 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Dec 30, 2025Making deep learning recommendation model (DLRM) training and inference fast and efficient is important. However, this presents three key system challenges - model architecture diversity, kernel primitive diversity, and hardware generation and architecture heterogeneity. This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architectures. KernelEvolve does so by operating at multiple programming abstractions, from Triton and CuTe DSL to low-level hardware agnostic languages, spanning the full hardware-software optimization stack. The kernel optimization process is described as graph-based search with selection policy, universal operator, fitness function, and termination rule, dynamically adapts to runtime execution context through retrieval-augmented prompt synthesis. We designed, implemented, and deployed KernelEvolve to optimize a wide variety of production recommendation models across generations of NVIDIA and AMD GPUs, as well as Meta's AI accelerators. We validate KernelEvolve on the publicly-available KernelBench suite, achieving 100% pass rate on all 250 problems across three difficulty levels, and 160 PyTorch ATen operators across three heterogeneous hardware platforms, demonstrating 100% correctness. KernelEvolve reduces development time from weeks to hours and achieves substantial performance improvements over PyTorch baselines across diverse production use cases and for heterogeneous AI systems at-scale. Beyond performance efficiency improvements, KernelEvolve significantly mitigates the programmability barrier for new AI hardware by enabling automated kernel generation for in-house developed AI hardware.
Dynamic Relational Inference in Multi-Agent Trajectories
Jul 16, 2020

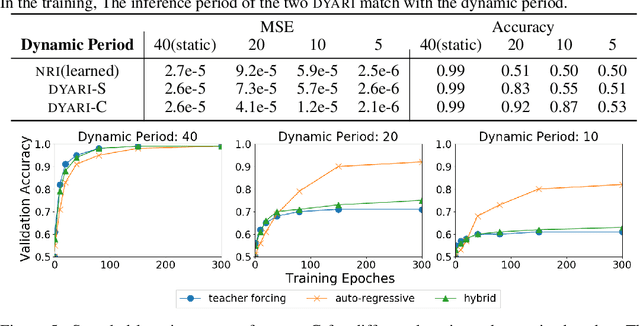
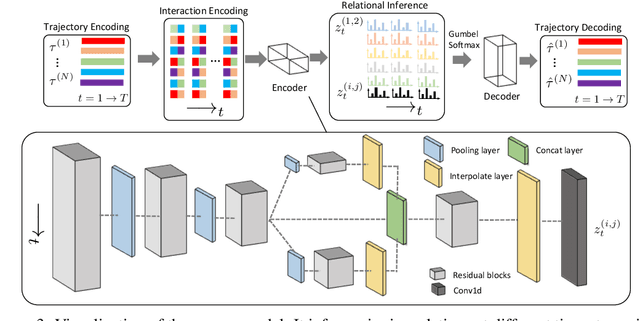
Inferring interactions from multi-agent trajectories has broad applications in physics, vision and robotics. Neural relational inference (NRI) is a deep generative model that can reason about relations in complex dynamics without supervision. In this paper, we take a careful look at this approach for relational inference in multi-agent trajectories. First, we discover that NRI can be fundamentally limited without sufficient long-term observations. Its ability to accurately infer interactions degrades drastically for short output sequences. Next, we consider a more general setting of relational inference when interactions are changing overtime. We propose an extension ofNRI, which we call the DYnamic multi-AgentRelational Inference (DYARI) model that can reason about dynamic relations. We conduct exhaustive experiments to study the effect of model architecture, under-lying dynamics and training scheme on the performance of dynamic relational inference using a simulated physics system. We also showcase the usage of our model on real-world multi-agent basketball trajectories.
DSR: Direct Self-rectification for Uncalibrated Dual-lens Cameras
Sep 26, 2018
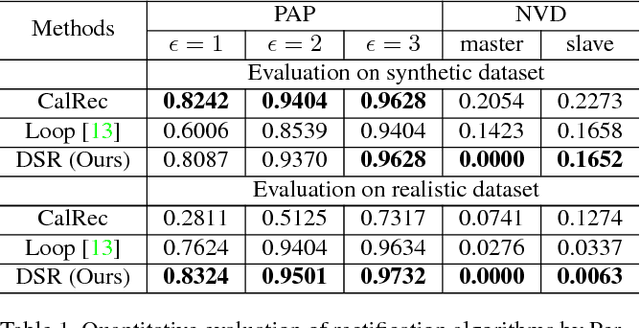


