 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Native Integrated Sensing and Communications for Self-Organizing Wireless Networks: Architectures, Learning Paradigms, and System-Level Design
Dec 29, 2025Integrated Sensing and Communications (ISAC) is emerging as a foundational paradigm for next-generation wireless networks, enabling communication infrastructures to simultaneously support data transmission and environment sensing. By tightly coupling radio sensing with communication functions, ISAC unlocks new capabilities for situational awareness, localization, tracking, and network adaptation. At the same time, the increasing scale, heterogeneity, and dynamics of future wireless systems demand self-organizing network intelligence capable of autonomously managing resources, topology, and services. Artificial intelligence (AI), particularly learning-driven and data-centric methods, has become a key enabler for realizing this vision. This survey provides a comprehensive and system-level review of AI-native ISAC-enabled self-organizing wireless networks. We develop a unified taxonomy that spans: (i) ISAC signal models and sensing modalities, (ii) network state abstraction and perception from sensing-aware radio data, (iii) learning-driven self-organization mechanisms for resource allocation, topology control, and mobility management, and (iv) cross-layer architectures integrating sensing, communication, and network intelligence. We further examine emerging learning paradigms, including deep reinforcement learning, graph-based learning, multi-agent coordination, and federated intelligence that enable autonomous adaptation under uncertainty, mobility, and partial observability. Practical considerations such as sensing-communication trade-offs, scalability, latency, reliability, and security are discussed alongside representative evaluation methodologies and performance metrics. Finally, we identify key open challenges and future research directions toward deployable, trustworthy, and scalable AI-native ISAC systems for 6G and beyond.
Score-CDM: Score-Weighted Convolutional Diffusion Model for Multivariate Time Series Imputation
May 21, 2024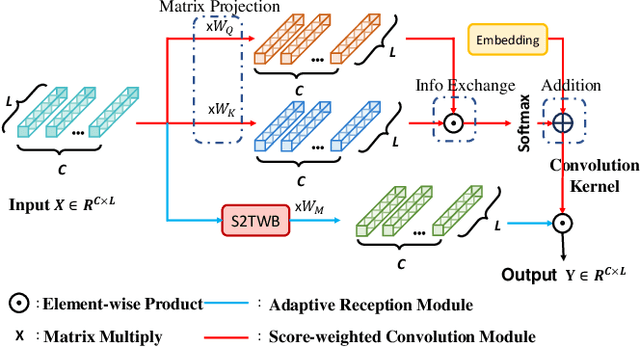
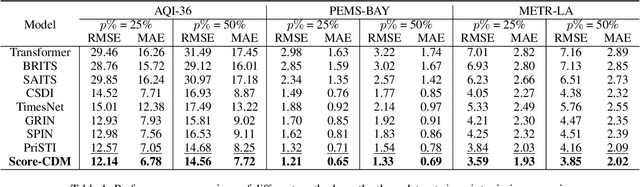
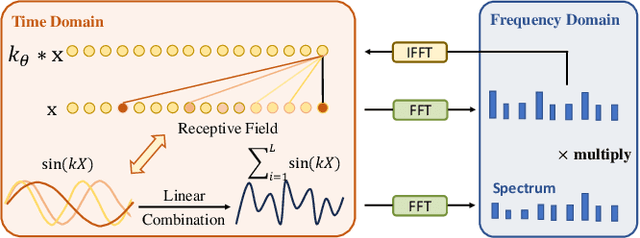
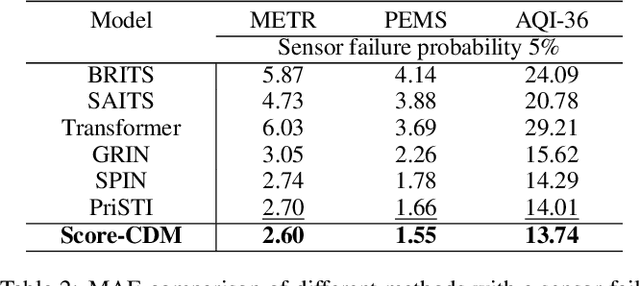
Multivariant time series (MTS) data are usually incomplete in real scenarios, and imputing the incomplete MTS is practically important to facilitate various time series mining tasks. Recently, diffusion model-based MTS imputation methods have achieved promising results by utilizing CNN or attention mechanisms for temporal feature learning. However, it is hard to adaptively trade off the diverse effects of local and global temporal features by simply combining CNN and attention. To address this issue, we propose a Score-weighted Convolutional Diffusion Model (Score-CDM for short), whose backbone consists of a Score-weighted Convolution Module (SCM) and an Adaptive Reception Module (ARM). SCM adopts a score map to capture the global temporal features in the time domain, while ARM uses a Spectral2Time Window Block (S2TWB) to convolve the local time series data in the spectral domain. Benefiting from the time convolution properties of Fast Fourier Transformation, ARM can adaptively change the receptive field of the score map, and thus effectively balance the local and global temporal features. We conduct extensive evaluations on three real MTS datasets of different domains, and the result verifies the effectiveness of the proposed Score-CDM.
