 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Plagiarism Index: Characterizing the Privacy Risk of Data-Copying in Tabular Generative Models
Paper and Code
Jun 18, 2024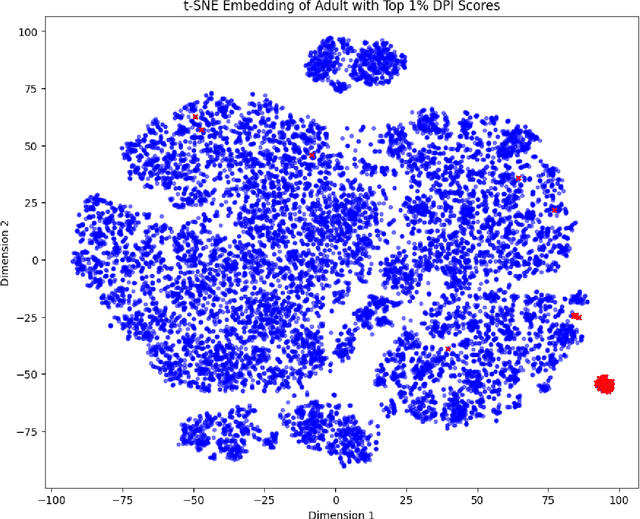
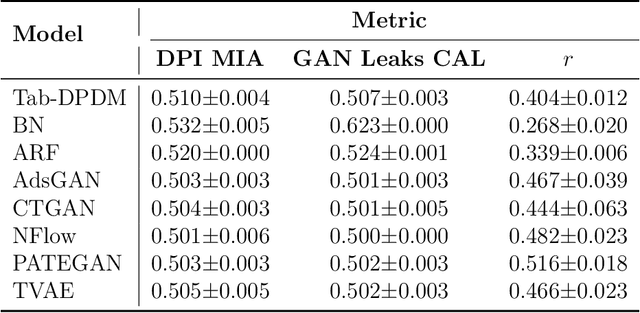


The promise of tabular generative models is to produce realistic synthetic data that can be shared and safely used without dangerous leakage of information from the training set. In evaluating these models, a variety of methods have been proposed to measure the tendency to copy data from the training dataset when generating a sample. However, these methods suffer from either not considering data-copying from a privacy threat perspective, not being motivated by recent results in the data-copying literature or being difficult to make compatible with the high dimensional, mixed type nature of tabular data. This paper proposes a new similarity metric and Membership Inference Attack called Data Plagiarism Index (DPI) for tabular data. We show that DPI evaluates a new intuitive definition of data-copying and characterizes the corresponding privacy risk. We show that the data-copying identified by DPI poses both privacy and fairness threats to common, high performing architectures; underscoring the necessity for more sophisticated generative modeling techniques to mitigate this issue.