 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUHDRes: Ultra-High-Definition Image Restoration via Dual-Domain Decoupled Spectral Modulation
Nov 07, 2025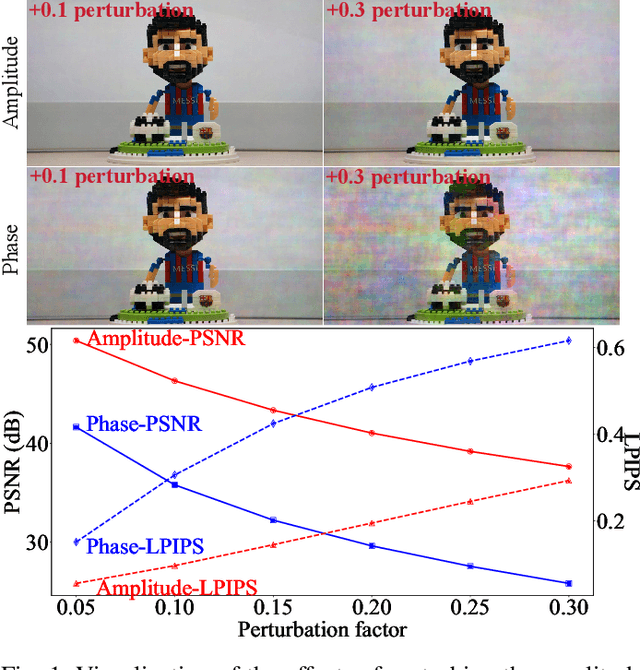



Ultra-high-definition (UHD) images often suffer from severe degradations such as blur, haze, rain, or low-light conditions, which pose significant challenges for image restoration due to their high resolution and computational demands. In this paper, we propose UHDRes, a novel lightweight dual-domain decoupled spectral modulation framework for UHD image restoration. It explicitly models the amplitude spectrum via lightweight spectrum-domain modulation, while restoring phase implicitly through spatial-domain refinement. We introduce the spatio-spectral fusion mechanism, which first employs a multi-scale context aggregator to extract local and global spatial features, and then performs spectral modulation in a decoupled manner. It explicitly enhances amplitude features in the frequency domain while implicitly restoring phase information through spatial refinement. Additionally, a shared gated feed-forward network is designed to efficiently promote feature interaction through shared-parameter convolutions and adaptive gating mechanisms. Extensive experimental comparisons on five public UHD benchmarks demonstrate that our UHDRes achieves the state-of-the-art restoration performance with only 400K parameters, while significantly reducing inference latency and memory usage. The codes and models are available at https://github.com/Zhao0100/UHDRes.
Probabilistic Approach for Road-Users Detection
Dec 02, 2021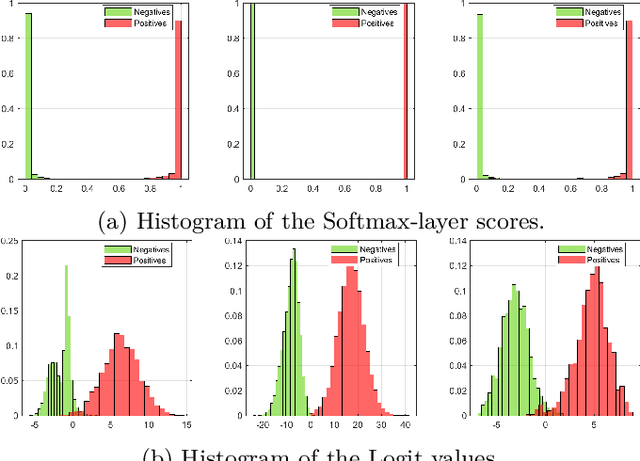


Object detection in autonomous driving applications implies that the detection and tracking of semantic objects are commonly native to urban driving environments, as pedestrians and vehicles. One of the major challenges in state-of-the-art deep-learning based object detection is false positive which occurrences with overconfident scores. This is highly undesirable in autonomous driving and other critical robotic-perception domains because of safety concerns. This paper proposes an approach to alleviate the problem of overconfident predictions by introducing a novel probabilistic layer to deep object detection networks in testing. The suggested approach avoids the traditional Sigmoid or Softmax prediction layer which often produces overconfident predictions. It is demonstrated that the proposed technique reduces overconfidence in the false positives without degrading the performance on the true positives. The approach is validated on the 2D-KITTI objection detection through the YOLOV4 and SECOND (Lidar-based detector). The proposed approach enables enabling interpretable probabilistic predictions without the requirement of re-training the network and therefore is very practical.
