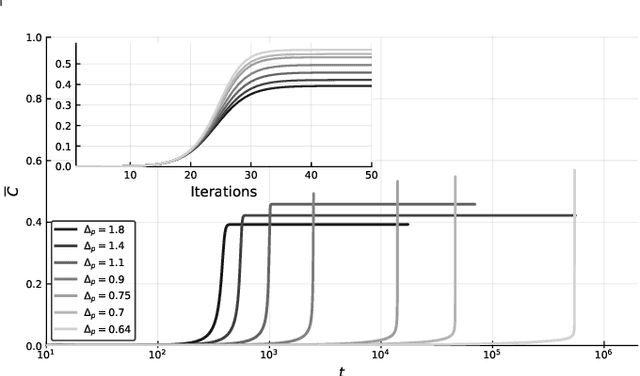
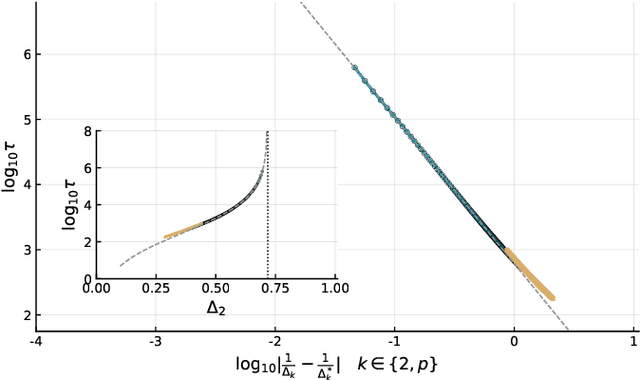
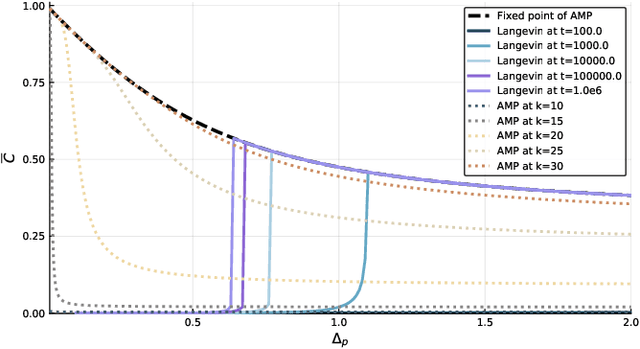
Gradient-descent-based algorithms and their stochastic versions have widespread applications in machine learning and statistical inference. In this work we perform an analytic study of the performances of one of them, the Langevin algorithm, in the context of noisy high-dimensional inference. We employ the Langevin algorithm to sample the posterior probability measure for the spiked matrix-tensor model. The typical behaviour of this algorithm is described by a system of integro-differential equations that we call the Langevin state evolution, whose solution is compared with the one of the state evolution of approximate message passing (AMP). Our results show that, remarkably, the algorithmic threshold of the Langevin algorithm is sub-optimal with respect to the one given by AMP. We conjecture this phenomenon to be due to the residual glassiness present in that region of parameters. Finally we show how a landscape-annealing protocol, that uses the Langevin algorithm but violate the Bayes-optimality condition, can approach the performance of AMP.
Complex energy landscapes in spiked-tensor and simple glassy models: ruggedness, arrangements of local minima and phase transitions
Apr 24, 2018


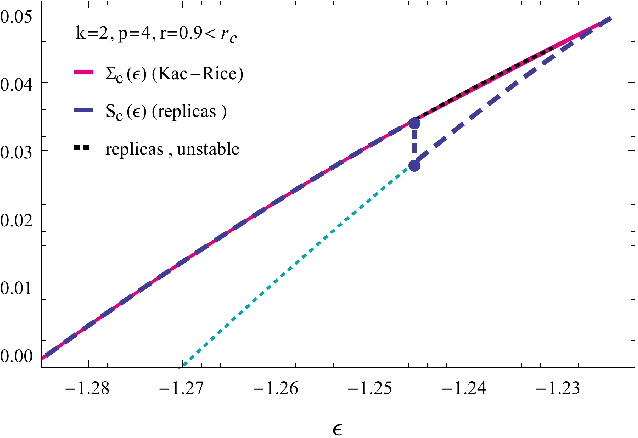
We study rough high-dimensional landscapes in which an increasingly stronger preference for a given configuration emerges. Such energy landscapes arise in glass physics and inference. In particular we focus on random Gaussian functions, and on the spiked-tensor model and generalizations. We thoroughly analyze the statistical properties of the corresponding landscapes and characterize the associated geometrical phase transitions. In order to perform our study, we develop a framework based on the Kac-Rice method that allows to compute the complexity of the landscape, i.e. the logarithm of the typical number of stationary points and their Hessian. This approach generalizes the one used to compute rigorously the annealed complexity of mean-field glass models. We discuss its advantages with respect to previous frameworks, in particular the thermodynamical replica method which is shown to lead to partially incorrect predictions.