 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of 3D LiDAR Resolution in Graph-based SLAM Approaches: A Comparative Study
Oct 22, 2024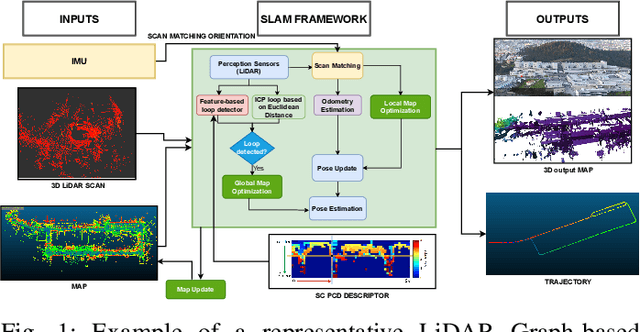
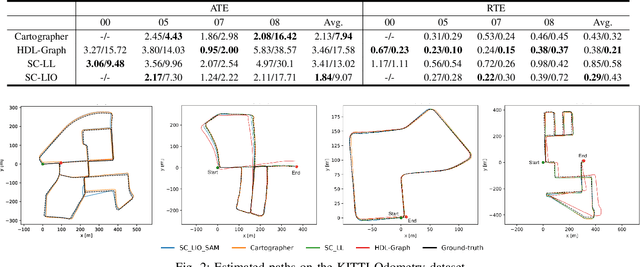
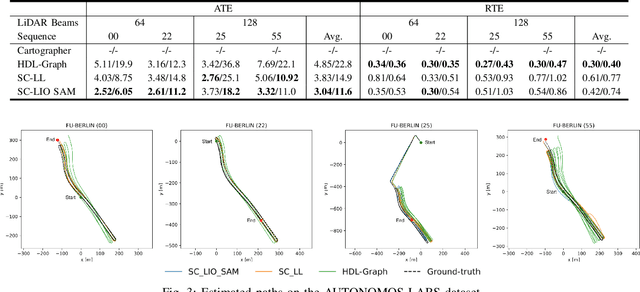

Simultaneous Localization and Mapping (SLAM) is a key component of autonomous systems operating in environments that require a consistent map for reliable localization. SLAM has been a widely studied topic for decades with most of the solutions being camera or LiDAR based. Early LiDAR-based approaches primarily relied on 2D data, whereas more recent frameworks use 3D data. In this work, we survey recent 3D LiDAR-based Graph-SLAM methods in urban environments, aiming to compare their strengths, weaknesses, and limitations. Additionally, we evaluate their robustness regarding the LiDAR resolution namely 64 $vs$ 128 channels. Regarding SLAM methods, we evaluate SC-LeGO-LOAM, SC-LIO-SAM, Cartographer, and HDL-Graph on real-world urban environments using the KITTI odometry dataset (a LiDAR with 64-channels only) and a new dataset (AUTONOMOS-LABS). The latter dataset, collected using instrumented vehicles driving in Berlin suburban area, comprises both 64 and 128 LiDARs. The experimental results are reported in terms of quantitative `metrics' and complemented by qualitative maps.
SPVSoAP3D: A Second-order Average Pooling Approach to enhance 3D Place Recognition in Horticultural Environments
Oct 22, 2024