With the developments of dual-lens camera modules,depth information representing the third dimension of thecaptured scenes becomes available for smartphones. It isestimated by stereo matching algorithms, taking as input thetwo views captured by dual-lens cameras at slightly differ-ent viewpoints. Depth-of-field rendering (also be referred toas synthetic defocus or bokeh) is one of the trending depth-based applications. However, to achieve fast depth estima-tion on smartphones, the stereo pairs need to be rectified inthe first place. In this paper, we propose a cost-effective so-lution to perform stereo rectification for dual-lens camerascalled direct self-rectification, short for DSR1. It removesthe need of individual offline calibration for every pair ofdual-lens cameras. In addition, the proposed solution isrobust to the slight movements, e.g., due to collisions, ofthe dual-lens cameras after fabrication. Different with ex-isting self-rectification approaches, our approach computesthe homography in a novel way with zero geometric distor-tions introduced to the master image. It is achieved by di-rectly minimizing the vertical displacements of correspond-ing points between the original master image and the trans-formed slave image. Our method is evaluated on both real-istic and synthetic stereo image pairs, and produces supe-rior results compared to the calibrated rectification or otherself-rectification approaches
Confidence Inference for Focused Learning in Stereo Matching
Sep 25, 2018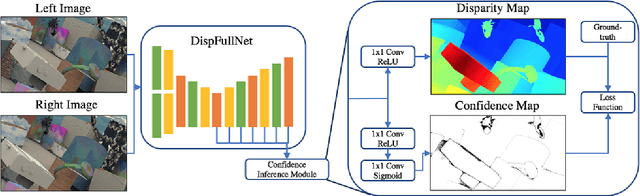
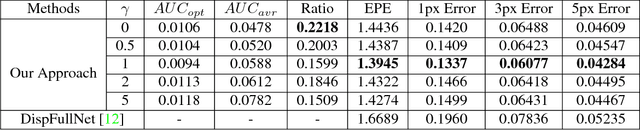
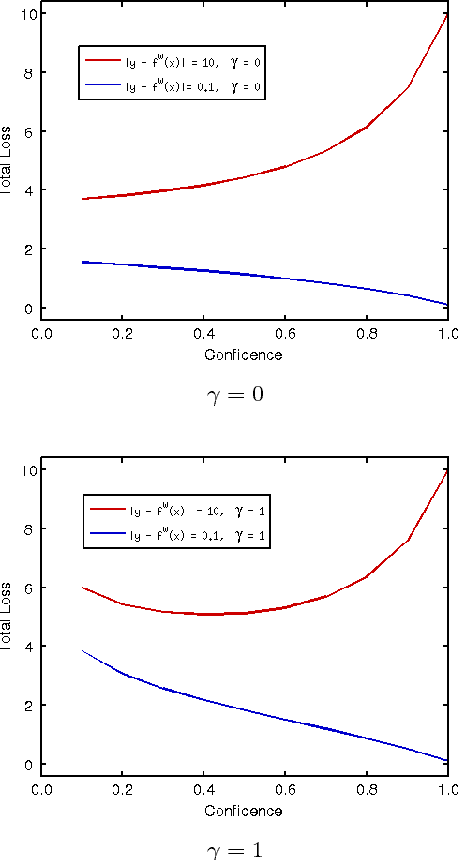

In this paper, we present confidence inference approachin an unsupervised way in stereo matching. Deep Neu-ral Networks (DNNs) have recently been achieving state-of-the-art performance. However, it is often hard to tellwhether the trained model was making sensible predictionsor just guessing at random. To address this problem, westart from a probabilistic interpretation of theL1loss usedin stereo matching, which inherently assumes an indepen-dent and identical (aka i.i.d.) Laplacian distribution. Weshow that with the newly introduced dense confidence map,the identical assumption is relaxed. Intuitively, the vari-ance in the Laplacian distribution is large for low confidentpixels while small for high-confidence pixels. In practice,the network learns toattenuatelow-confidence pixels (e.g.,noisy input, occlusions, featureless regions) andfocusonhigh-confidence pixels. Moreover, it can be observed fromexperiments that the focused learning is very helpful in find-ing a better convergence state of the trained model, reduc-ing over-fitting on a given dataset.
Deep Graph Laplacian Regularization
Jul 31, 2018

