 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
Mar 16, 2026We present MiroThinker-1.7, a new research agent designed for complex long-horizon reasoning tasks. Building on this foundation, we further introduce MiroThinker-H1, which extends the agent with heavy-duty reasoning capabilities for more reliable multi-step problem solving. In particular, MiroThinker-1.7 improves the reliability of each interaction step through an agentic mid-training stage that emphasizes structured planning, contextual reasoning, and tool interaction. This enables more effective multi-step interaction and sustained reasoning across complex tasks. MiroThinker-H1 further incorporates verification directly into the reasoning process at both local and global levels. Intermediate reasoning decisions can be evaluated and refined during inference, while the overall reasoning trajectory is audited to ensure that final answers are supported by coherent chains of evidence. Across benchmarks covering open-web research, scientific reasoning, and financial analysis, MiroThinker-H1 achieves state-of-the-art performance on deep research tasks while maintaining strong results on specialized domains. We also release MiroThinker-1.7 and MiroThinker-1.7-mini as open-source models, providing competitive research-agent capabilities with significantly improved efficiency.
Score-CDM: Score-Weighted Convolutional Diffusion Model for Multivariate Time Series Imputation
May 21, 2024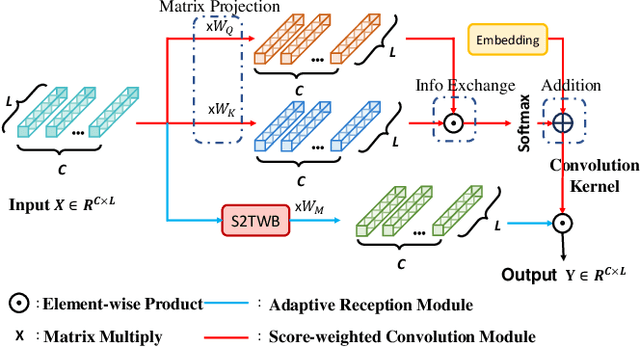
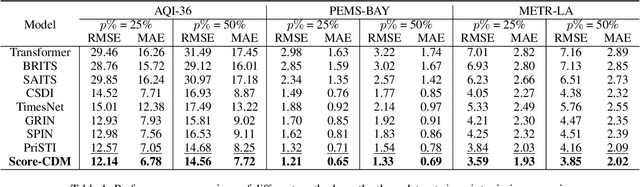
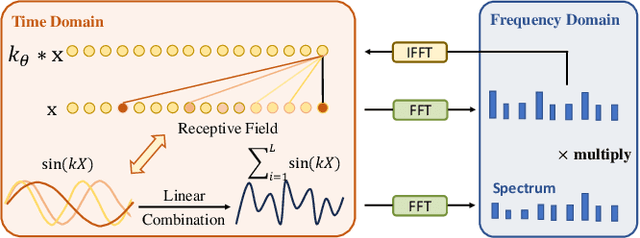
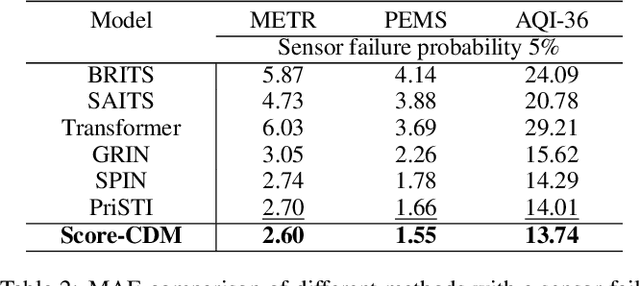
Multivariant time series (MTS) data are usually incomplete in real scenarios, and imputing the incomplete MTS is practically important to facilitate various time series mining tasks. Recently, diffusion model-based MTS imputation methods have achieved promising results by utilizing CNN or attention mechanisms for temporal feature learning. However, it is hard to adaptively trade off the diverse effects of local and global temporal features by simply combining CNN and attention. To address this issue, we propose a Score-weighted Convolutional Diffusion Model (Score-CDM for short), whose backbone consists of a Score-weighted Convolution Module (SCM) and an Adaptive Reception Module (ARM). SCM adopts a score map to capture the global temporal features in the time domain, while ARM uses a Spectral2Time Window Block (S2TWB) to convolve the local time series data in the spectral domain. Benefiting from the time convolution properties of Fast Fourier Transformation, ARM can adaptively change the receptive field of the score map, and thus effectively balance the local and global temporal features. We conduct extensive evaluations on three real MTS datasets of different domains, and the result verifies the effectiveness of the proposed Score-CDM.