3D LiDAR-based place recognition has been extensively researched in urban environments, yet it remains underexplored in agricultural settings. Unlike urban contexts, horticultural environments, characterized by their permeability to laser beams, result in sparse and overlapping LiDAR scans with suboptimal geometries. This phenomenon leads to intra- and inter-row descriptor ambiguity. In this work, we address this challenge by introducing SPVSoAP3D, a novel modeling approach that combines a voxel-based feature extraction network with an aggregation technique based on a second-order average pooling operator, complemented by a descriptor enhancement stage. Furthermore, we augment the existing HORTO-3DLM dataset by introducing two new sequences derived from horticultural environments. We evaluate the performance of SPVSoAP3D against state-of-the-art (SOTA) models, including OverlapTransformer, PointNetVLAD, and LOGG3D-Net, utilizing a cross-validation protocol on both the newly introduced sequences and the existing HORTO-3DLM dataset. The findings indicate that the average operator is more suitable for horticultural environments compared to the max operator and other first-order pooling techniques. Additionally, the results highlight the improvements brought by the descriptor enhancement stage.
PointNetPGAP-SLC: A 3D LiDAR-based Place Recognition Approach with Segment-level Consistency Training for Mobile Robots in Horticulture
May 29, 2024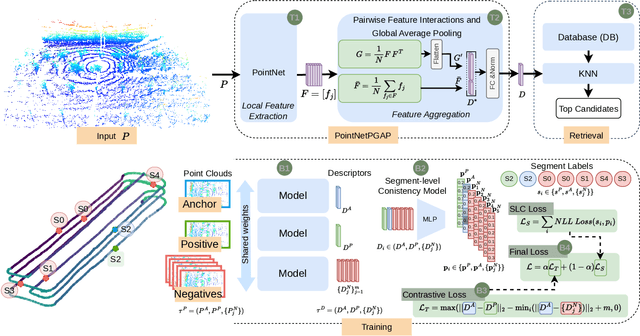
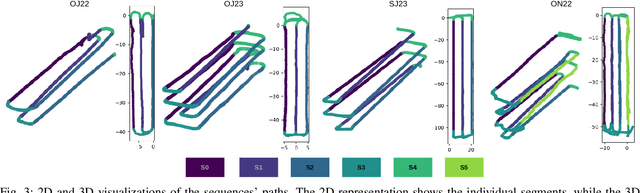
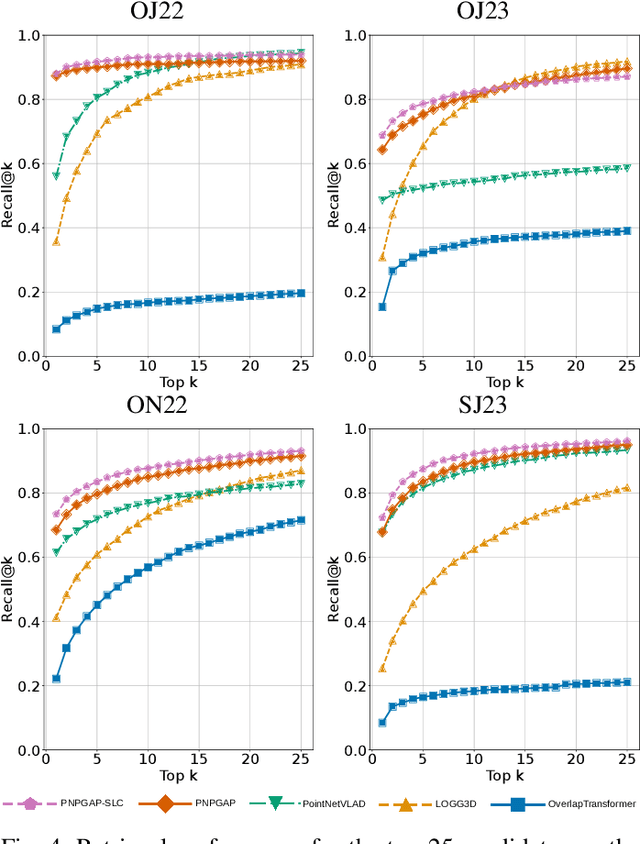
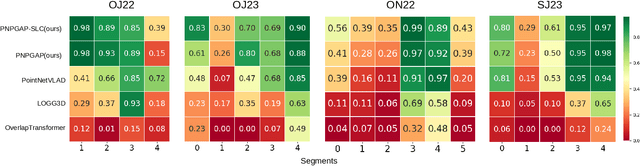
This paper addresses robotic place recognition in horticultural environments using 3D-LiDAR technology and deep learning. Three main contributions are proposed: (i) a novel model called PointNetPGAP, which combines a global average pooling aggregator and a pairwise feature interaction aggregator; (ii) a Segment-Level Consistency (SLC) model, used only during training, with the goal of augmenting the contrastive loss with a context-specific training signal to enhance descriptors; and (iii) a novel dataset named HORTO-3DLM featuring sequences from orchards and strawberry plantations. The experimental evaluation, conducted on the new HORTO-3DLM dataset, compares PointNetPGAP at the sequence- and segment-level with state-of-the-art (SOTA) models, including OverlapTransformer, PointNetVLAD, and LOGG3D. Additionally, all models were trained and evaluated using the SLC. Empirical results obtained through a cross-validation evaluation protocol demonstrate the superiority of PointNetPGAP compared to existing SOTA models. PointNetPGAP emerges as the best model in retrieving the top-1 candidate, outperforming PointNetVLAD (the second-best model). Moreover, when comparing the impact of training with the SLC model, performance increased on four out of the five evaluated models, indicating that adding a context-specific signal to the contrastive loss leads to improved descriptors.
ORCHNet: A Robust Global Feature Aggregation approach for 3D LiDAR-based Place recognition in Orchards
Mar 01, 2023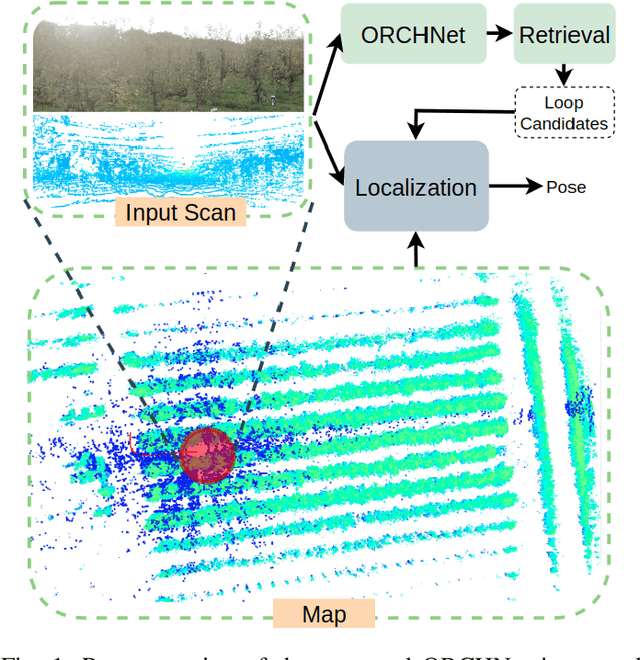
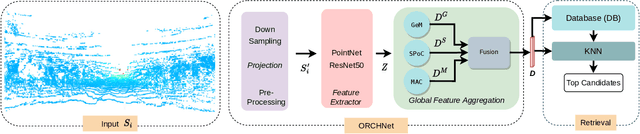
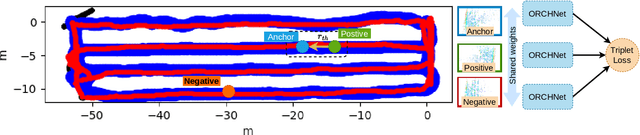

