 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Tables Leak: Attacking String Memorization in LLM-Based Tabular Data Generation
Dec 09, 2025Large Language Models (LLMs) have recently demonstrated remarkable performance in generating high-quality tabular synthetic data. In practice, two primary approaches have emerged for adapting LLMs to tabular data generation: (i) fine-tuning smaller models directly on tabular datasets, and (ii) prompting larger models with examples provided in context. In this work, we show that popular implementations from both regimes exhibit a tendency to compromise privacy by reproducing memorized patterns of numeric digits from their training data. To systematically analyze this risk, we introduce a simple No-box Membership Inference Attack (MIA) called LevAtt that assumes adversarial access to only the generated synthetic data and targets the string sequences of numeric digits in synthetic observations. Using this approach, our attack exposes substantial privacy leakage across a wide range of models and datasets, and in some cases, is even a perfect membership classifier on state-of-the-art models. Our findings highlight a unique privacy vulnerability of LLM-based synthetic data generation and the need for effective defenses. To this end, we propose two methods, including a novel sampling strategy that strategically perturbs digits during generation. Our evaluation demonstrates that this approach can defeat these attacks with minimal loss of fidelity and utility of the synthetic data.
Privacy Auditing Synthetic Data Release through Local Likelihood Attacks
Aug 28, 2025Auditing the privacy leakage of synthetic data is an important but unresolved problem. Most existing privacy auditing frameworks for synthetic data rely on heuristics and unreasonable assumptions to attack the failure modes of generative models, exhibiting limited capability to describe and detect the privacy exposure of training data through synthetic data release. In this paper, we study designing Membership Inference Attacks (MIAs) that specifically exploit the observation that tabular generative models tend to significantly overfit to certain regions of the training distribution. Here, we propose Generative Likelihood Ratio Attack (Gen-LRA), a novel, computationally efficient No-Box MIA that, with no assumption of model knowledge or access, formulates its attack by evaluating the influence a test observation has in a surrogate model's estimation of a local likelihood ratio over the synthetic data. Assessed over a comprehensive benchmark spanning diverse datasets, model architectures, and attack parameters, we find that Gen-LRA consistently dominates other MIAs for generative models across multiple performance metrics. These results underscore Gen-LRA's effectiveness as a privacy auditing tool for the release of synthetic data, highlighting the significant privacy risks posed by generative model overfitting in real-world applications.
Risk In Context: Benchmarking Privacy Leakage of Foundation Models in Synthetic Tabular Data Generation
Jul 22, 2025Synthetic tabular data is essential for machine learning workflows, especially for expanding small or imbalanced datasets and enabling privacy-preserving data sharing. However, state-of-the-art generative models (GANs, VAEs, diffusion models) rely on large datasets with thousands of examples. In low-data settings, often the primary motivation for synthetic data, these models can overfit, leak sensitive records, and require frequent retraining. Recent work uses large pre-trained transformers to generate rows via in-context learning (ICL), which needs only a few seed examples and no parameter updates, avoiding retraining. But ICL repeats seed rows verbatim, introducing a new privacy risk that has only been studied in text. The severity of this risk in tabular synthesis-where a single row may identify a person-remains unclear. We address this gap with the first benchmark of three foundation models (GPT-4o-mini, LLaMA 3.3 70B, TabPFN v2) against four baselines on 35 real-world tables from health, finance, and policy. We evaluate statistical fidelity, downstream utility, and membership inference leakage. Results show foundation models consistently have the highest privacy risk. LLaMA 3.3 70B reaches up to 54 percentage points higher true-positive rate at 1% FPR than the safest baseline. GPT-4o-mini and TabPFN are also highly vulnerable. We plot the privacy-utility frontier and show that CTGAN and GPT-4o-mini offer better tradeoffs. A factorial study finds that three zero-cost prompt tweaks-small batch size, low temperature, and using summary statistics-can reduce worst-case AUC by 14 points and rare-class leakage by up to 39 points while maintaining over 90% fidelity. Our benchmark offers a practical guide for safer low-data synthesis with foundation models.
