 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating High Energy Physics Data Analysis with LLM-Powered Agents
Dec 08, 2025


We present a proof-of-principle study demonstrating the use of large language model (LLM) agents to automate a representative high energy physics (HEP) analysis. Using the Higgs boson diphoton cross-section measurement as a case study with ATLAS Open Data, we design a hybrid system that combines an LLM-based supervisor-coder agent with the Snakemake workflow manager. In this architecture, the workflow manager enforces reproducibility and determinism, while the agent autonomously generates, executes, and iteratively corrects analysis code in response to user instructions. We define quantitative evaluation metrics including success rate, error distribution, costs per specific task, and average number of API calls, to assess agent performance across multi-stage workflows. To characterize variability across architectures, we benchmark a representative selection of state-of-the-art LLMs spanning the Gemini and GPT-5 series, the Claude family, and leading open-weight models. While the workflow manager ensures deterministic execution of all analysis steps, the final outputs still show stochastic variation. Although we set the temperature to zero, other sampling parameters (e.g., top-p, top-k) remained at their defaults, and some reasoning-oriented models internally adjust these settings. Consequently, the models do not produce fully deterministic results. This study establishes the first LLM-agent-driven automated data-analysis framework in HEP, enabling systematic benchmarking of model capabilities, stability, and limitations in real-world scientific computing environments. The baseline code used in this work is available at https://huggingface.co/HWresearch/LLM4HEP. This work was accepted as a poster at the Machine Learning and the Physical Sciences (ML4PS) workshop at NeurIPS 2025. The initial submission was made on August 30, 2025.
Towards Geometry Guided Neural Relighting with Flash Photography
Aug 12, 2020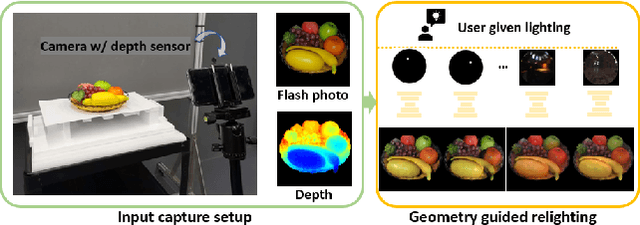

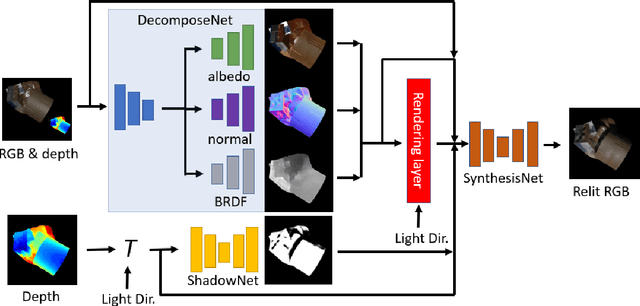
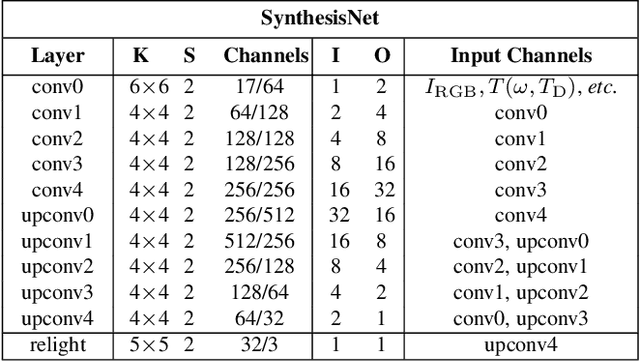
Previous image based relighting methods require capturing multiple images to acquire high frequency lighting effect under different lighting conditions, which needs nontrivial effort and may be unrealistic in certain practical use scenarios. While such approaches rely entirely on cleverly sampling the color images under different lighting conditions, little has been done to utilize geometric information that crucially influences the high-frequency features in the images, such as glossy highlight and cast shadow. We therefore propose a framework for image relighting from a single flash photograph with its corresponding depth map using deep learning. By incorporating the depth map, our approach is able to extrapolate realistic high-frequency effects under novel lighting via geometry guided image decomposition from the flashlight image, and predict the cast shadow map from the shadow-encoding transformed depth map. Moreover, the single-image based setup greatly simplifies the data capture process. We experimentally validate the advantage of our geometry guided approach over state-of-the-art image-based approaches in intrinsic image decomposition and image relighting, and also demonstrate our performance on real mobile phone photo examples.