Robust and reliable place recognition and loop closure detection in agricultural environments is still an open problem. In particular, orchards are a difficult case study due to structural similarity across the entire field. In this work, we address the place recognition problem in orchards resorting to 3D LiDAR data, which is considered a key modality for robustness. Hence, we propose ORCHNet, a deep-learning-based approach that maps 3D-LiDAR scans to global descriptors. Specifically, this work proposes a new global feature aggregation approach, which fuses multiple aggregation methods into a robust global descriptor. ORCHNet is evaluated on real-world data collected in orchards, comprising data from the summer and autumn seasons. To assess the robustness, We compare ORCHNet with state-of-the-art aggregation approaches on data from the same season and across seasons. Moreover, we additionally evaluate the proposed approach as part of a localization framework, where ORCHNet is used as a loop closure detector. The empirical results indicate that, on the place recognition task, ORCHNet outperforms the remaining approaches, and is also more robust across seasons. As for the localization, the edge cases where the path goes through the trees are solved when integrating ORCHNet as a loop detector, showing the potential applicability of the proposed approach in this task. The code and dataset will be publicly available at:\url{https://github.com/Cybonic/ORCHNet.git}
Probabilistic Approach for Road-Users Detection
Dec 02, 2021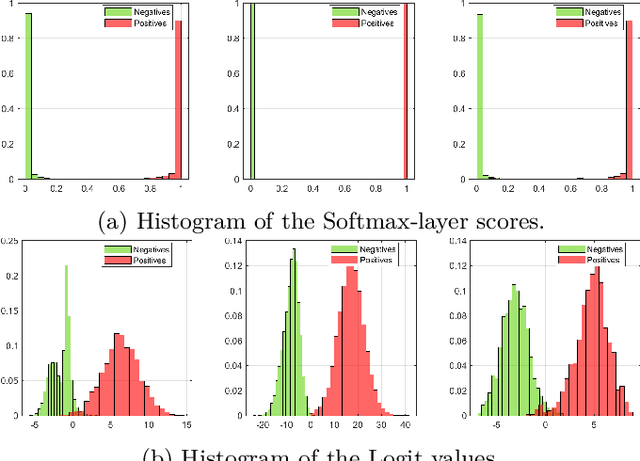


Object detection in autonomous driving applications implies that the detection and tracking of semantic objects are commonly native to urban driving environments, as pedestrians and vehicles. One of the major challenges in state-of-the-art deep-learning based object detection is false positive which occurrences with overconfident scores. This is highly undesirable in autonomous driving and other critical robotic-perception domains because of safety concerns. This paper proposes an approach to alleviate the problem of overconfident predictions by introducing a novel probabilistic layer to deep object detection networks in testing. The suggested approach avoids the traditional Sigmoid or Softmax prediction layer which often produces overconfident predictions. It is demonstrated that the proposed technique reduces overconfidence in the false positives without degrading the performance on the true positives. The approach is validated on the 2D-KITTI objection detection through the YOLOV4 and SECOND (Lidar-based detector). The proposed approach enables enabling interpretable probabilistic predictions without the requirement of re-training the network and therefore is very practical.
Multispectral Vineyard Segmentation: A Deep Learning approach
Aug 05, 2021



