 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Science: Hypothesis Generation Using Structured Paper Data
Apr 17, 2025



Generating novel and creative scientific hypotheses is a cornerstone in achieving Artificial General Intelligence. Large language and reasoning models have the potential to aid in the systematic creation, selection, and validation of scientifically informed hypotheses. However, current foundation models often struggle to produce scientific ideas that are both novel and feasible. One reason is the lack of a dedicated dataset that frames Scientific Hypothesis Generation (SHG) as a Natural Language Generation (NLG) task. In this paper, we introduce HypoGen, the first dataset of approximately 5500 structured problem-hypothesis pairs extracted from top-tier computer science conferences structured with a Bit-Flip-Spark schema, where the Bit is the conventional assumption, the Spark is the key insight or conceptual leap, and the Flip is the resulting counterproposal. HypoGen uniquely integrates an explicit Chain-of-Reasoning component that reflects the intellectual process from Bit to Flip. We demonstrate that framing hypothesis generation as conditional language modelling, with the model fine-tuned on Bit-Flip-Spark and the Chain-of-Reasoning (and where, at inference, we only provide the Bit), leads to improvements in the overall quality of the hypotheses. Our evaluation employs automated metrics and LLM judge rankings for overall quality assessment. We show that by fine-tuning on our HypoGen dataset we improve the novelty, feasibility, and overall quality of the generated hypotheses. The HypoGen dataset is publicly available at huggingface.co/datasets/UniverseTBD/hypogen-dr1.
From superposition to sparse codes: interpretable representations in neural networks
Mar 03, 2025Understanding how information is represented in neural networks is a fundamental challenge in both neuroscience and artificial intelligence. Despite their nonlinear architectures, recent evidence suggests that neural networks encode features in superposition, meaning that input concepts are linearly overlaid within the network's representations. We present a perspective that explains this phenomenon and provides a foundation for extracting interpretable representations from neural activations. Our theoretical framework consists of three steps: (1) Identifiability theory shows that neural networks trained for classification recover latent features up to a linear transformation. (2) Sparse coding methods can extract disentangled features from these representations by leveraging principles from compressed sensing. (3) Quantitative interpretability metrics provide a means to assess the success of these methods, ensuring that extracted features align with human-interpretable concepts. By bridging insights from theoretical neuroscience, representation learning, and interpretability research, we propose an emerging perspective on understanding neural representations in both artificial and biological systems. Our arguments have implications for neural coding theories, AI transparency, and the broader goal of making deep learning models more interpretable.
Self-Attention as a Parametric Endofunctor: A Categorical Framework for Transformer Architectures
Jan 06, 2025
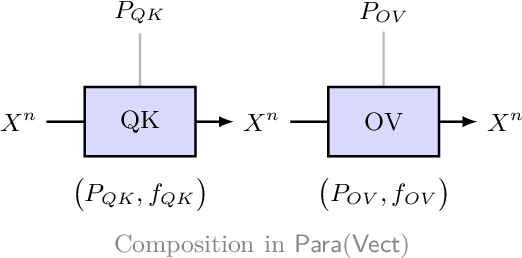
Self-attention mechanisms have revolutionised deep learning architectures, but their mathematical foundations remain incompletely understood. We establish that these mechanisms can be formalised through categorical algebra, presenting a framework that focuses on the linear components of self-attention. We prove that the query, key, and value maps in self-attention naturally form a parametric endofunctor in the 2-category $\mathbf{Para}(\mathbf{Vect})$ of parametric morphisms. We show that stacking multiple self-attention layers corresponds to constructing the free monad on this endofunctor. For positional encodings, we demonstrate that strictly additive position embeddings constitute monoid actions on the embedding space, while standard sinusoidal encodings, though not additive, possess a universal property among faithful position-preserving functors. We establish that the linear portions of self-attention exhibit natural equivariance properties with respect to permutations of input tokens. Finally, we prove that the ``circuits'' identified in mechanistic interpretability correspond precisely to compositions of parametric morphisms in our framework. This categorical perspective unifies geometric, algebraic, and interpretability-based approaches to transformer analysis, while making explicit the mathematical structures underlying attention mechanisms. Our treatment focuses exclusively on linear maps, setting aside nonlinearities like softmax and layer normalisation, which require more sophisticated categorical structures. Our results extend recent work on categorical foundations for deep learning while providing insights into the algebraic structure of attention mechanisms.
