 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chef's Hat Simulation Environment for Reinforcement-Learning-Based Agents
Mar 12, 2020

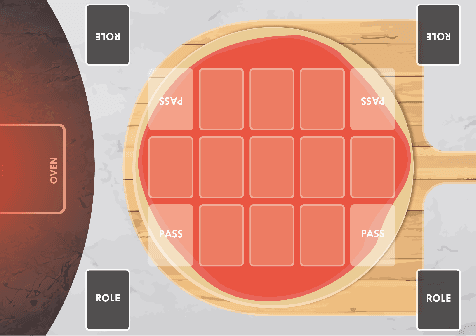
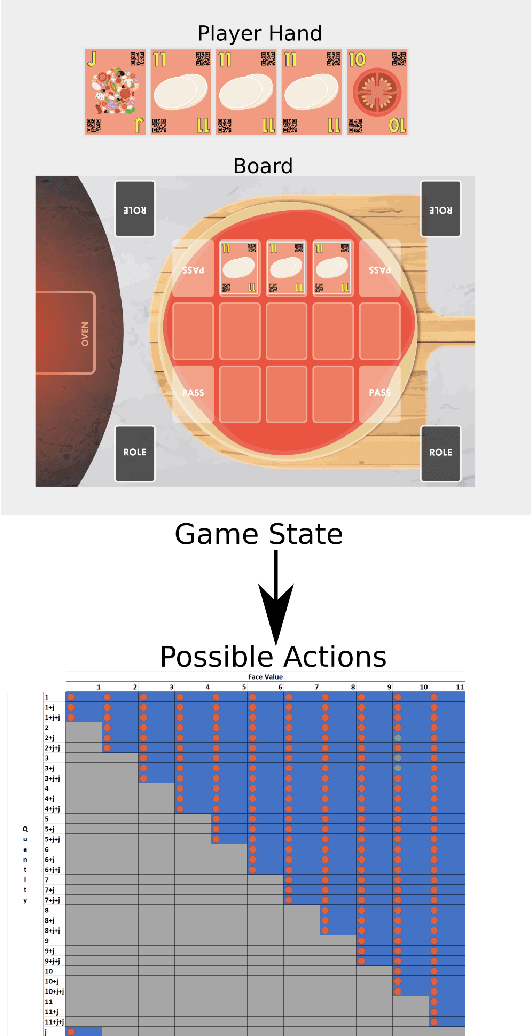
To achieve social interactions within Human-Robot Interaction (HRI) environments is a very challenging task. Most of the current research focuses on Wizard-of-Oz approaches, which neglect the recent development of intelligent robots. On the other hand, real-world scenarios usually do not provide the necessary control and reproducibility which are needed for learning algorithms. In this paper, we propose a virtual simulation environment that implements the Chef's Hat card game, designed to be used in HRI scenarios, to provide a controllable and reproducible scenario for reinforcement-learning algorithms.
A Deep Neural Model Of Emotion Appraisal
Aug 01, 2018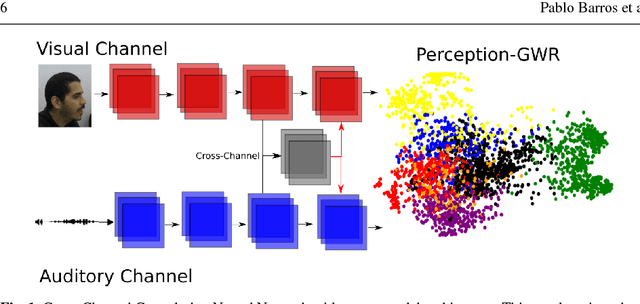
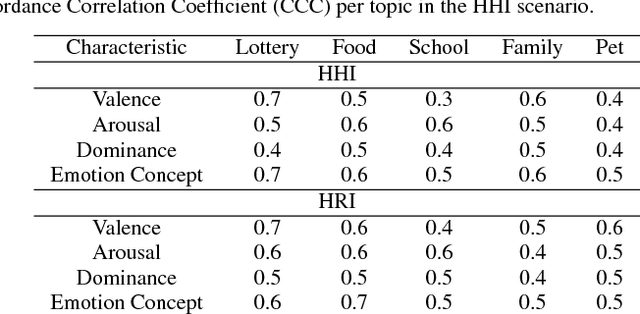
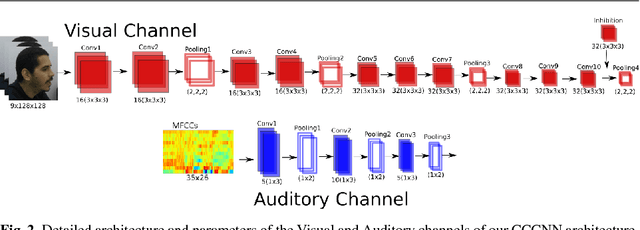
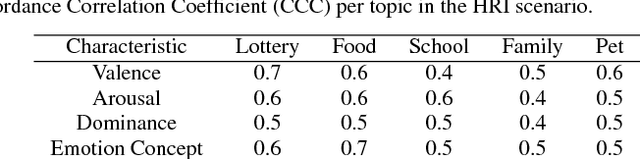
Emotional concepts play a huge role in our daily life since they take part into many cognitive processes: from the perception of the environment around us to different learning processes and natural communication. Social robots need to communicate with humans, which increased also the popularity of affective embodied models that adopt different emotional concepts in many everyday tasks. However, there is still a gap between the development of these solutions and the integration and development of a complex emotion appraisal system, which is much necessary for true social robots. In this paper, we propose a deep neural model which is designed in the light of different aspects of