 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching
Paper and Code
Jul 30, 2018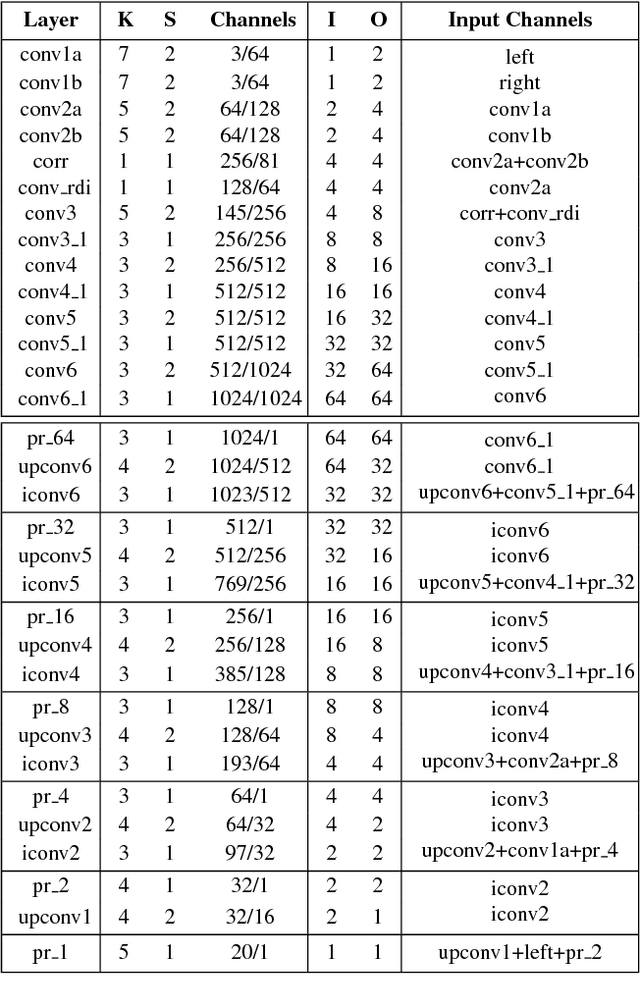


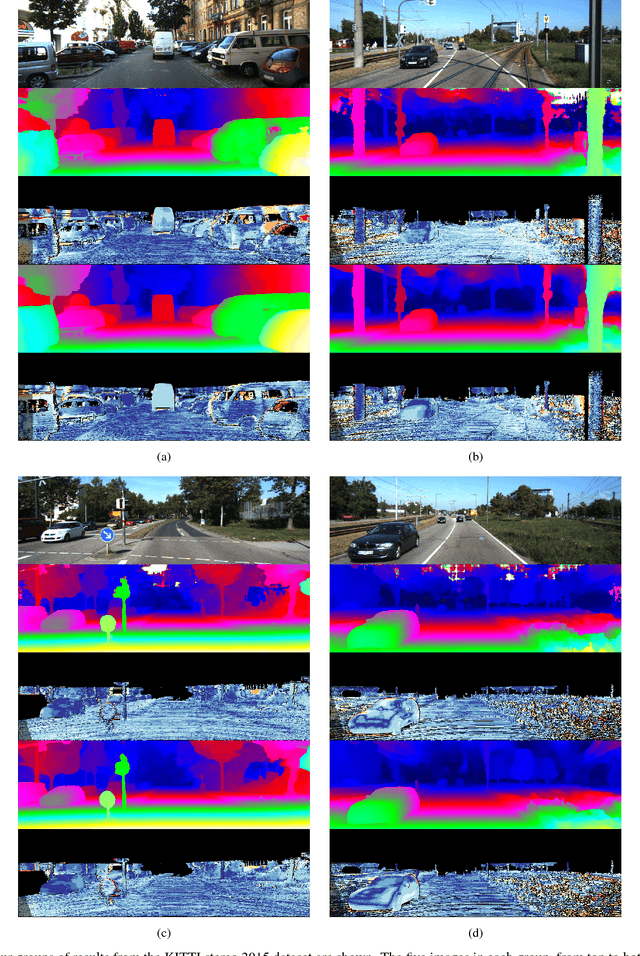
Leveraging on the recent developments in convolutional neural networks (CNNs), matching dense correspondence from a stereo pair has been cast as a learning problem, with performance exceeding traditional approaches. However, it remains challenging to generate high-quality disparities for the inherently ill-posed regions. To tackle this problem, we propose a novel cascade CNN architecture composing of two stages. The first stage advances the recently proposed DispNet by equipping it with extra up-convolution modules, leading to disparity images with more details. The second stage explicitly rectifies the disparity initialized by the first stage; it couples with the first-stage and generates residual signals across multiple scales. The summation of the outputs from the two stages gives the final disparity. As opposed to directly learning the disparity at the second stage, we show that residual learning provides more effective refinement. Moreover, it also benefits the training of the overall cascade network. Experimentation shows that our cascade residual learning scheme provides state-of-the-art performance for matching stereo correspondence. By the time of the submission of this paper, our method ranks first in the KITTI 2015 stereo benchmark, surpassing the prior works by a noteworthy margin.