Compute Optimal Inference and Provable Amortisation Gap in Sparse Autoencoders
Nov 20, 2024



A recent line of work has shown promise in using sparse autoencoders (SAEs) to uncover interpretable features in neural network representations. However, the simple linear-nonlinear encoding mechanism in SAEs limits their ability to perform accurate sparse inference. In this paper, we investigate sparse inference and learning in SAEs through the lens of sparse coding. Specifically, we show that SAEs perform amortised sparse inference with a computationally restricted encoder and, using compressed sensing theory, we prove that this mapping is inherently insufficient for accurate sparse inference, even in solvable cases. Building on this theory, we empirically explore conditions where more sophisticated sparse inference methods outperform traditional SAE encoders. Our key contribution is the decoupling of the encoding and decoding processes, which allows for a comparison of various sparse encoding strategies. We evaluate these strategies on two dimensions: alignment with true underlying sparse features and correct inference of sparse codes, while also accounting for computational costs during training and inference. Our results reveal that substantial performance gains can be achieved with minimal increases in compute cost. We demonstrate that this generalises to SAEs applied to large language models (LLMs), where advanced encoders achieve similar interpretability. This work opens new avenues for understanding neural network representations and offers important implications for improving the tools we use to analyse the activations of large language models.
Disentangling Dense Embeddings with Sparse Autoencoders
Aug 05, 2024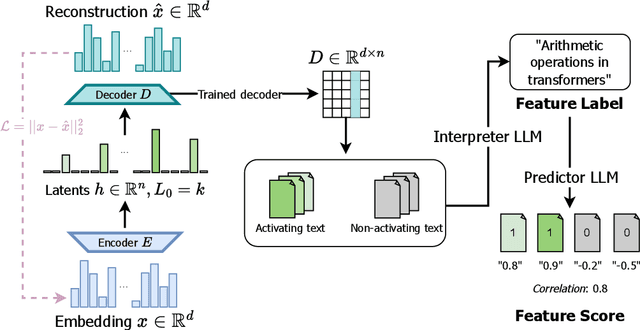
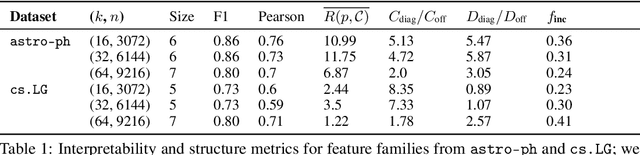
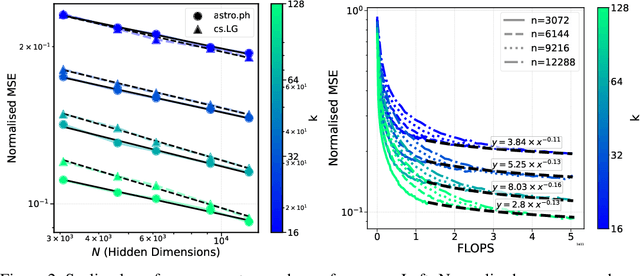
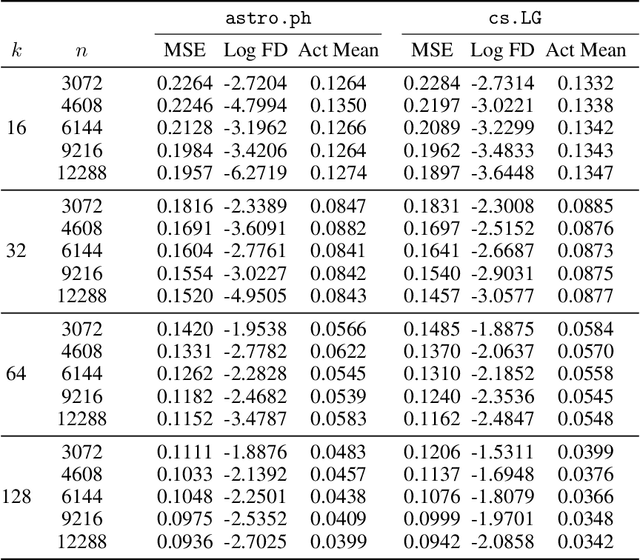
Sparse autoencoders (SAEs) have shown promise in extracting interpretable features from complex neural networks. We present one of the first applications of SAEs to dense text embeddings from large language models, demonstrating their effectiveness in disentangling semantic concepts. By training SAEs on embeddings of over 420,000 scientific paper abstracts from computer science and astronomy, we show that the resulting sparse representations maintain semantic fidelity while offering interpretability. We analyse these learned features, exploring their behaviour across different model capacities and introducing a novel method for identifying ``feature families'' that represent related concepts at varying levels of abstraction. To demonstrate the practical utility of our approach, we show how these interpretable features can be used to precisely steer semantic search, allowing for fine-grained control over query semantics. This work bridges the gap between the semantic richness of dense embeddings and the interpretability of sparse representations. We open source our embeddings, trained sparse autoencoders, and interpreted features, as well as a web app for exploring them.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
Sparse Autoencoders Enable Scalable and Reliable Circuit Identification in Language Models
