 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Connections: Membership Inference Attacks for the Multi-Table Synthetic Data Setting
Feb 06, 2026Synthetic tabular data has gained attention for enabling privacy-preserving data sharing. While substantial progress has been made in single-table synthetic generation where data are modeled at the row or item level, most real-world data exists in relational databases where a user's information spans items across multiple interconnected tables. Recent advances in synthetic relational data generation have emerged to address this complexity, yet release of these data introduce unique privacy challenges as information can be leaked not only from individual items but also through the relationships that comprise a complete user entity. To address this, we propose a novel Membership Inference Attack (MIA) setting to audit the empirical user-level privacy of synthetic relational data and show that single-table MIAs that audit at an item level underestimate user-level privacy leakage. We then propose Multi-Table Membership Inference Attack (MT-MIA), a novel adversarial attack under a No-Box threat model that targets learned representations of user entities via Heterogeneous Graph Neural Networks. By incorporating all connected items for a user, MT-MIA better targets user-level vulnerabilities induced by inter-tabular relationships than existing attacks. We evaluate MT-MIA on a range of real-world multi-table datasets and demonstrate that this vulnerability exists in state-of-the-art relational synthetic data generators, employing MT-MIA to additionally study where this leakage occurs.
When Tables Leak: Attacking String Memorization in LLM-Based Tabular Data Generation
Dec 09, 2025Large Language Models (LLMs) have recently demonstrated remarkable performance in generating high-quality tabular synthetic data. In practice, two primary approaches have emerged for adapting LLMs to tabular data generation: (i) fine-tuning smaller models directly on tabular datasets, and (ii) prompting larger models with examples provided in context. In this work, we show that popular implementations from both regimes exhibit a tendency to compromise privacy by reproducing memorized patterns of numeric digits from their training data. To systematically analyze this risk, we introduce a simple No-box Membership Inference Attack (MIA) called LevAtt that assumes adversarial access to only the generated synthetic data and targets the string sequences of numeric digits in synthetic observations. Using this approach, our attack exposes substantial privacy leakage across a wide range of models and datasets, and in some cases, is even a perfect membership classifier on state-of-the-art models. Our findings highlight a unique privacy vulnerability of LLM-based synthetic data generation and the need for effective defenses. To this end, we propose two methods, including a novel sampling strategy that strategically perturbs digits during generation. Our evaluation demonstrates that this approach can defeat these attacks with minimal loss of fidelity and utility of the synthetic data.
Privacy Auditing Synthetic Data Release through Local Likelihood Attacks
Aug 28, 2025Auditing the privacy leakage of synthetic data is an important but unresolved problem. Most existing privacy auditing frameworks for synthetic data rely on heuristics and unreasonable assumptions to attack the failure modes of generative models, exhibiting limited capability to describe and detect the privacy exposure of training data through synthetic data release. In this paper, we study designing Membership Inference Attacks (MIAs) that specifically exploit the observation that tabular generative models tend to significantly overfit to certain regions of the training distribution. Here, we propose Generative Likelihood Ratio Attack (Gen-LRA), a novel, computationally efficient No-Box MIA that, with no assumption of model knowledge or access, formulates its attack by evaluating the influence a test observation has in a surrogate model's estimation of a local likelihood ratio over the synthetic data. Assessed over a comprehensive benchmark spanning diverse datasets, model architectures, and attack parameters, we find that Gen-LRA consistently dominates other MIAs for generative models across multiple performance metrics. These results underscore Gen-LRA's effectiveness as a privacy auditing tool for the release of synthetic data, highlighting the significant privacy risks posed by generative model overfitting in real-world applications.
GReaTER: Generate Realistic Tabular data after data Enhancement and Reduction
Mar 19, 2025Tabular data synthesis involves not only multi-table synthesis but also generating multi-modal data (e.g., strings and categories), which enables diverse knowledge synthesis. However, separating numerical and categorical data has limited the effectiveness of tabular data generation. The GReaT (Generate Realistic Tabular Data) framework uses Large Language Models (LLMs) to encode entire rows, eliminating the need to partition data types. Despite this, the framework's performance is constrained by two issues: (1) tabular data entries lack sufficient semantic meaning, limiting LLM's ability to leverage pre-trained knowledge for in-context learning, and (2) complex multi-table datasets struggle to establish effective relationships for collaboration. To address these, we propose GReaTER (Generate Realistic Tabular Data after data Enhancement and Reduction), which includes: (1) a data semantic enhancement system that improves LLM's understanding of tabular data through mapping, enabling better in-context learning, and (2) a cross-table connecting method to establish efficient relationships across complex tables. Experimental results show that GReaTER outperforms the GReaT framework.
