 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Understanding of Location and Illumination Changes in Egocentric Videos
Mar 27, 2017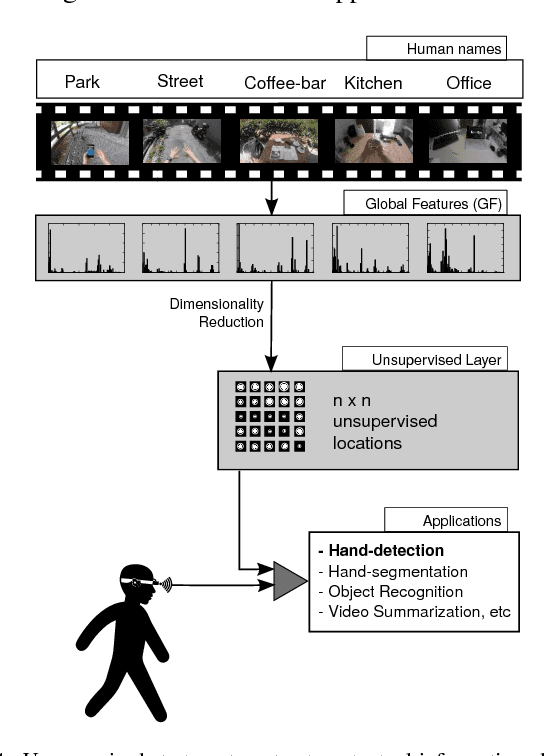
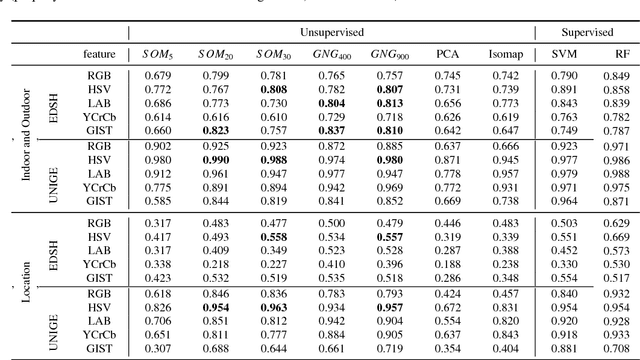
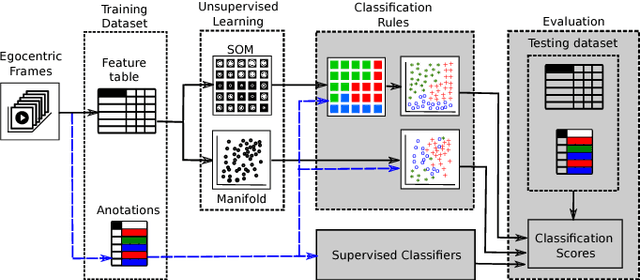
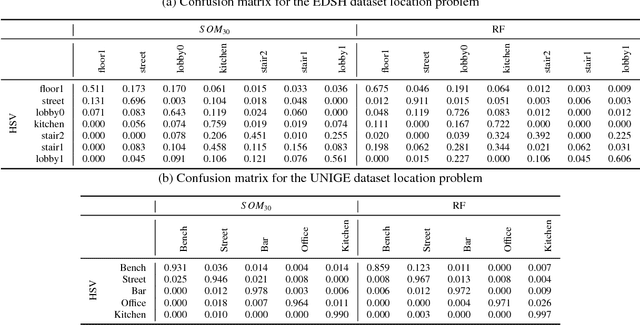
Wearable cameras stand out as one of the most promising devices for the upcoming years, and as a consequence, the demand of computer algorithms to automatically understand the videos recorded with them is increasing quickly. An automatic understanding of these videos is not an easy task, and its mobile nature implies important challenges to be faced, such as the changing light conditions and the unrestricted locations recorded. This paper proposes an unsupervised strategy based on global features and manifold learning to endow wearable cameras with contextual information regarding the light conditions and the location captured. Results show that non-linear manifold methods can capture contextual patterns from global features without compromising large computational resources. The proposed strategy is used, as an application case, as a switching mechanism to improve the hand-detection problem in egocentric videos.