Statistical Inference of the Value Function for Reinforcement Learning in Infinite Horizon Settings
Jan 13, 2020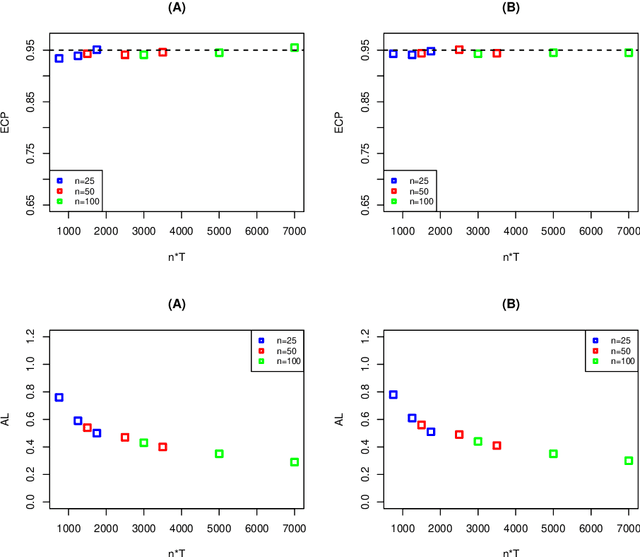
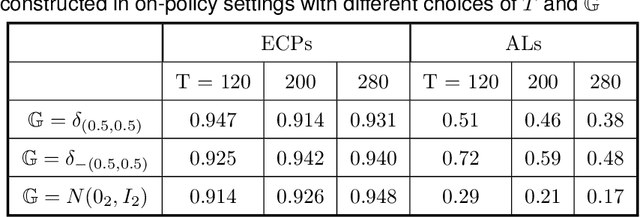
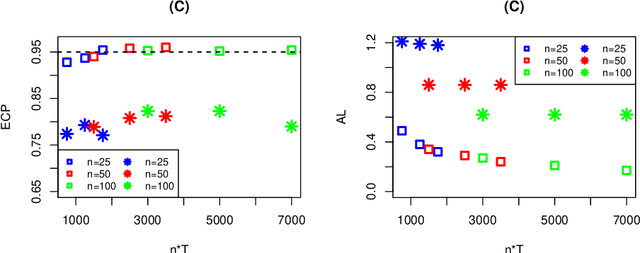
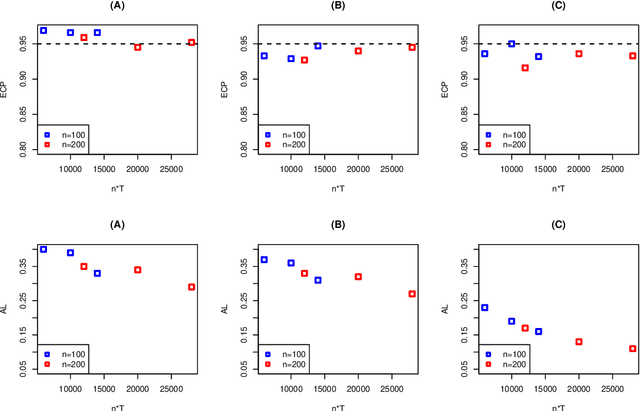
Reinforcement learning is a general technique that allows an agent to learn an optimal policy and interact with an environment in sequential decision making problems. The goodness of a policy is measured by its value function starting from some initial state. The focus of this paper is to construct confidence intervals (CIs) for a policy's value in infinite horizon settings where the number of decision points diverges to infinity. We propose to model the action-value state function (Q-function) associated with a policy based on series/sieve method to derive its confidence interval. When the target policy depends on the observed data as well, we propose a SequentiAl Value Evaluation (SAVE) method to recursively update the estimated policy and its value estimator. As long as either the number of trajectories or the number of decision points diverges to infinity, we show that the proposed CI achieves nominal coverage even in cases where the optimal policy is not unique. Simulation studies are conducted to back up our theoretical findings. We apply the proposed method to a dataset from mobile health studies and find that reinforcement learning algorithms could help improve patient's health status.