 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework to compare music generative models using automatic evaluation metrics extended to rhythm
Jan 19, 2021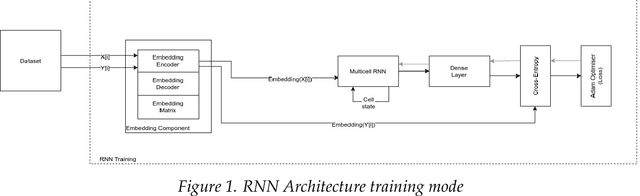
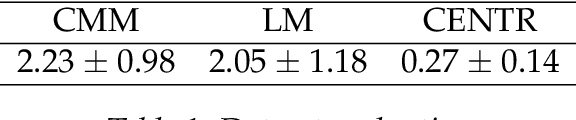
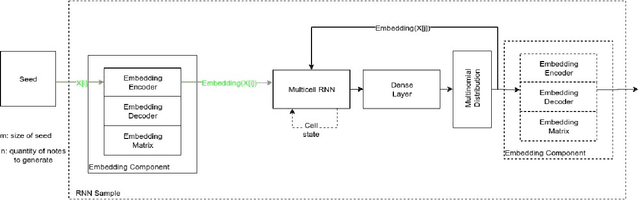

To train a machine learning model is necessary to take numerous decisions about many options for each process involved, in the field of sequence generation and more specifically of music composition, the nature of the problem helps to narrow the options but at the same time, some other options appear for specific challenges. This paper takes the framework proposed in a previous research that did not consider rhythm to make a series of design decisions, then, rhythm support is added to evaluate the performance of two RNN memory cells in the creation of monophonic music. The model considers the handling of music transposition and the framework evaluates the quality of the generated pieces using automatic quantitative metrics based on geometry which have rhythm support added as well.
Sequence Generation using Deep Recurrent Networks and Embeddings: A study case in music
Dec 02, 2020



Automatic generation of sequences has been a highly explored field in the last years. In particular, natural language processing and automatic music composition have gained importance due to the recent advances in machine learning and Neural Networks with intrinsic memory mechanisms such as Recurrent Neural Networks. This paper evaluates different types of memory mechanisms (memory cells) and analyses their performance in the field of music composition. The proposed approach considers music theory concepts such as transposition, and uses data transformations (embeddings) to introduce semantic meaning and improve the quality of the generated melodies. A set of quantitative metrics is presented to evaluate the performance of the proposed architecture automatically, measuring the tonality of the musical compositions.
Egoshots, an ego-vision life-logging dataset and semantic fidelity metric to evaluate diversity in image captioning models
Mar 27, 2020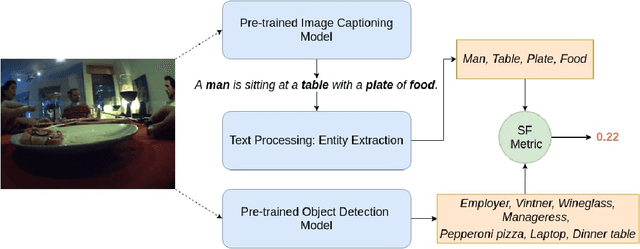

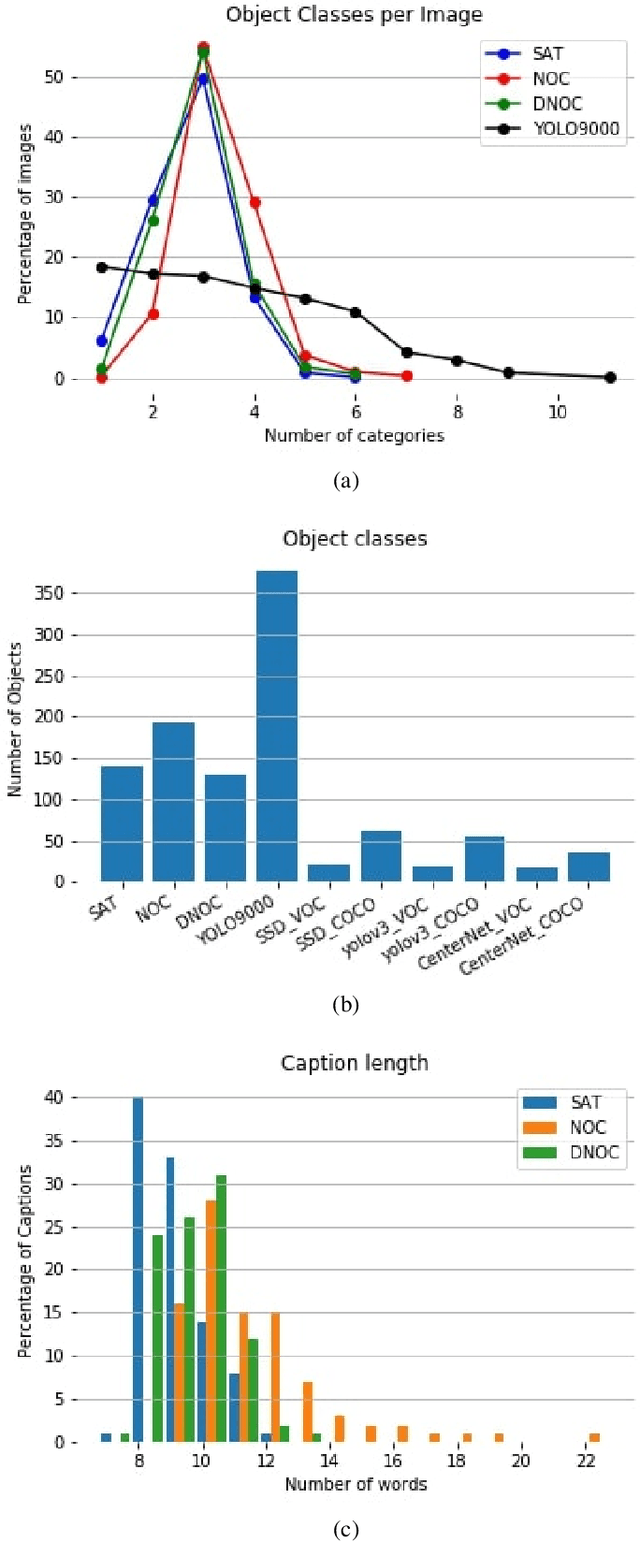
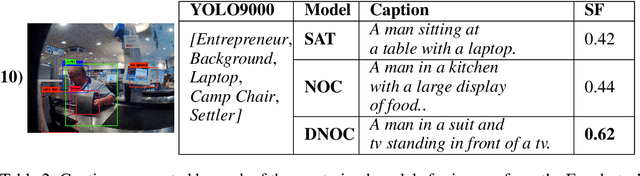
Image captioning models have been able to generate grammatically correct and human understandable sentences. However most of the captions convey limited information as the model used is trained on datasets that do not caption all possible objects existing in everyday life. Due to this lack of prior information most of the captions are biased to only a few objects present in the scene, hence limiting their usage in daily life. In this paper, we attempt to show the biased nature of the currently existing image captioning models and present a new image captioning dataset, Egoshots, consisting of 978 real life images with no captions. We further exploit the state of the art pre-trained image captioning and object recognition networks to annotate our images and show the limitations of existing works. Furthermore, in order to evaluate the quality of the generated captions, we propose a new image captioning metric, object based Semantic Fidelity (SF). Existing image captioning metrics can evaluate a caption only in the presence of their corresponding annotations; however, SF allows evaluating captions generated for images without annotations, making it highly useful for real life generated captions.
