 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle and Semantic Consistent Adversarial Domain Adaptation for Reducing Simulation-to-Real Domain Shift in LiDAR Bird's Eye View
Apr 22, 2021
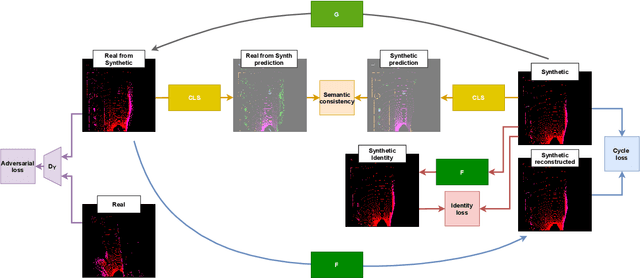
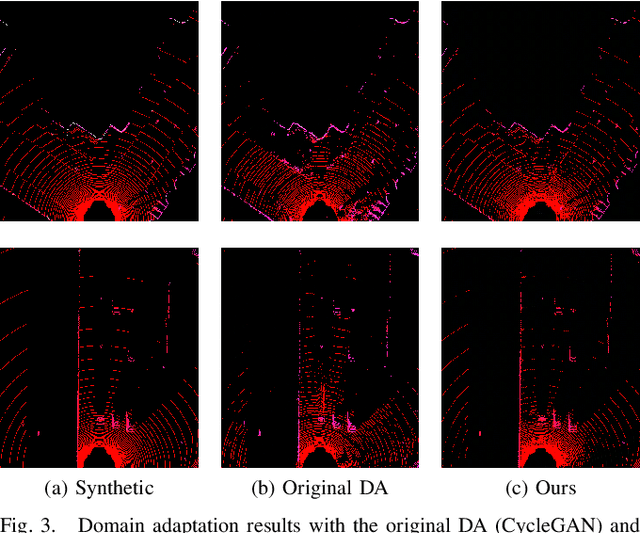

The performance of object detection methods based on LiDAR information is heavily impacted by the availability of training data, usually limited to certain laser devices. As a result, the use of synthetic data is becoming popular when training neural network models, as both sensor specifications and driving scenarios can be generated ad-hoc. However, bridging the gap between virtual and real environments is still an open challenge, as current simulators cannot completely mimic real LiDAR operation. To tackle this issue, domain adaptation strategies are usually applied, obtaining remarkable results on vehicle detection when applied to range view (RV) and bird's eye view (BEV) projections while failing for smaller road agents. In this paper, we present a BEV domain adaptation method based on CycleGAN that uses prior semantic classification in order to preserve the information of small objects of interest during the domain adaptation process. The quality of the generated BEVs has been evaluated using a state-of-the-art 3D object detection framework at KITTI 3D Object Detection Benchmark. The obtained results show the advantages of the proposed method over the existing alternatives.
Automatic Extrinsic Calibration Method for LiDAR and Camera Sensor Setups
Jan 12, 2021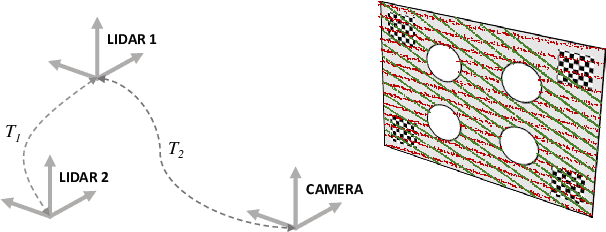



Most sensor setups for onboard autonomous perception are composed of LiDARs and vision systems, as they provide complementary information that improves the reliability of the different algorithms necessary to obtain a robust scene understanding. However, the effective use of information from different sources requires an accurate calibration between the sensors involved, which usually implies a tedious and burdensome process. We present a method to calibrate the extrinsic parameters of any pair of sensors involving LiDARs, monocular or stereo cameras, of the same or different modalities. The procedure is composed of two stages: first, reference points belonging to a custom calibration target are extracted from the data provided by the sensors to be calibrated, and second, the optimal rigid transformation is found through the registration of both point sets. The proposed approach can