 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Understanding of Location and Illumination Changes in Egocentric Videos
Paper and Code
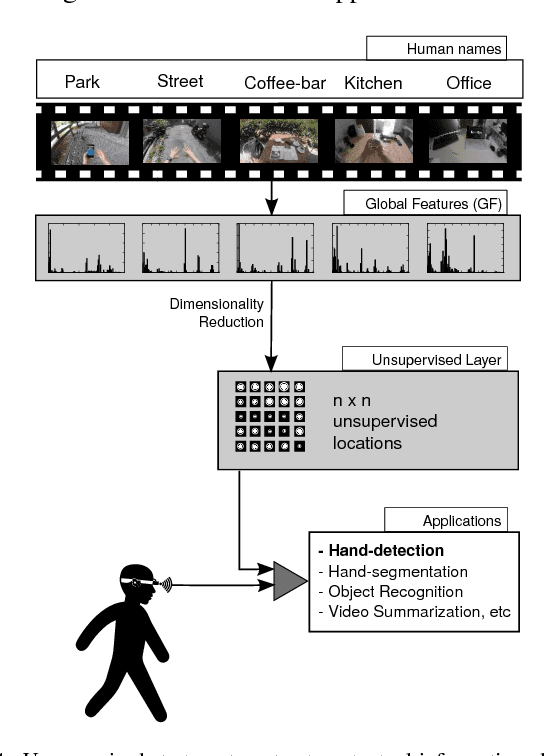
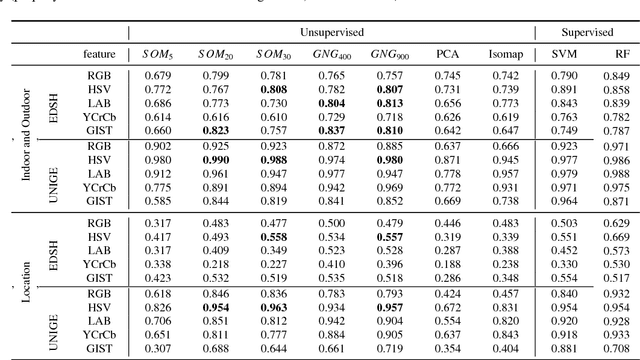
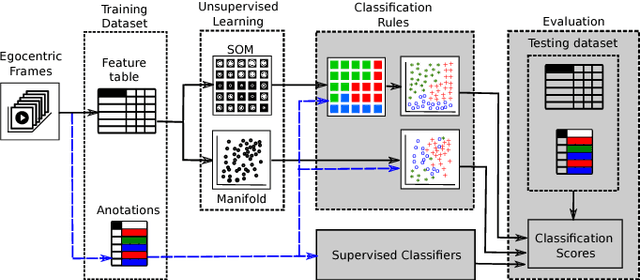
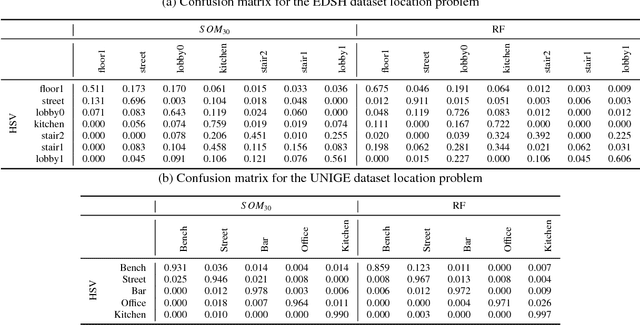
Wearable cameras stand out as one of the most promising devices for the upcoming years, and as a consequence, the demand of computer algorithms to automatically understand the videos recorded with them is increasing quickly. An automatic understanding of these videos is not an easy task, and its mobile nature implies important challenges to be faced, such as the changing light conditions and the unrestricted locations recorded. This paper proposes an unsupervised strategy based on global features and manifold learning to endow wearable cameras with contextual information regarding the light conditions and the location captured. Results show that non-linear manifold methods can capture contextual patterns from global features without compromising large computational resources. The proposed strategy is used, as an application case, as a switching mechanism to improve the hand-detection problem in egocentric videos.