Data Deletion for Linear Regression with Noisy SGD
Oct 12, 2024


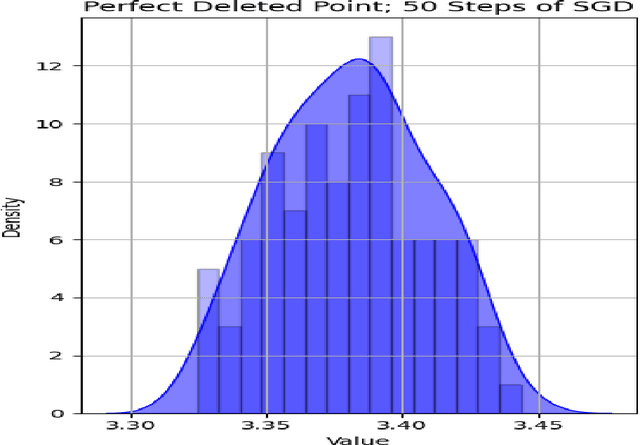
In the current era of big data and machine learning, it's essential to find ways to shrink the size of training dataset while preserving the training performance to improve efficiency. However, the challenge behind it includes providing practical ways to find points that can be deleted without significantly harming the training result and suffering from problems like underfitting. We therefore present the perfect deleted point problem for 1-step noisy SGD in the classical linear regression task, which aims to find the perfect deleted point in the training dataset such that the model resulted from the deleted dataset will be identical to the one trained without deleting it. We apply the so-called signal-to-noise ratio and suggest that its value is closely related to the selection of the perfect deleted point. We also implement an algorithm based on this and empirically show the effectiveness of it in a synthetic dataset. Finally we analyze the consequences of the perfect deleted point, specifically how it affects the training performance and privacy budget, therefore highlighting its potential. This research underscores the importance of data deletion and calls for urgent need for more studies in this field.
Advancing Retail Data Science: Comprehensive Evaluation of Synthetic Data
Jun 19, 2024The evaluation of synthetic data generation is crucial, especially in the retail sector where data accuracy is paramount. This paper introduces a comprehensive framework for assessing synthetic retail data, focusing on fidelity, utility, and privacy. Our approach differentiates between continuous and discrete data attributes, providing precise evaluation criteria. Fidelity is measured through stability and generalizability. Stability ensures synthetic data accurately replicates known data distributions, while generalizability confirms its robustness in novel scenarios. Utility is demonstrated through the synthetic data's effectiveness in critical retail tasks such as demand forecasting and dynamic pricing, proving its value in predictive analytics and strategic planning. Privacy is safeguarded using Differential Privacy, ensuring synthetic data maintains a perfect balance between resembling training and holdout datasets without compromising security. Our findings validate that this framework provides reliable and scalable evaluation for synthetic retail data. It ensures high fidelity, utility, and privacy, making it an essential tool for advancing retail data science. This framework meets the evolving needs of the retail industry with precision and confidence, paving the way for future advancements in synthetic data methodologies.
Data Plagiarism Index: Characterizing the Privacy Risk of Data-Copying in Tabular Generative Models
Jun 18, 2024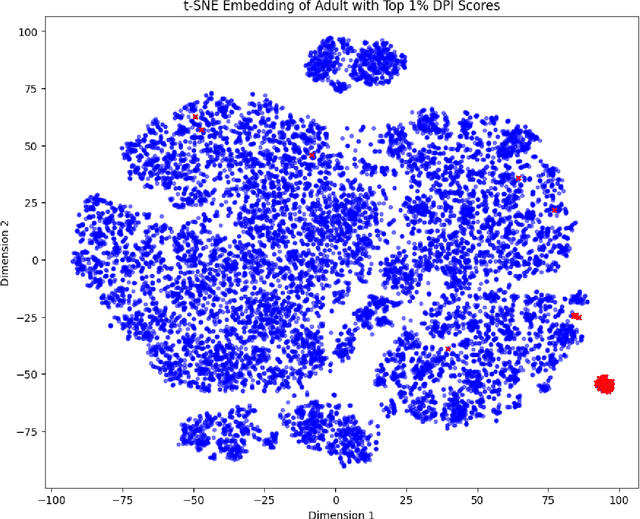
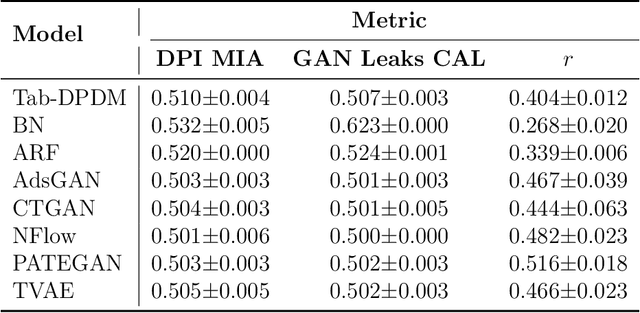


The promise of tabular generative models is to produce realistic synthetic data that can be shared and safely used without dangerous leakage of information from the training set. In evaluating these models, a variety of methods have been proposed to measure the tendency to copy data from the training dataset when generating a sample. However, these methods suffer from either not considering data-copying from a privacy threat perspective, not being motivated by recent results in the data-copying literature or being difficult to make compatible with the high dimensional, mixed type nature of tabular data. This paper proposes a new similarity metric and Membership Inference Attack called Data Plagiarism Index (DPI) for tabular data. We show that DPI evaluates a new intuitive definition of data-copying and characterizes the corresponding privacy risk. We show that the data-copying identified by DPI poses both privacy and fairness threats to common, high performing architectures; underscoring the necessity for more sophisticated generative modeling techniques to mitigate this issue.