handle devices with very different resolutions and poses, as usually found in vehicle setups. In order to assess the performance of the proposed method, a novel evaluation suite built on top of a popular simulation framework is introduced. Experiments on the synthetic environment show that our calibration algorithm significantly outperforms existing methods, whereas real data tests corroborate the results obtained in the evaluation suite. Open-source code is available at https://github.com/beltransen/velo2cam_calibration
Towards Autonomous Driving: a Multi-Modal 360$^{\circ}$ Perception Proposal
Aug 21, 2020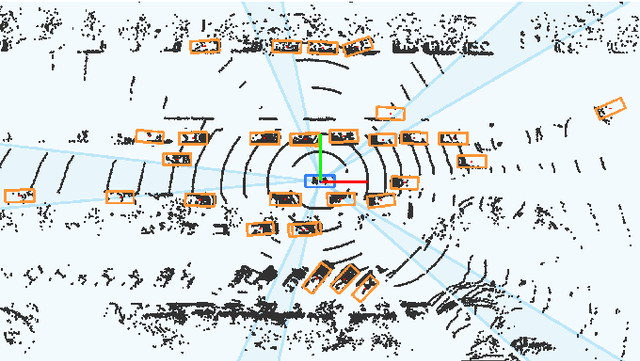
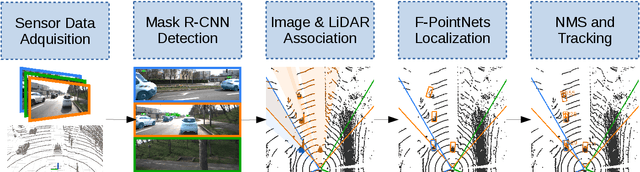
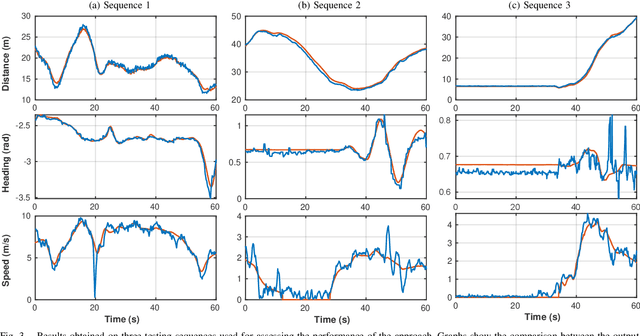
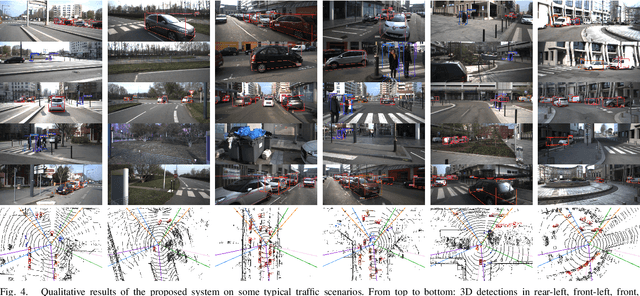
In this paper, a multi-modal 360$^{\circ}$ framework for 3D object detection and tracking for autonomous vehicles is presented. The process is divided into four main stages. First, images are fed into a CNN network to obtain instance segmentation of the surrounding road participants. Second, LiDAR-to-image association is performed for the estimated mask proposals. Then, the isolated points of every object are processed by a PointNet ensemble to compute their corresponding 3D bounding boxes and poses. Lastly, a tracking stage based on Unscented Kalman Filter is used to track the agents along time. The solution, based on a novel sensor fusion configuration, provides accurate and reliable road environment detection. A wide variety of tests of the system, deployed in an autonomous vehicle, have successfully assessed the suitability of the proposed perception stack in a real autonomous driving application.
BirdNet+: End-to-End 3D Object Detection in LiDAR Bird's Eye View
Mar 09, 2020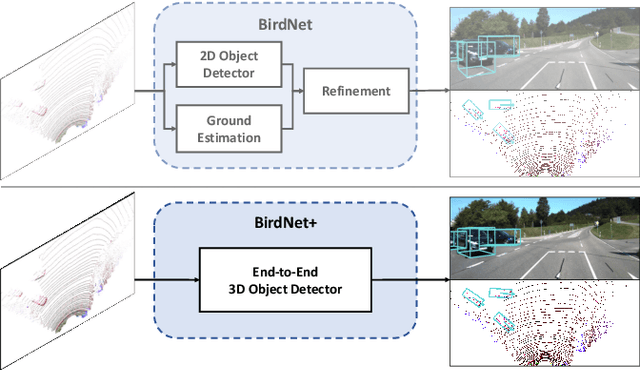
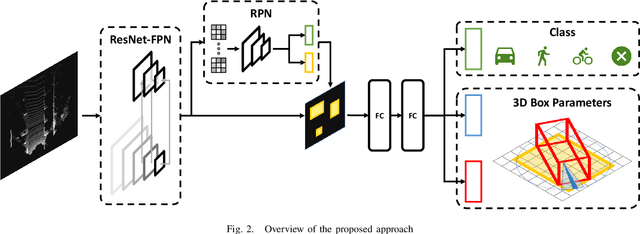
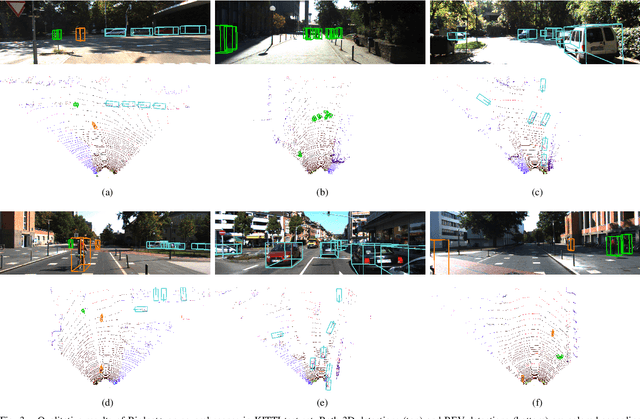
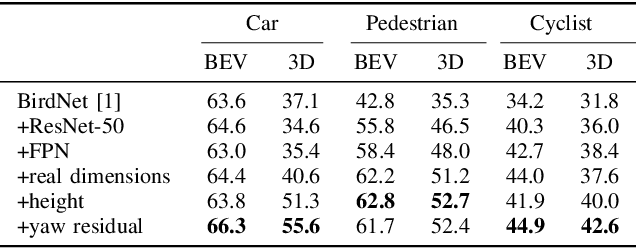
On-board 3D object detection in autonomous vehicles often relies on geometry information captured by LiDAR devices. Albeit image features are typically preferred for detection, numerous approaches take only spatial data as input. Exploiting this information in inference usually involves the use of compact representations such as the Bird's Eye View (BEV) projection, which entails a loss of information and thus hinders the joint inference of all the parameters of the objects' 3D boxes. In this paper, we present a fully end-to-end 3D object detection framework that can infer oriented 3D boxes solely from BEV images by using a two-stage object detector and ad-hoc regression branches, eliminating the need for a post-processing stage. The method outperforms its predecessor (BirdNet) by a large margin and obtains state-of-the-art results on the KITTI 3D Object Detection Benchmark for all the categories in evaluation.