StereoGAN: Bridging Synthetic-to-Real Domain Gap by Joint Optimization of Domain Translation and Stereo Matching
May 05, 2020
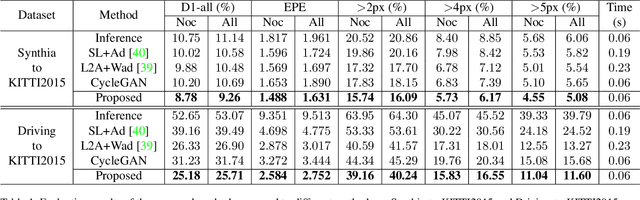

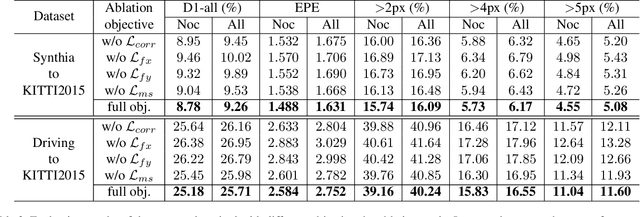
Large-scale synthetic datasets are beneficial to stereo matching but usually introduce known domain bias. Although unsupervised image-to-image translation networks represented by CycleGAN show great potential in dealing with domain gap, it is non-trivial to generalize this method to stereo matching due to the problem of pixel distortion and stereo mismatch after translation. In this paper, we propose an end-to-end training framework with domain translation and stereo matching networks to tackle this challenge. First, joint optimization between domain translation and stereo matching networks in our end-to-end framework makes the former facilitate the latter one to the maximum extent. Second, this framework introduces two novel losses, i.e., bidirectional multi-scale feature re-projection loss and correlation consistency loss, to help translate all synthetic stereo images into realistic ones as well as maintain epipolar constraints. The effective combination of above two contributions leads to impressive stereo-consistent translation and disparity estimation accuracy. In addition, a mode seeking regularization term is added to endow the synthetic-to-real translation results with higher fine-grained diversity. Extensive experiments demonstrate the effectiveness of the proposed framework on bridging the synthetic-to-real domain gap on stereo matching.
Deep End-to-End Alignment and Refinement for Time-of-Flight RGB-D Module
Sep 17, 2019
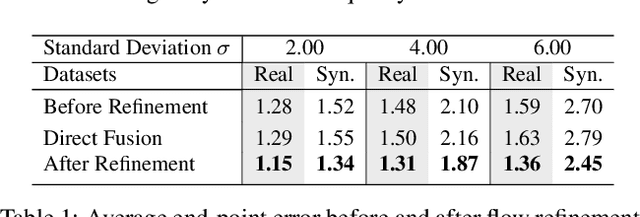
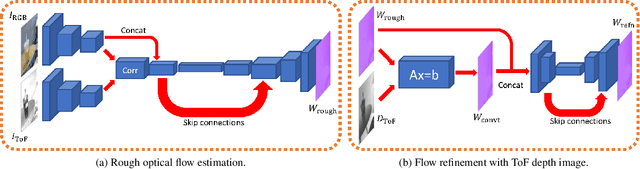
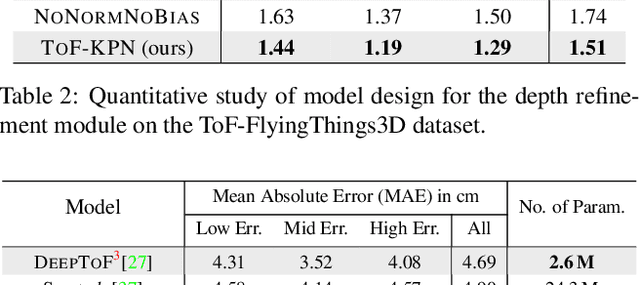
Recently, it is increasingly popular to equip mobile RGB cameras with Time-of-Flight (ToF) sensors for active depth sensing. However, for off-the-shelf ToF sensors, one must tackle two problems in order to obtain high-quality depth with respect to the RGB camera, namely 1) online calibration and alignment; and 2) complicated error correction for ToF depth sensing. In this work, we propose a framework for jointly alignment and refinement via deep learning. First, a cross-modal optical flow between the RGB image and the ToF amplitude image is estimated for alignment. The aligned depth is then refined via an improved kernel predicting network that performs kernel normalization and applies the bias prior to the dynamic convolution. To enrich our data for end-to-end training, we have also synthesized a dataset using tools from computer graphics. Experimental results demonstrate the effectiveness of our approach, achieving state-of-the-art for ToF refinement.