developmental learning of emotional concepts to provide an integrated solution for internal and external emotion appraisal. We evaluate the performance of the proposed model with different challenging corpora and compare it with state-of-the-art models for external emotion appraisal. To extend the evaluation of the proposed model, we designed and collected a novel dataset based on a Human-Robot Interaction (HRI) scenario. We deployed the model in an iCub robot and evaluated the capability of the robot to learn and describe the affective behavior of different persons based on observation. The performed experiments demonstrate that the proposed model is competitive with the state of the art in describing emotion behavior in general. In addition, it is able to generate internal emotional concepts that evolve through time: it continuously forms and updates the formed emotional concepts, which is a step towards creating an emotional appraisal model grounded in the robot experiences.
Unsupervised Understanding of Location and Illumination Changes in Egocentric Videos
Mar 27, 2017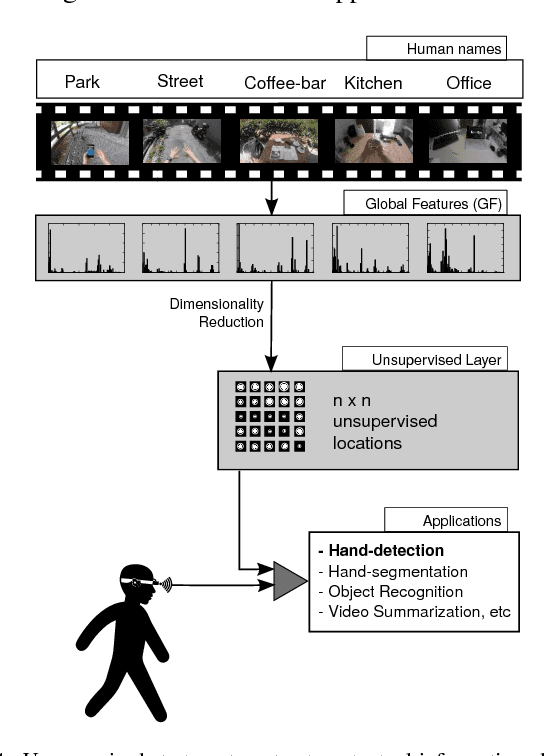
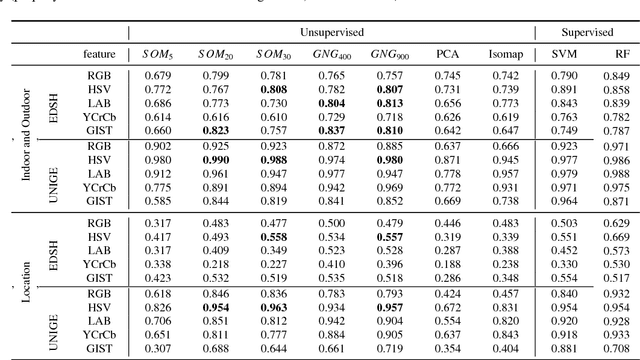
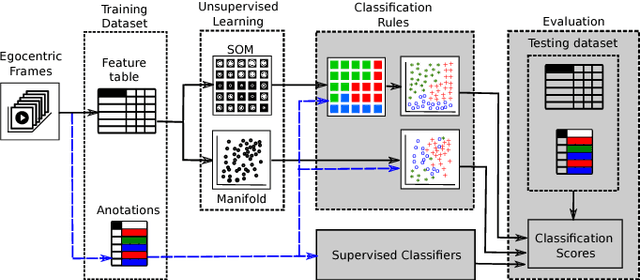
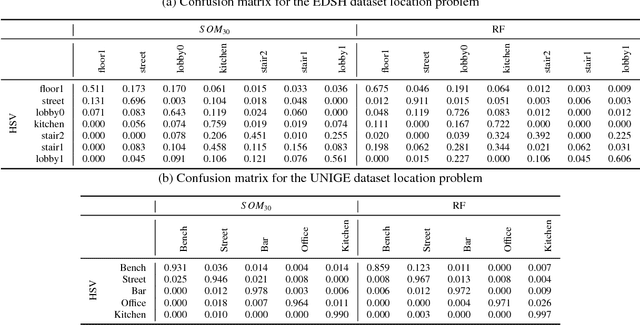
Wearable cameras stand out as one of the most promising devices for the upcoming years, and as a consequence, the demand of computer algorithms to automatically understand the videos recorded with them is increasing quickly. An automatic understanding of these videos is not an easy task, and its mobile nature implies important challenges to be faced, such as the changing light conditions and the unrestricted locations recorded. This paper proposes an unsupervised strategy based on global features