 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Pedestrian Group Walking Event Detection Using Spectral Analysis of Motion Similarity Graph
Sep 03, 2019

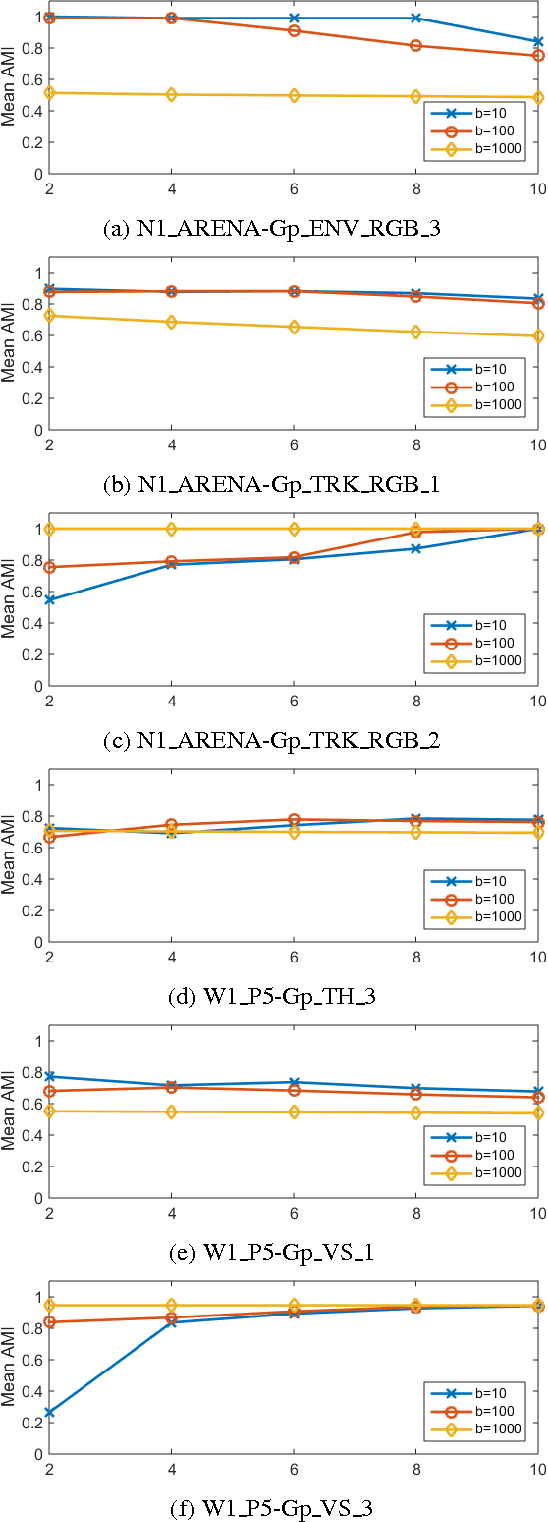
A method for online identification of group of moving objects in the video is proposed in this paper. This method at each frame identifies group of tracked objects with similar local instantaneous motion pattern using spectral clustering on motion similarity graph. Then, the output of the algorithm is used to detect the event of more than two object moving together as required by PETS2015 challenge. The performance of the algorithm is evaluated on the PETS2015 dataset.
Hierarchy of GANs for learning embodied self-awareness model
Jun 08, 2018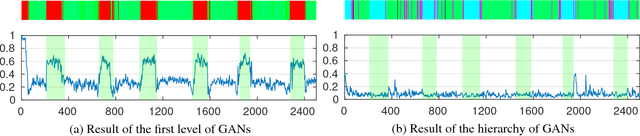


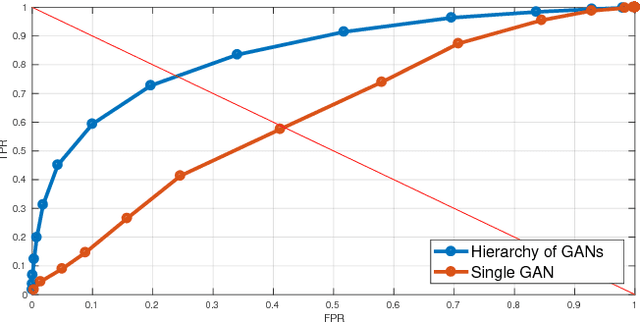
In recent years several architectures have been proposed to learn embodied agents complex self-awareness models. In this paper, dynamic incremental self-awareness (SA) models are proposed that allow experiences done by an agent to be modeled in a hierarchical fashion, starting from more simple situations to more structured ones. Each situation is learned from subsets of private agent perception data as a model capable to predict normal behaviors and detect abnormalities. Hierarchical SA models have been already proposed using low dimensional sensorial inputs. In this work, a hierarchical model is introduced by means of a cross-modal Generative Adversarial Networks (GANs) processing high dimensional visual data. Different levels of the GANs are detected in a self-supervised manner using GANs discriminators decision boundaries. Real experiments on semi-autonomous ground vehicles are presented.