Data Plagiarism Index: Characterizing the Privacy Risk of Data-Copying in Tabular Generative Models
Jun 18, 2024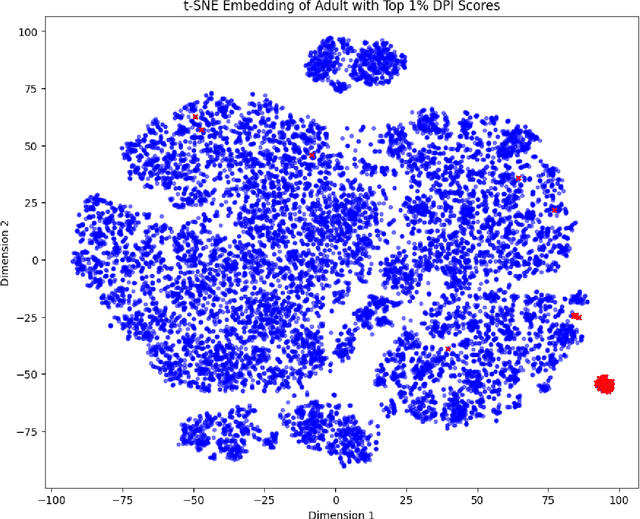
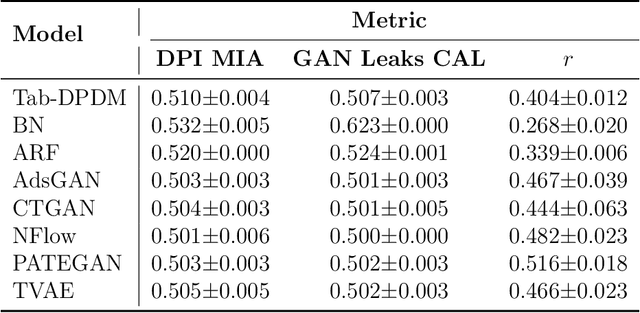


The promise of tabular generative models is to produce realistic synthetic data that can be shared and safely used without dangerous leakage of information from the training set. In evaluating these models, a variety of methods have been proposed to measure the tendency to copy data from the training dataset when generating a sample. However, these methods suffer from either not considering data-copying from a privacy threat perspective, not being motivated by recent results in the data-copying literature or being difficult to make compatible with the high dimensional, mixed type nature of tabular data. This paper proposes a new similarity metric and Membership Inference Attack called Data Plagiarism Index (DPI) for tabular data. We show that DPI evaluates a new intuitive definition of data-copying and characterizes the corresponding privacy risk. We show that the data-copying identified by DPI poses both privacy and fairness threats to common, high performing architectures; underscoring the necessity for more sophisticated generative modeling techniques to mitigate this issue.
FairRR: Pre-Processing for Group Fairness through Randomized Response
Mar 12, 2024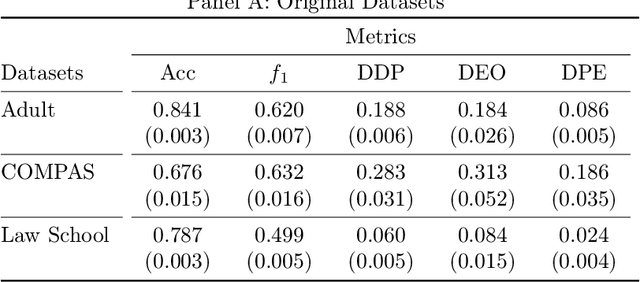
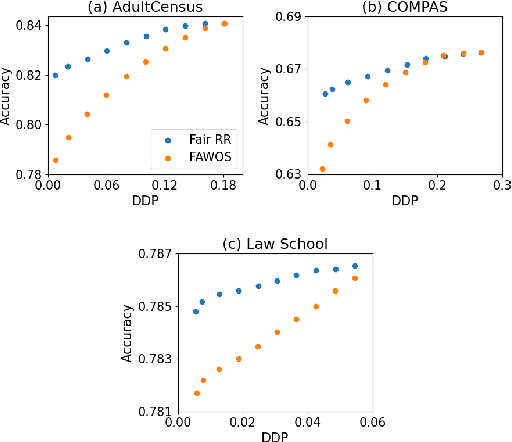
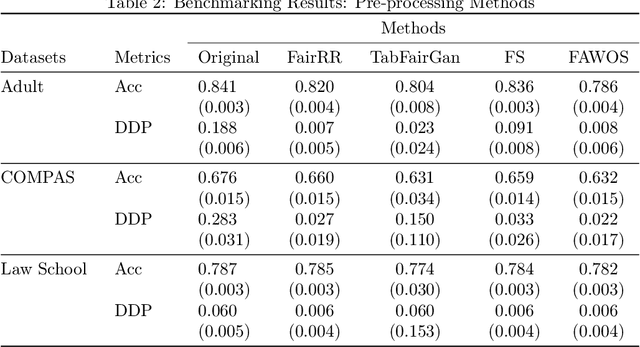
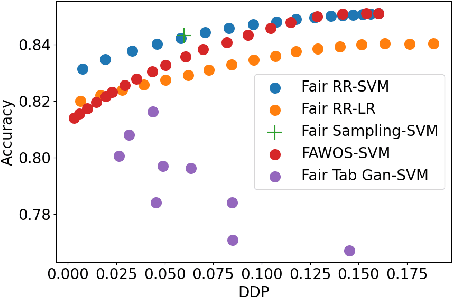
The increasing usage of machine learning models in consequential decision-making processes has spurred research into the fairness of these systems. While significant work has been done to study group fairness in the in-processing and post-processing setting, there has been little that theoretically connects these results to the pre-processing domain. This paper proposes that achieving group fairness in downstream models can be formulated as finding the optimal design matrix in which to modify a response variable in a Randomized Response framework. We show that measures of group fairness can be directly controlled for with optimal model utility, proposing a pre-processing algorithm called FairRR that yields excellent downstream model utility and fairness.