Static force field representation of environments based on agents nonlinear motions
Sep 09, 2019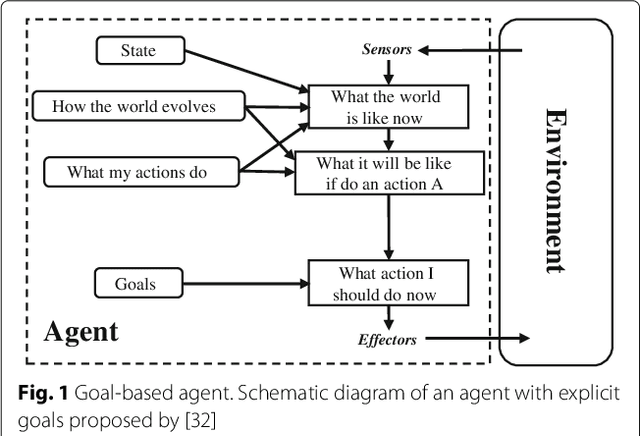
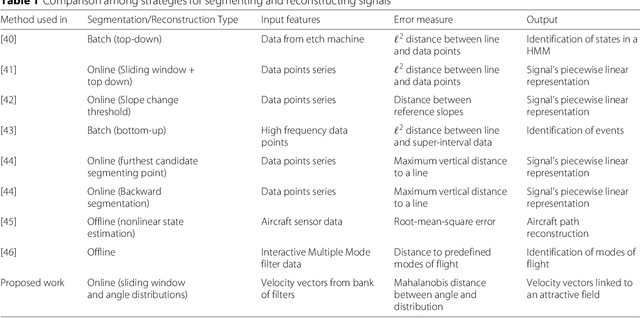
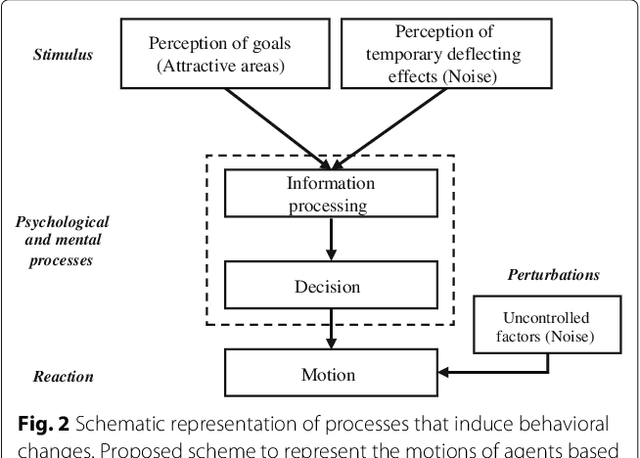
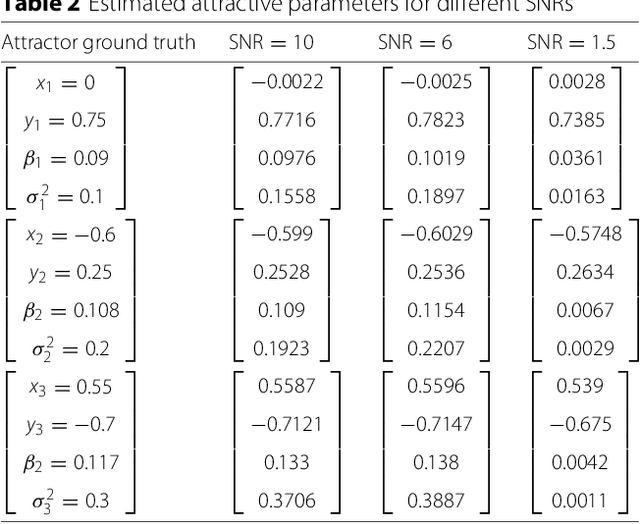
This paper presents a methodology that aims at the incremental representation of areas inside environments in terms of attractive forces. It is proposed a parametric representation of velocity fields ruling the dynamics of moving agents. It is assumed that attractive spots in the environment are responsible for modifying the motion of agents. A switching model is used to describe near and far velocity fields, which in turn are used to learn attractive characteristics of environments. The effect of such areas is considered radial over all the scene. Based on the estimation of attractive areas, a map that describes their effects in terms of their localizations, ranges of action, and intensities is derived in an online way. Information of static attractive areas is added dynamically into a set of filters that describes possible interactions between moving agents and an environment. The proposed approach is first evaluated on synthetic data; posteriorly, the method is applied on real trajectories coming from moving pedestrians in an indoor environment.