May 21, 2024This paper introduces an efficient and robust method for discovering interpretable circuits in large language models using discrete sparse autoencoders. Our approach addresses key limitations of existing techniques, namely computational complexity and sensitivity to hyperparameters. We propose training sparse autoencoders on carefully designed positive and negative examples, where the model can only correctly predict the next token for the positive examples. We hypothesise that learned representations of attention head outputs will signal when a head is engaged in specific computations. By discretising the learned representations into integer codes and measuring the overlap between codes unique to positive examples for each head, we enable direct identification of attention heads involved in circuits without the need for expensive ablations or architectural modifications. On three well-studied tasks - indirect object identification, greater-than comparisons, and docstring completion - the proposed method achieves higher precision and recall in recovering ground-truth circuits compared to state-of-the-art baselines, while reducing runtime from hours to seconds. Notably, we require only 5-10 text examples for each task to learn robust representations. Our findings highlight the promise of discrete sparse autoencoders for scalable and efficient mechanistic interpretability, offering a new direction for analysing the inner workings of large language models.
Measuring Sharpness in Grokking
Feb 14, 2024Neural networks sometimes exhibit grokking, a phenomenon where perfect or near-perfect performance is achieved on a validation set well after the same performance has been obtained on the corresponding training set. In this workshop paper, we introduce a robust technique for measuring grokking, based on fitting an appropriate functional form. We then use this to investigate the sharpness of transitions in training and validation accuracy under two settings. The first setting is the theoretical framework developed by Levi et al. (2023) where closed form expressions are readily accessible. The second setting is a two-layer MLP trained to predict the parity of bits, with grokking induced by the concealment strategy of Miller et al. (2023). We find that trends between relative grokking gap and grokking sharpness are similar in both settings when using absolute and relative measures of sharpness. Reflecting on this, we make progress toward explaining some trends and identify the need for further study to untangle the various mechanisms which influence the sharpness of grokking.
Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity
Oct 26, 2023



In some settings neural networks exhibit a phenomenon known as grokking, where they achieve perfect or near-perfect accuracy on the validation set long after the same performance has been achieved on the training set. In this paper, we discover that grokking is not limited to neural networks but occurs in other settings such as Gaussian process (GP) classification, GP regression and linear regression. We also uncover a mechanism by which to induce grokking on algorithmic datasets via the addition of dimensions containing spurious information. The presence of the phenomenon in non-neural architectures provides evidence that grokking is not specific to SGD or weight norm regularisation. Instead, grokking may be possible in any setting where solution search is guided by complexity and error. Based on this insight and further trends we see in the training trajectories of a Bayesian neural network (BNN) and GP regression model, we make progress towards a more general theory of grokking. Specifically, we hypothesise that the phenomenon is governed by the accessibility of certain regions in the error and complexity landscapes.