Left/Right Hand Segmentation in Egocentric Videos
Jul 21, 2016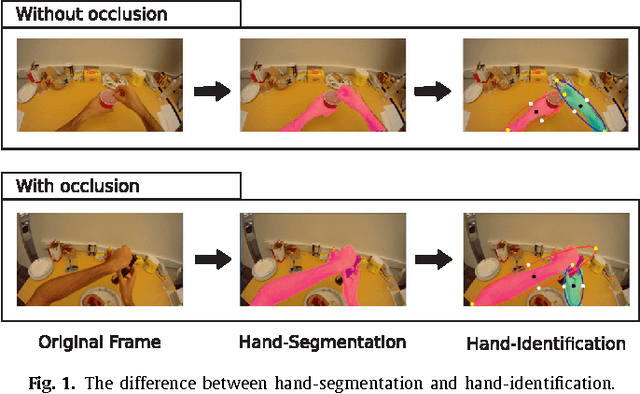
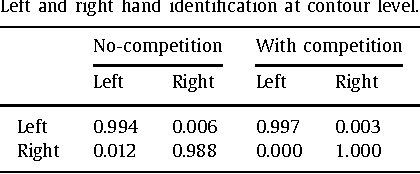


Wearable cameras allow people to record their daily activities from a user-centered (First Person Vision) perspective. Due to their favorable location, wearable cameras frequently capture the hands of the user, and may thus represent a promising user-machine interaction tool for different applications. Existent First Person Vision methods handle hand segmentation as a background-foreground problem, ignoring two important facts: i) hands are not a single "skin-like" moving element, but a pair of interacting cooperative entities, ii) close hand interactions may lead to hand-to-hand occlusions and, as a consequence, create a single hand-like segment. These facts complicate a proper understanding of hand movements and interactions. Our approach extends traditional background-foreground strategies, by including a hand-identification step (left-right) based on a Maxwell distribution of angle and position. Hand-to-hand occlusions are addressed by exploiting temporal superpixels. The experimental results show that, in addition to a reliable left/right hand-segmentation, our approach considerably improves the traditional background-foreground hand-segmentation.
The Evolution of First Person Vision Methods: A Survey
Apr 03, 2015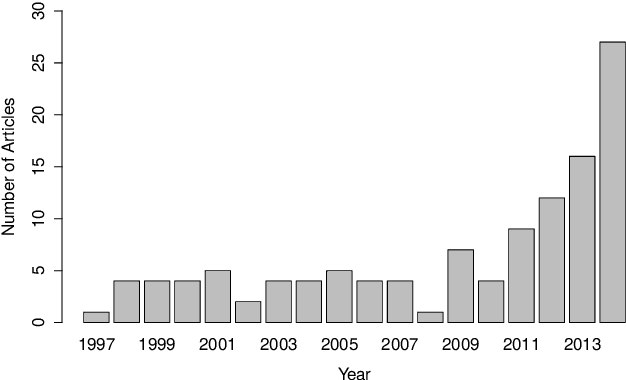
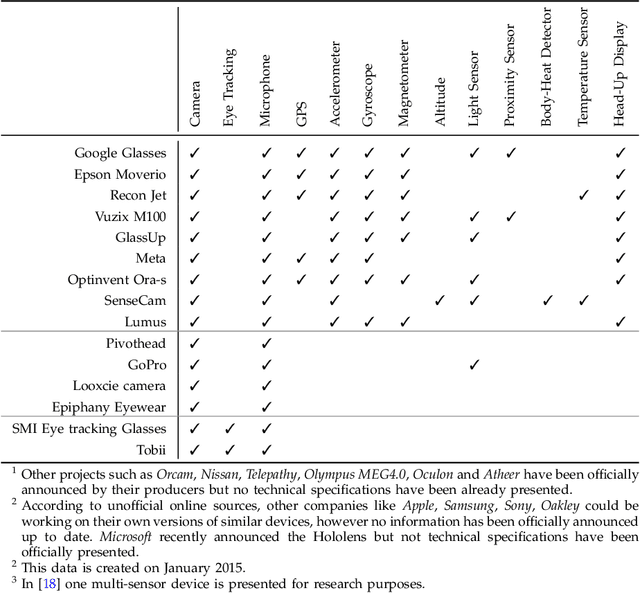
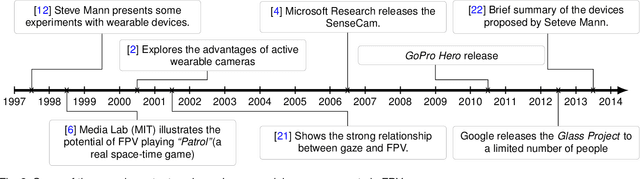
The emergence of new wearable technologies such as action cameras and smart-glasses has increased the interest of computer vision scientists in the First Person perspective. Nowadays, this field is attracting attention and investments of companies aiming to develop commercial devices with First Person Vision recording capabilities. Due to this interest, an increasing demand of methods to process these videos, possibly in real-time, is expected. Current approaches present a particular combinations of different image features and quantitative methods to accomplish specific objectives like object detection, activity recognition, user machine interaction and so on. This paper summarizes the evolution of the state of the art in First Person Vision video analysis between 1997 and 2014, highlighting, among others, most commonly used features, methods, challenges and opportunities within the field.
* First Person Vision, Egocentric Vision, Wearable Devices, Smart Glasses, Computer Vision, Video Analytics, Human-machine Interaction