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021

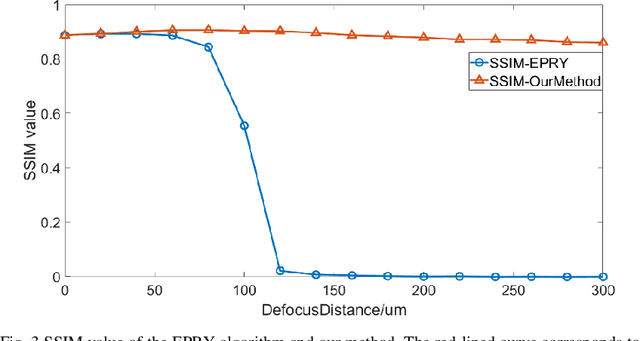

Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
Statistical Inference of the Value Function for Reinforcement Learning in Infinite Horizon Settings
Jan 13, 2020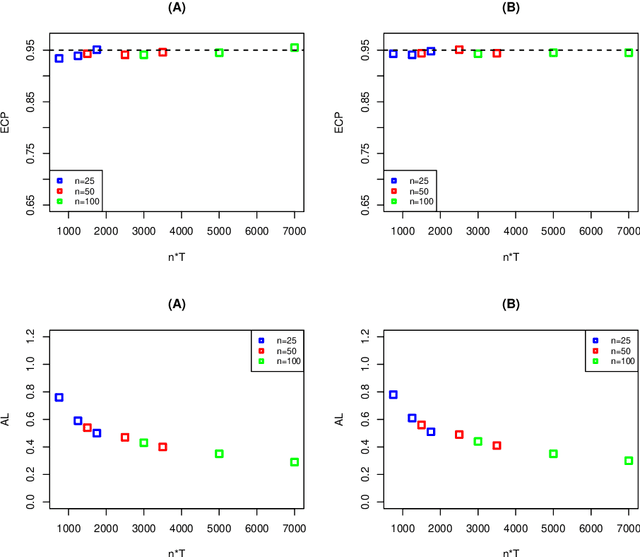
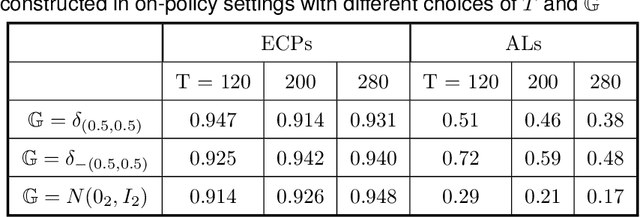
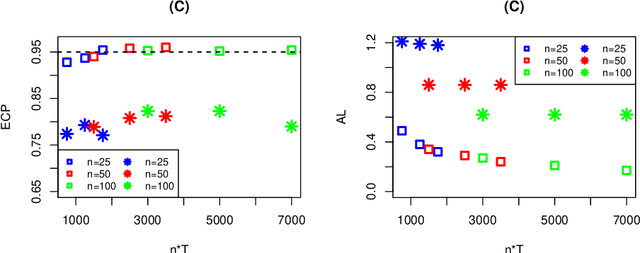
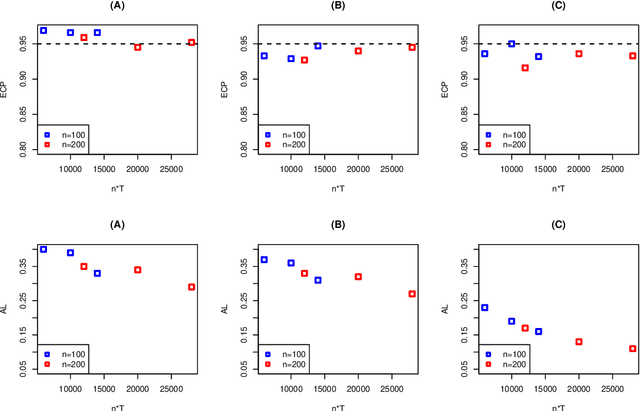
Reinforcement learning is a general technique that allows an agent to learn an optimal policy and interact with an environment in sequential decision making problems. The goodness of a policy is measured by its value function starting from some initial state. The focus of this paper is to construct confidence intervals (CIs) for a policy's value in infinite horizon settings where the number of decision points diverges to infinity. We propose to model the action-value state function (Q-function) associated with a policy based on series/sieve method to derive its confidence interval. When the target policy depends on the observed data as well, we propose a SequentiAl Value Evaluation (SAVE) method to recursively update the estimated policy and its value estimator. As long as either the number of trajectories or the number of decision points diverges to infinity, we show that the proposed CI achieves nominal coverage even in cases where the optimal policy is not unique. Simulation studies are conducted to back up our theoretical findings. We apply the proposed method to a dataset from mobile health studies and find that reinforcement learning algorithms could help improve patient's health status.