Unsupervised Understanding of Location and Illumination Changes in Egocentric Videos
Mar 27, 2017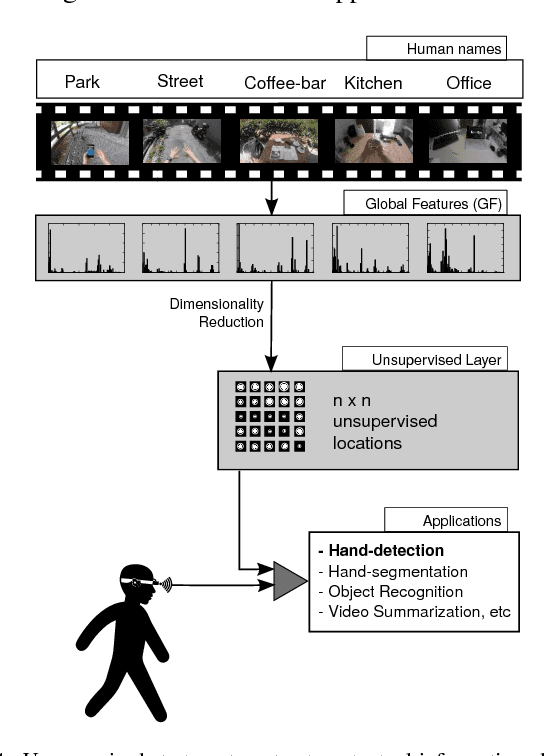
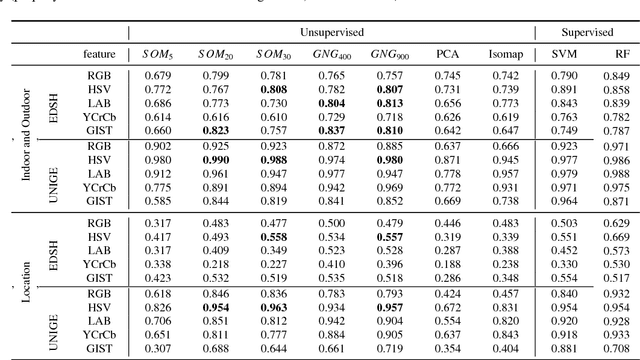
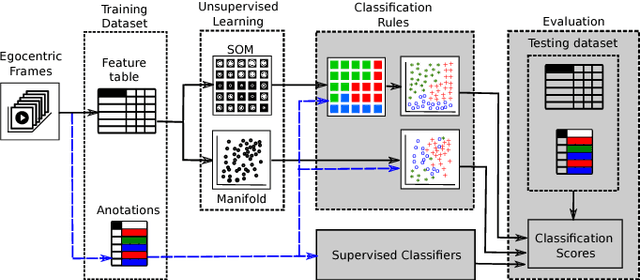
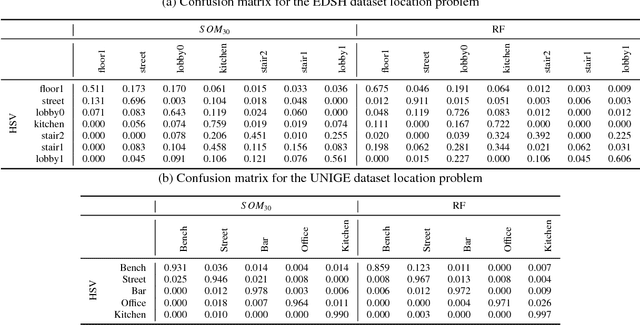
Wearable cameras stand out as one of the most promising devices for the upcoming years, and as a consequence, the demand of computer algorithms to automatically understand the videos recorded with them is increasing quickly. An automatic understanding of these videos is not an easy task, and its mobile nature implies important challenges to be faced, such as the changing light conditions and the unrestricted locations recorded. This paper proposes an unsupervised strategy based on global features and manifold learning to endow wearable cameras with contextual information regarding the light conditions and the location captured. Results show that non-linear manifold methods can capture contextual patterns from global features without compromising large computational resources. The proposed strategy is used, as an application case, as a switching mechanism to improve the hand-detection problem in egocentric videos.
Left/Right Hand Segmentation in Egocentric Videos
Jul 21, 2016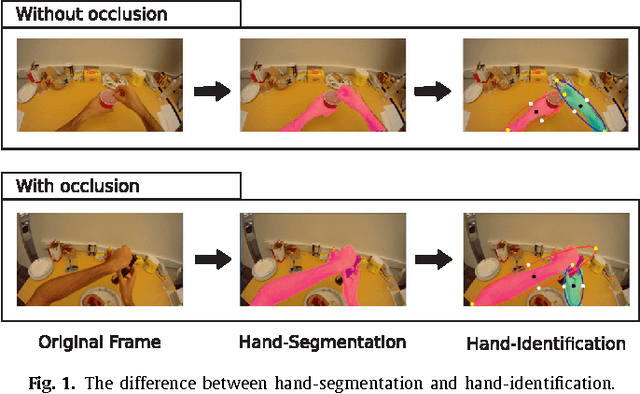
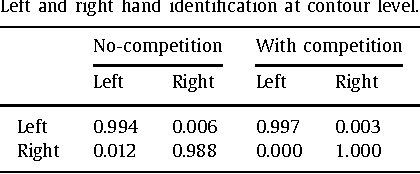


Wearable cameras allow people to record their daily activities from a user-centered (First Person Vision) perspective. Due to their favorable location, wearable cameras frequently capture the hands of the user, and may thus represent a promising user-machine interaction tool for different applications. Existent First Person Vision methods handle hand segmentation as a background-foreground problem, ignoring two important facts: i) hands are not a single "skin-like" moving element, but a pair of interacting cooperative entities, ii) close hand interactions may lead to hand-to-hand occlusions and, as a consequence, create a single hand-like segment. These facts complicate a proper understanding of hand movements and interactions. Our approach extends traditional background-foreground strategies, by including a hand-identification step (left-right) based on a Maxwell distribution of angle and position. Hand-to-hand occlusions are addressed by exploiting temporal superpixels. The experimental results show that, in addition to a reliable left/right hand-segmentation, our approach considerably improves the traditional background-foreground hand-segmentation.