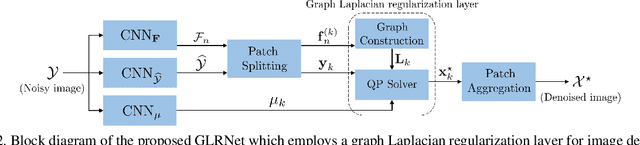
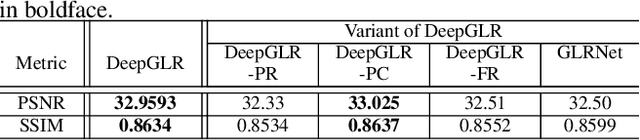
We propose to combine the robustness merit of model-based approaches and the learning power of data-driven approaches for image restoration. Specifically, by integrating graph Laplacian regularization as a trainable module into a deep learning framework, we are less susceptible to overfitting than pure CNN-based approaches, achieving higher robustness to small dataset and cross-domain denoising. First, a sparse neighborhood graph is built from the output of a convolutional neural network (CNN). Then the image is restored by solving an unconstrained quadratic programming problem, using a corresponding graph Laplacian regularizer as a prior term. The proposed restoration pipeline is fully differentiable and hence can be end-to-end trained. Experimental results demonstrate that our work avoids overfitting given small training data. It is also endowed with strong cross-domain generalization power, outperforming the state-of-the-art approaches by remarkable margin.
Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
Mar 18, 2018
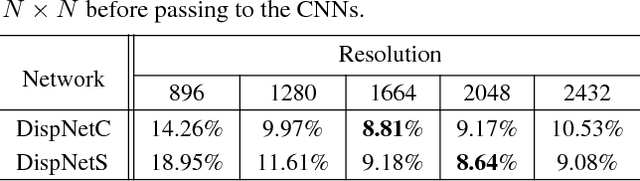
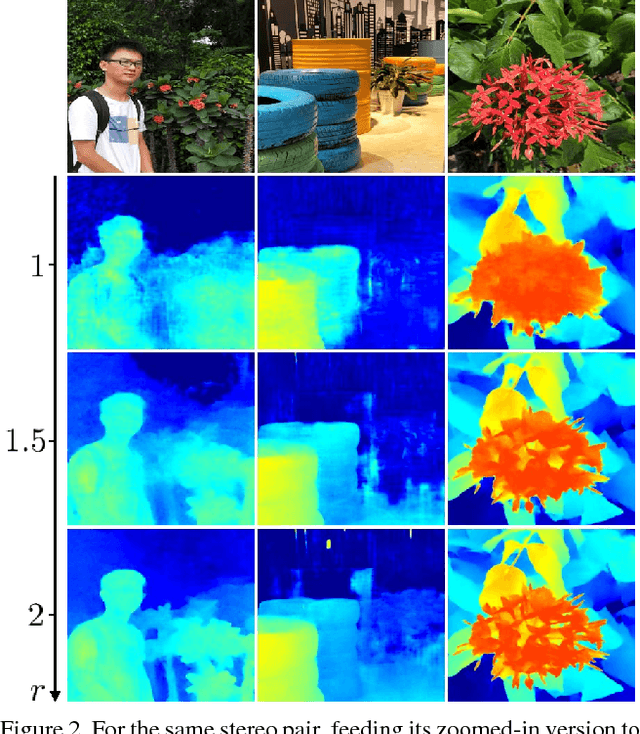

Despite the recent success of stereo matching with convolutional neural networks (CNNs), it remains arduous to generalize a pre-trained deep stereo model to a novel domain. A major difficulty is to collect accurate ground-truth disparities for stereo pairs in the target domain. In this work, we propose a self-adaptation approach for CNN training, utilizing both synthetic training data (with ground-truth disparities) and stereo pairs in the new domain (without ground-truths). Our method is driven by two empirical observations. By feeding real stereo pairs of different domains to stereo models pre-trained with synthetic data, we see that: i) a pre-trained model does not generalize well to the new domain, producing artifacts at boundaries and ill-posed regions; however, ii) feeding an up-sampled stereo pair leads to a disparity map with extra details. To avoid i) while exploiting ii), we formulate an iterative optimization problem with graph Laplacian regularization. At each iteration, the CNN adapts itself better to the new domain: we let the CNN learn its own higher-resolution output; at the meanwhile, a graph Laplacian regularization is imposed to discriminatively keep the desired edges while smoothing out the artifacts. We demonstrate the effectiveness of our method in two domains: daily scenes collected by smartphone cameras, and street views captured in a driving car.