Digital agriculture has evolved significantly over the last few years due to the technological developments in automation and computational intelligence applied to the agricultural sector, including vineyards which are a relevant crop in the Mediterranean region. In this paper, a study of semantic segmentation for vine detection in real-world vineyards is presented by exploring state-of-the-art deep segmentation networks and conventional unsupervised methods. Camera data was collected on vineyards using an Unmanned Aerial System (UAS) equipped with a dual imaging sensor payload, namely a high-resolution color camera and a five-band multispectral and thermal camera. Extensive experiments of the segmentation networks and unsupervised methods have been performed on multimodal datasets representing three distinct vineyards located in the central region of Portugal. The reported results indicate that the best segmentation performances are obtained with deep networks, while traditional (non-deep) approaches using the NIR band shown competitive results. The results also show that multimodality slightly improves the performance of vine segmentation but the NIR spectrum alone generally is sufficient on most of the datasets. The code and dataset are publicly available on https://github.com/Cybonic/DL_vineyard_segmentation_study.git
Probabilistic Object Classification using CNN ML-MAP layers
May 29, 2020



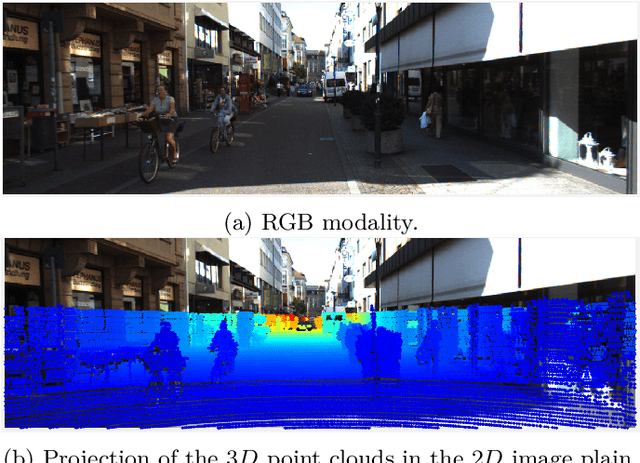
Deep networks are currently the state-of-the-art for sensory perception in autonomous driving and robotics. However, deep models often generate overconfident predictions precluding proper probabilistic interpretation which we argue is due to the nature of the SoftMax layer. To reduce the overconfidence without compromising the classification performance, we introduce a CNN probabilistic approach based on distributions calculated in the network's Logit layer. The approach enables Bayesian inference by means of ML and MAP layers. Experiments with calibrated and the proposed prediction layers are carried out on object classification using data from the KITTI database. Results are reported for camera ($RGB$) and LiDAR (range-view) modalities, where the new approach shows promising performance compared to SoftMax.
High-resolution LIDAR-based Depth Mapping using Bilateral Filter
Jun 17, 2016
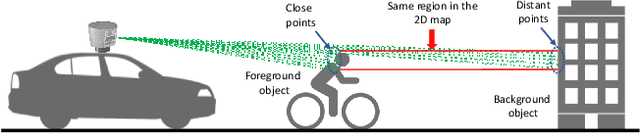


High resolution depth-maps, obtained by upsampling sparse range data from a 3D-LIDAR, find applications in many fields ranging from sensory perception to semantic segmentation and object detection. Upsampling is often based on combining data from a monocular camera to compensate the low-resolution of a LIDAR. This paper, on the other hand, introduces a novel framework to obtain dense depth-map solely from a single LIDAR point cloud; which is a research direction that has been barely explored. The formulation behind the proposed depth-mapping process relies on local spatial interpolation, using sliding-window (mask) technique, and on the Bilateral Filter (BF) where the variable of interest, the distance from the sensor, is considered in the interpolation problem. In particular, the BF is conveniently modified to perform depth-map upsampling such that the edges (foreground-background discontinuities) are better preserved by means of a proposed method which influences the range-based weighting term. Other methods for spatial upsampling are discussed, evaluated and compared in terms of different error measures. This paper also researches the role of the mask's size in the performance of the implemented methods. Quantitative and qualitative results from experiments on the KITTI Database, using LIDAR point clouds only, show very satisfactory performance of the approach introduced in this work.