Learning Multi-Modal Self-Awareness Models for Autonomous Vehicles from Human Driving
Jun 07, 2018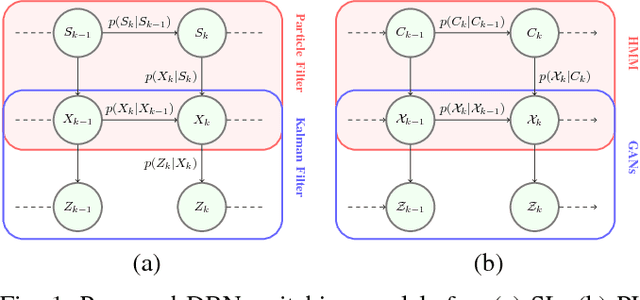
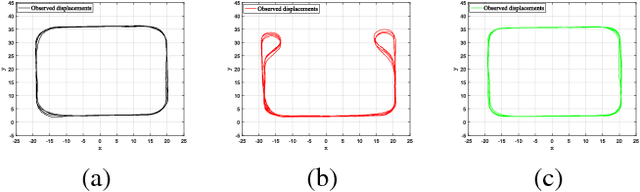
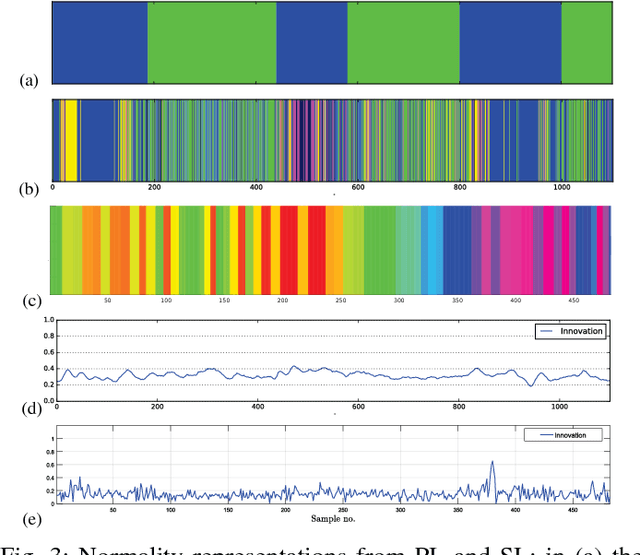
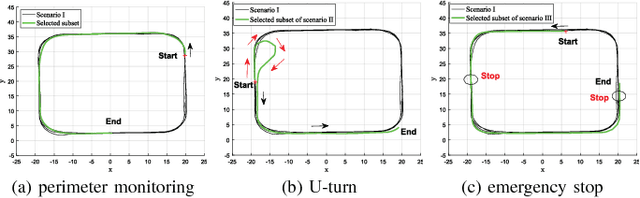
This paper presents a novel approach for learning self-awareness models for autonomous vehicles. The proposed technique is based on the availability of synchronized multi-sensor dynamic data related to different maneuvering tasks performed by a human operator. It is shown that different machine learning approaches can be used to first learn single modality models using coupled Dynamic Bayesian Networks; such models are then correlated at event level to discover contextual multi-modal concepts. In the presented case, visual perception and localization are used as modalities. Cross-correlations among modalities in time is discovered from data and are described as probabilistic links connecting shared and private multi-modal DBNs at the event (discrete) level. Results are presented on experiments performed on an autonomous vehicle, highlighting potentiality of the proposed approach to allow anomaly detection and autonomous decision making based on learned self-awareness models.