The Evolution of First Person Vision Methods: A Survey
Apr 03, 2015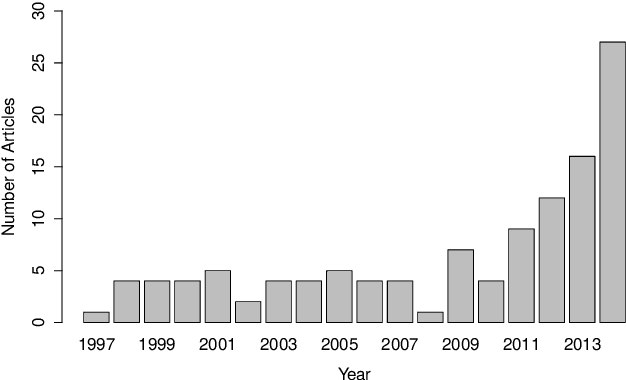
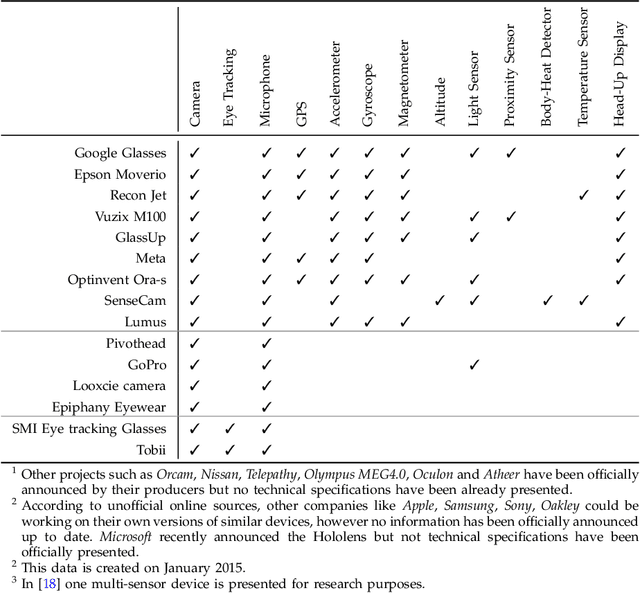
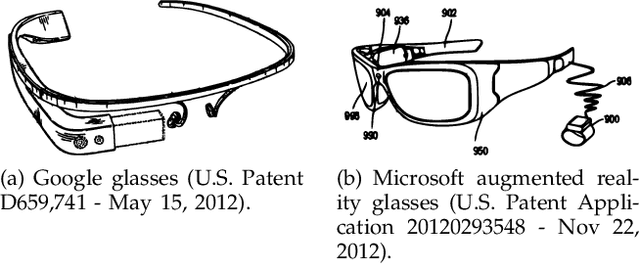
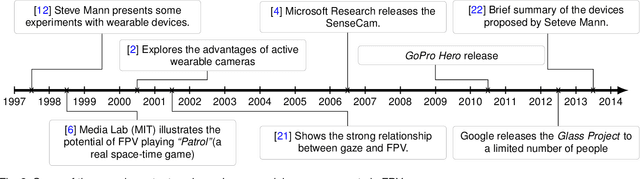
The emergence of new wearable technologies such as action cameras and smart-glasses has increased the interest of computer vision scientists in the First Person perspective. Nowadays, this field is attracting attention and investments of companies aiming to develop commercial devices with First Person Vision recording capabilities. Due to this interest, an increasing demand of methods to process these videos, possibly in real-time, is expected. Current approaches present a particular combinations of different image features and quantitative methods to accomplish specific objectives like object detection, activity recognition, user machine interaction and so on. This paper summarizes the evolution of the state of the art in First Person Vision video analysis between 1997 and 2014, highlighting, among others, most commonly used features, methods, challenges and opportunities within the field.
* First Person Vision, Egocentric Vision, Wearable Devices, Smart Glasses, Computer Vision, Video Analytics, Human-machine Interaction