BirdNet: a 3D Object Detection Framework from LiDAR information
May 03, 2018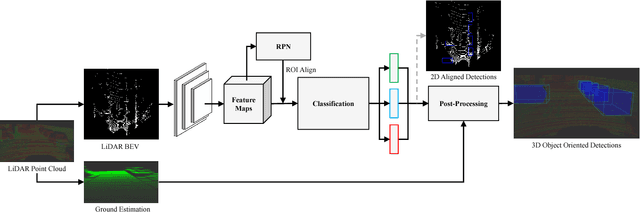
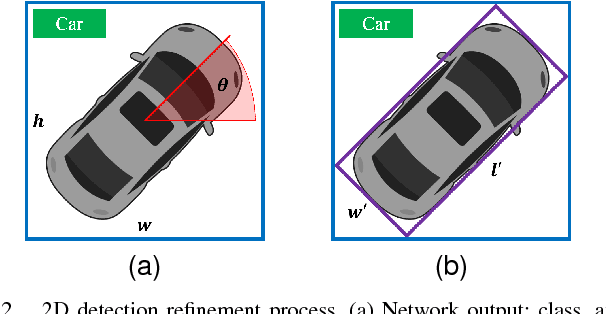
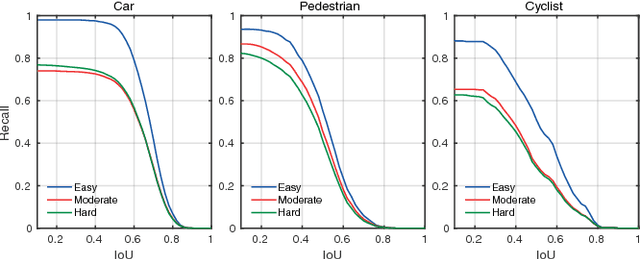

Understanding driving situations regardless the conditions of the traffic scene is a cornerstone on the path towards autonomous vehicles; however, despite common sensor setups already include complementary devices such as LiDAR or radar, most of the research on perception systems has traditionally focused on computer vision. We present a LiDAR-based 3D object detection pipeline entailing three stages. First, laser information is projected into a novel cell encoding for bird's eye view projection. Later, both object location on the plane and its heading are estimated through a convolutional neural network originally designed for image processing. Finally, 3D oriented detections are computed in a post-processing phase. Experiments on KITTI dataset show that the proposed framework achieves state-of-the-art results among comparable methods. Further tests with different LiDAR sensors in real scenarios assess the multi-device capabilities of the approach.
Automatic Extrinsic Calibration for Lidar-Stereo Vehicle Sensor Setups
Jul 27, 2017



Sensor setups consisting of a combination of 3D range scanner lasers and stereo vision systems are becoming a popular choice for on-board perception systems in vehicles; however, the combined use of both sources of information implies a tedious calibration process. We present a method for extrinsic calibration of lidar-stereo camera pairs without user intervention. Our calibration approach is aimed to cope with the constraints commonly found in automotive setups, such as low-resolution and specific sensor poses. To demonstrate the performance of our method, we also introduce a novel approach for the quantitative assessment of the calibration results, based on a simulation environment. Tests using real devices have been conducted as well, proving the usability of the system and the improvement over the existing approaches. Code is available at http://wiki.ros.org/velo2cam_calibration