Confidence Inference for Focused Learning in Stereo Matching
Sep 25, 2018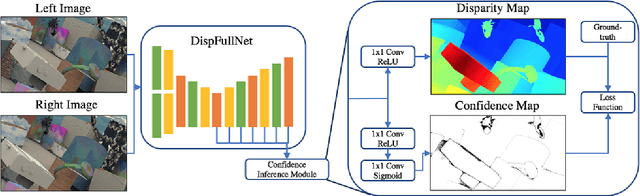
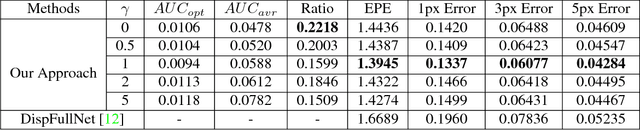
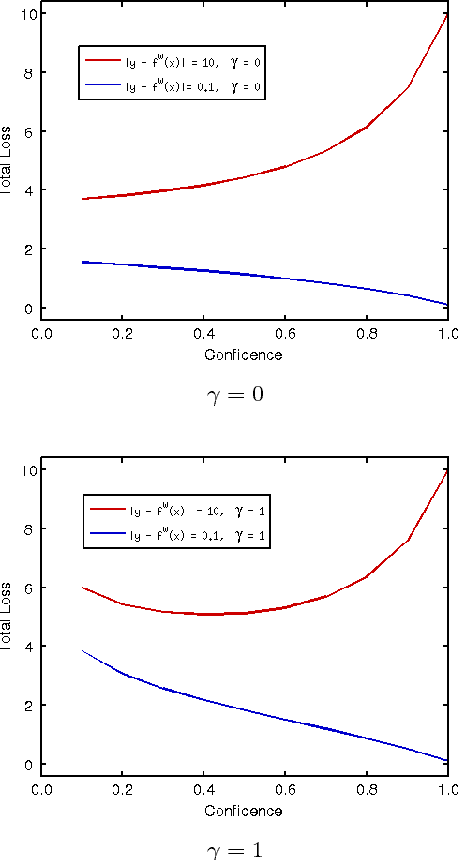

In this paper, we present confidence inference approachin an unsupervised way in stereo matching. Deep Neu-ral Networks (DNNs) have recently been achieving state-of-the-art performance. However, it is often hard to tellwhether the trained model was making sensible predictionsor just guessing at random. To address this problem, westart from a probabilistic interpretation of theL1loss usedin stereo matching, which inherently assumes an indepen-dent and identical (aka i.i.d.) Laplacian distribution. Weshow that with the newly introduced dense confidence map,the identical assumption is relaxed. Intuitively, the vari-ance in the Laplacian distribution is large for low confidentpixels while small for high-confidence pixels. In practice,the network learns toattenuatelow-confidence pixels (e.g.,noisy input, occlusions, featureless regions) andfocusonhigh-confidence pixels. Moreover, it can be observed fromexperiments that the focused learning is very helpful in find-ing a better convergence state of the trained model, reduc-ing over-fitting on a given dataset.
Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching
Jul 30, 2018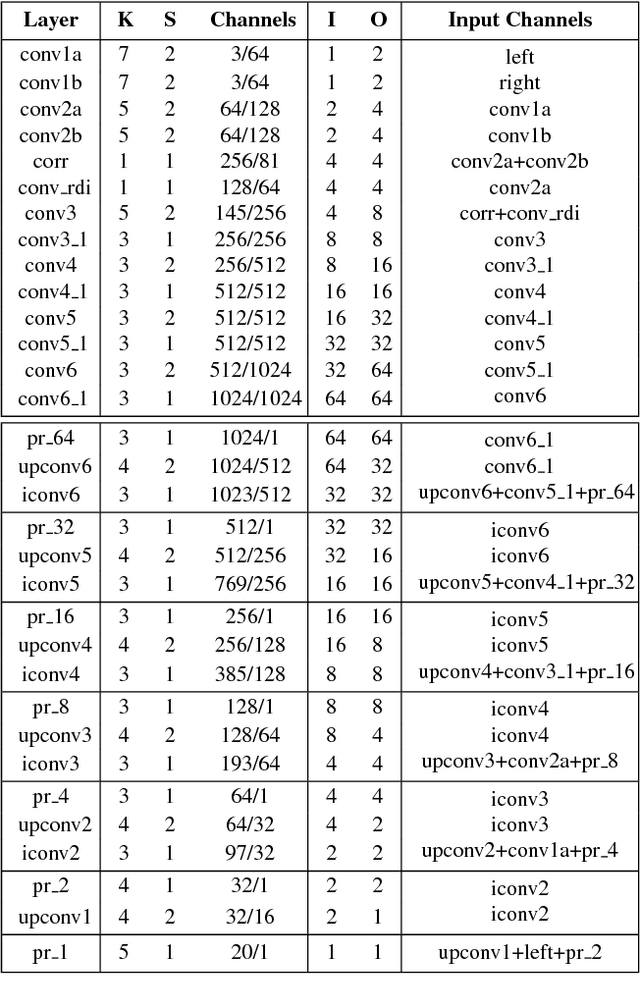


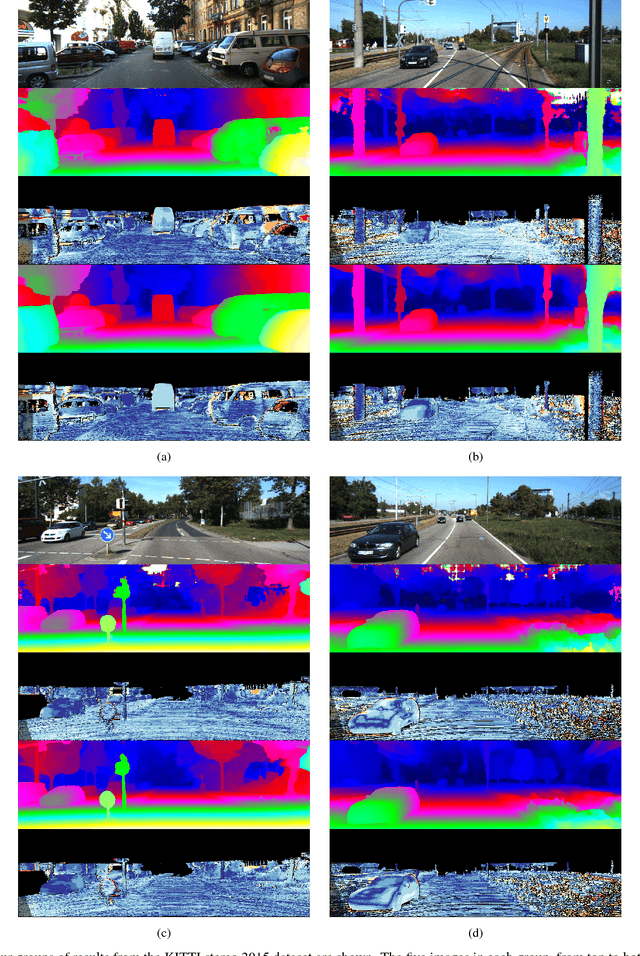
Leveraging on the recent developments in convolutional neural networks (CNNs), matching dense correspondence from a stereo pair has been cast as a learning problem, with performance exceeding traditional approaches. However, it remains challenging to generate high-quality disparities for the inherently ill-posed regions. To tackle this problem, we propose a novel cascade CNN architecture composing of two stages. The first stage advances the recently proposed DispNet by equipping it with extra up-convolution modules, leading to disparity images with more details. The second stage explicitly rectifies the disparity initialized by the first stage; it couples with the first-stage and generates residual signals across multiple scales. The summation of the outputs from the two stages gives the final disparity. As opposed to directly learning the disparity at the second stage, we show that residual learning provides more effective refinement. Moreover, it also benefits the training of the overall cascade network. Experimentation shows that our cascade residual learning scheme provides state-of-the-art performance for matching stereo correspondence. By the time of the submission of this paper, our method ranks first in the KITTI 2015 stereo benchmark, surpassing the prior works by a noteworthy margin.
Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
Mar 18, 2018
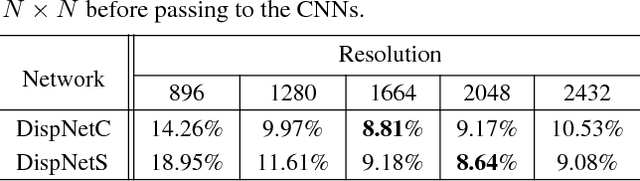
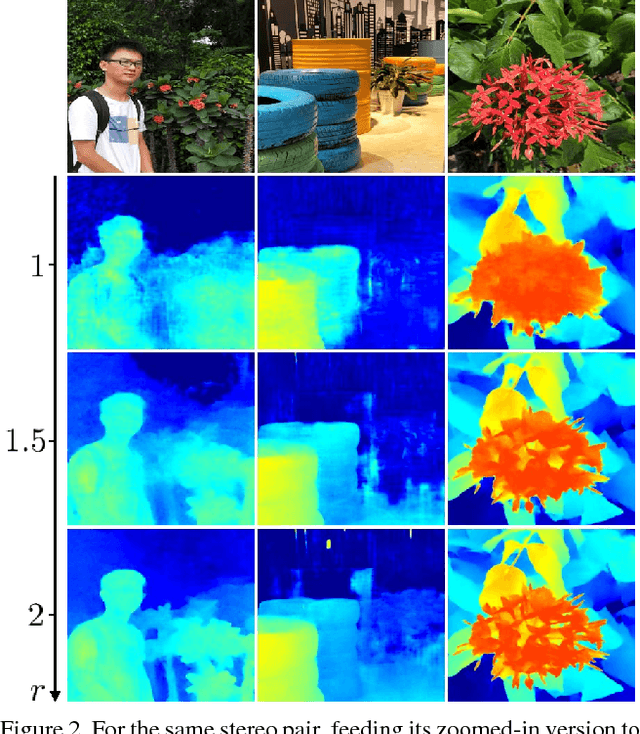

Despite the recent success of stereo matching with convolutional neural networks (CNNs), it remains arduous to generalize a pre-trained deep stereo model to a novel domain. A major difficulty is to collect accurate ground-truth disparities for stereo pairs in the target domain. In this work, we propose a self-adaptation approach for CNN training, utilizing both synthetic training data (with ground-truth disparities) and stereo pairs in the new domain (without ground-truths). Our method is driven by two empirical observations. By feeding real stereo pairs of different domains to stereo models pre-trained with synthetic data, we see that: i) a pre-trained model does not generalize well to the new domain, producing artifacts at boundaries and ill-posed regions; however, ii) feeding an up-sampled stereo pair leads to a disparity map with extra details. To avoid i) while exploiting ii), we formulate an iterative optimization problem with graph Laplacian regularization. At each iteration, the CNN adapts itself better to the new domain: we let the CNN learn its own higher-resolution output; at the meanwhile, a graph Laplacian regularization is imposed to discriminatively keep the desired edges while smoothing out the artifacts. We demonstrate the effectiveness of our method in two domains: daily scenes collected by smartphone cameras, and street views captured in a driving car.