A Multi-perspective Approach To Anomaly Detection For Self-aware Embodied Agents
Mar 17, 2018
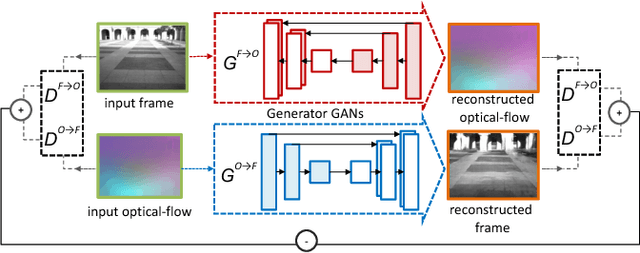

This paper focuses on multi-sensor anomaly detection for moving cognitive agents using both external and private first-person visual observations. Both observation types are used to characterize agents' motion in a given environment. The proposed method generates locally uniform motion models by dividing a Gaussian process that approximates agents' displacements on the scene and provides a Shared Level (SL) self-awareness based on Environment Centered (EC) models. Such models are then used to train in a semi-unsupervised way a set of Generative Adversarial Networks (GANs) that produce an estimation of external and internal parameters of moving agents. Obtained results exemplify the feasibility of using multi-perspective data for predicting and analyzing trajectory information.
The Evolution of First Person Vision Methods: A Survey
Apr 03, 2015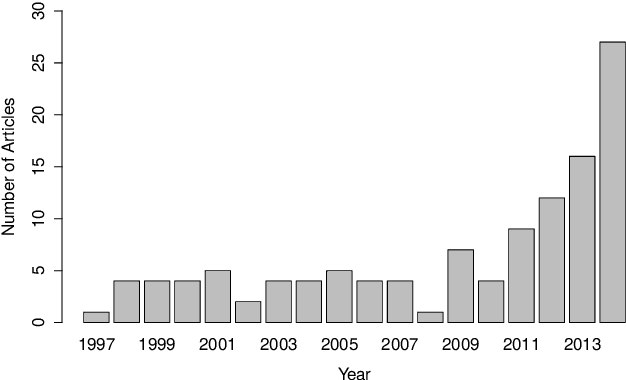
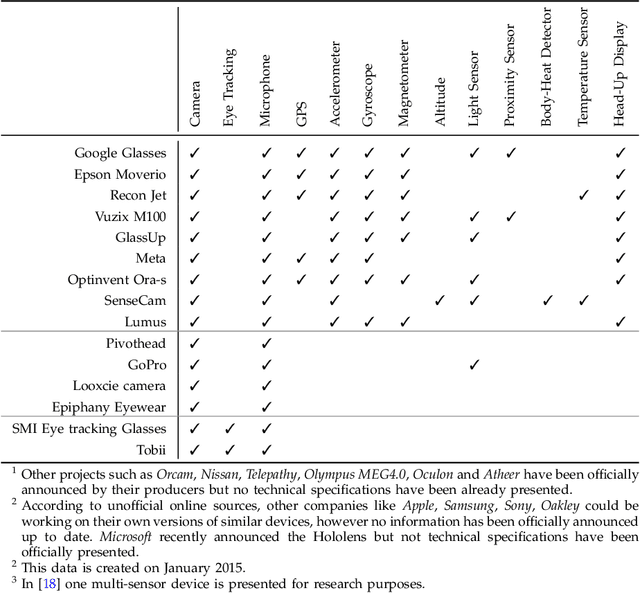
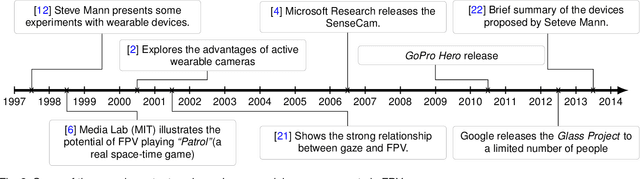
The emergence of new wearable technologies such as action cameras and smart-glasses has increased the interest of computer vision scientists in the First Person perspective. Nowadays, this field is attracting attention and investments of companies aiming to develop commercial devices with First Person Vision recording capabilities. Due to this interest, an increasing demand of methods to process these videos, possibly in real-time, is expected. Current approaches present a particular combinations of different image features and quantitative methods to accomplish specific objectives like object detection, activity recognition, user machine interaction and so on. This paper summarizes the evolution of the state of the art in First Person Vision video analysis between 1997 and 2014, highlighting, among others, most commonly used features, methods, challenges and opportunities within the field.
* First Person Vision, Egocentric Vision, Wearable Devices, Smart Glasses, Computer Vision, Video Analytics, Human-machine Interaction