 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference of the Value Function for Reinforcement Learning in Infinite Horizon Settings
Jan 13, 2020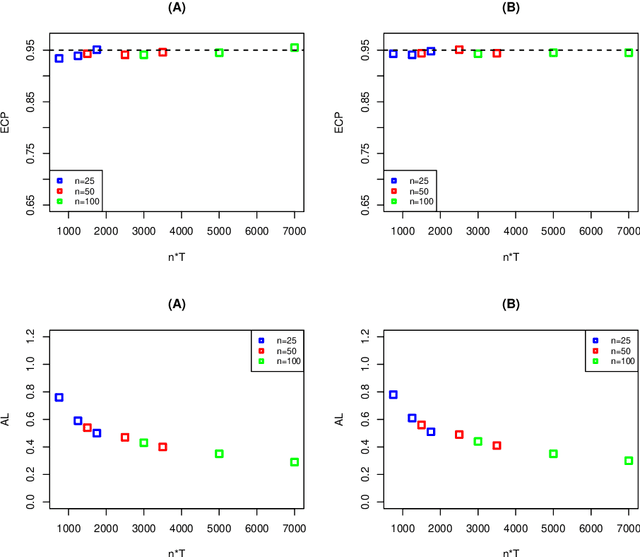
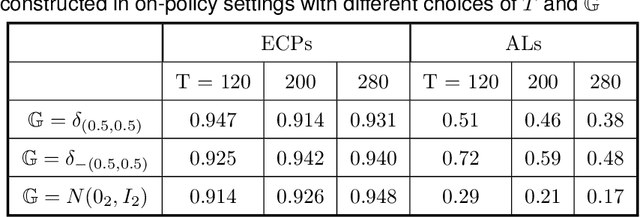
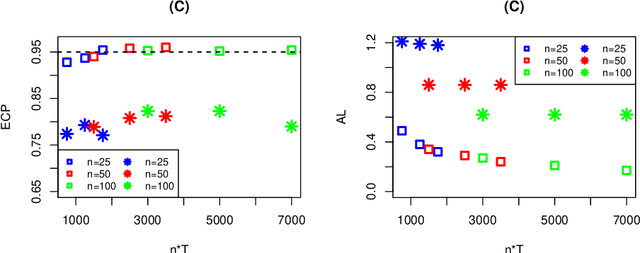
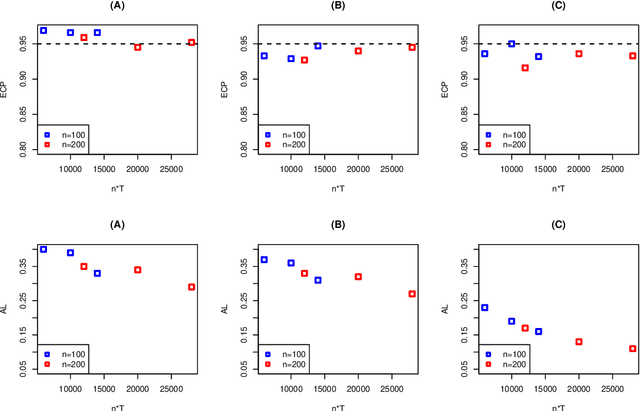
Reinforcement learning is a general technique that allows an agent to learn an optimal policy and interact with an environment in sequential decision making problems. The goodness of a policy is measured by its value function starting from some initial state. The focus of this paper is to construct confidence intervals (CIs) for a policy's value in infinite horizon settings where the number of decision points diverges to infinity. We propose to model the action-value state function (Q-function) associated with a policy based on series/sieve method to derive its confidence interval. When the target policy depends on the observed data as well, we propose a SequentiAl Value Evaluation (SAVE) method to recursively update the estimated policy and its value estimator. As long as either the number of trajectories or the number of decision points diverges to infinity, we show that the proposed CI achieves nominal coverage even in cases where the optimal policy is not unique. Simulation studies are conducted to back up our theoretical findings. We apply the proposed method to a dataset from mobile health studies and find that reinforcement learning algorithms could help improve patient's health status.