BadGD: A unified data-centric framework to identify gradient descent vulnerabilities
May 24, 2024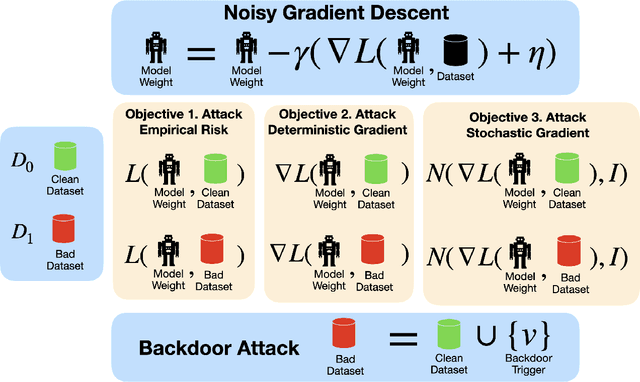
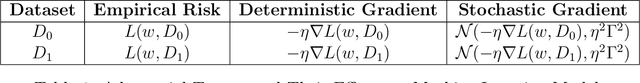
We present BadGD, a unified theoretical framework that exposes the vulnerabilities of gradient descent algorithms through strategic backdoor attacks. Backdoor attacks involve embedding malicious triggers into a training dataset to disrupt the model's learning process. Our framework introduces three novel constructs: Max RiskWarp Trigger, Max GradWarp Trigger, and Max GradDistWarp Trigger, each designed to exploit specific aspects of gradient descent by distorting empirical risk, deterministic gradients, and stochastic gradients respectively. We rigorously define clean and backdoored datasets and provide mathematical formulations for assessing the distortions caused by these malicious backdoor triggers. By measuring the impact of these triggers on the model training procedure, our framework bridges existing empirical findings with theoretical insights, demonstrating how a malicious party can exploit gradient descent hyperparameters to maximize attack effectiveness. In particular, we show that these exploitations can significantly alter the loss landscape and gradient calculations, leading to compromised model integrity and performance. This research underscores the severe threats posed by such data-centric attacks and highlights the urgent need for robust defenses in machine learning. BadGD sets a new standard for understanding and mitigating adversarial manipulations, ensuring the reliability and security of AI systems.
Discriminative Estimation of Total Variation Distance: A Fidelity Auditor for Generative Data
May 24, 2024With the proliferation of generative AI and the increasing volume of generative data (also called as synthetic data), assessing the fidelity of generative data has become a critical concern. In this paper, we propose a discriminative approach to estimate the total variation (TV) distance between two distributions as an effective measure of generative data fidelity. Our method quantitatively characterizes the relation between the Bayes risk in classifying two distributions and their TV distance. Therefore, the estimation of total variation distance reduces to that of the Bayes risk. In particular, this paper establishes theoretical results regarding the convergence rate of the estimation error of TV distance between two Gaussian distributions. We demonstrate that, with a specific choice of hypothesis class in classification, a fast convergence rate in estimating the TV distance can be achieved. Specifically, the estimation accuracy of the TV distance is proven to inherently depend on the separation of two Gaussian distributions: smaller estimation errors are achieved when the two Gaussian distributions are farther apart. This phenomenon is also validated empirically through extensive simulations. In the end, we apply this discriminative estimation method to rank fidelity of synthetic image data using the MNIST dataset.
Improve Fidelity and Utility of Synthetic Credit Card Transaction Time Series from Data-centric Perspective
Jan 01, 2024Exploring generative model training for synthetic tabular data, specifically in sequential contexts such as credit card transaction data, presents significant challenges. This paper addresses these challenges, focusing on attaining both high fidelity to actual data and optimal utility for machine learning tasks. We introduce five pre-processing schemas to enhance the training of the Conditional Probabilistic Auto-Regressive Model (CPAR), demonstrating incremental improvements in the synthetic data's fidelity and utility. Upon achieving satisfactory fidelity levels, our attention shifts to training fraud detection models tailored for time-series data, evaluating the utility of the synthetic data. Our findings offer valuable insights and practical guidelines for synthetic data practitioners in the finance sector, transitioning from real to synthetic datasets for training purposes, and illuminating broader methodologies for synthesizing credit card transaction time series.