and manifold learning to endow wearable cameras with contextual information regarding the light conditions and the location captured. Results show that non-linear manifold methods can capture contextual patterns from global features without compromising large computational resources. The proposed strategy is used, as an application case, as a switching mechanism to improve the hand-detection problem in egocentric videos.
Left/Right Hand Segmentation in Egocentric Videos
Jul 21, 2016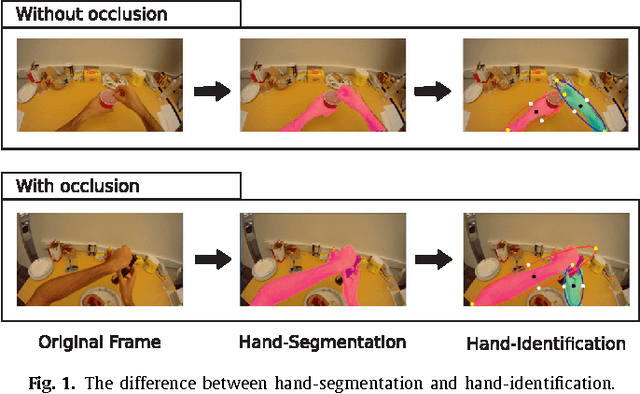
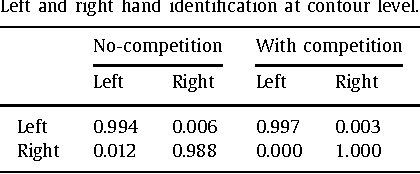


Wearable cameras allow people to record their daily activities from a user-centered (First Person Vision) perspective. Due to their favorable location, wearable cameras frequently capture the hands of the user, and may thus represent a promising user-machine interaction tool for different applications. Existent First Person Vision methods handle hand segmentation as a background-foreground problem, ignoring two important facts: i) hands are not a single "skin-like" moving element, but a pair of interacting cooperative entities, ii) close hand interactions may lead to hand-to-hand occlusions and, as a consequence, create a single hand-like segment. These facts complicate a proper understanding of hand movements and interactions. Our approach extends traditional background-foreground strategies, by including a hand-identification step (left-right) based on a Maxwell distribution of angle and position. Hand-to-hand occlusions are addressed by exploiting temporal superpixels. The experimental results show that, in addition to a reliable left/right hand-segmentation, our approach considerably improves the traditional background-foreground hand-segmentation.