MGTCOM: Community Detection in Multimodal Graphs
Nov 10, 2022
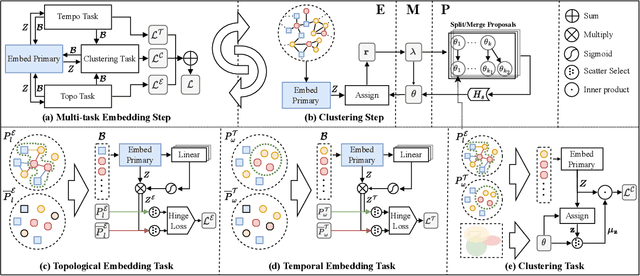
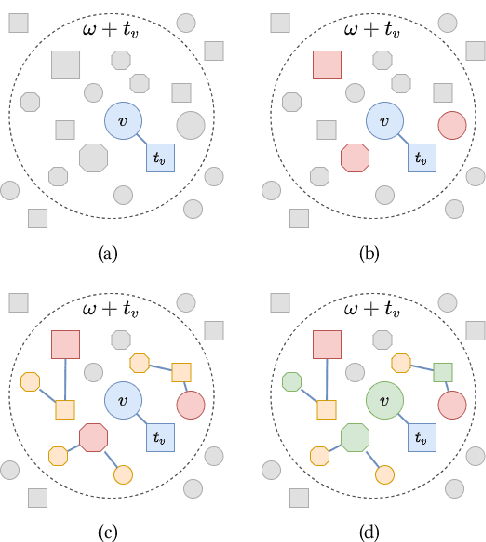
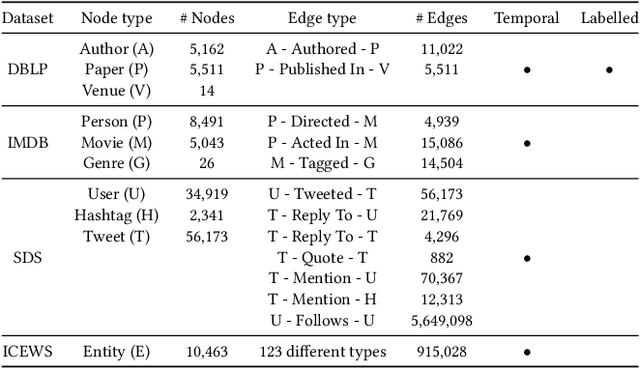
Community detection is the task of discovering groups of nodes sharing similar patterns within a network. With recent advancements in deep learning, methods utilizing graph representation learning and deep clustering have shown great results in community detection. However, these methods often rely on the topology of networks (i) ignoring important features such as network heterogeneity, temporality, multimodality, and other possibly relevant features. Besides, (ii) the number of communities is not known a priori and is often left to model selection. In addition, (iii) in multimodal networks all nodes are assumed to be symmetrical in their features; while true for homogeneous networks, most of the real-world networks are heterogeneous where feature availability often varies. In this paper, we propose a novel framework (named MGTCOM) that overcomes the above challenges (i)--(iii). MGTCOM identifies communities through multimodal feature learning by leveraging a new sampling technique for unsupervised learning of temporal embeddings. Importantly, MGTCOM is an end-to-end framework optimizing network embeddings, communities, and the number of communities in tandem. In order to assess its performance, we carried out an extensive evaluation on a number of multimodal networks. We found out that our method is competitive against state-of-the-art and performs well in inductive inference.
Recovery Conditions of Sparse Signals Using Orthogonal Least Squares-Type Algorithms
Jan 13, 2022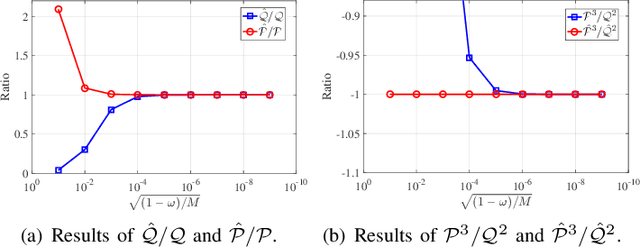
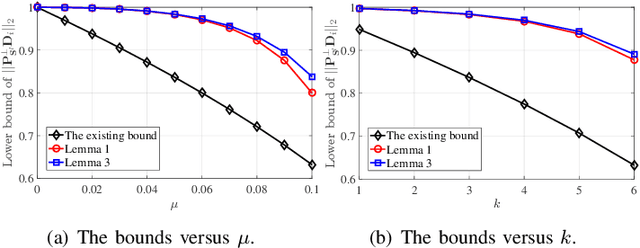
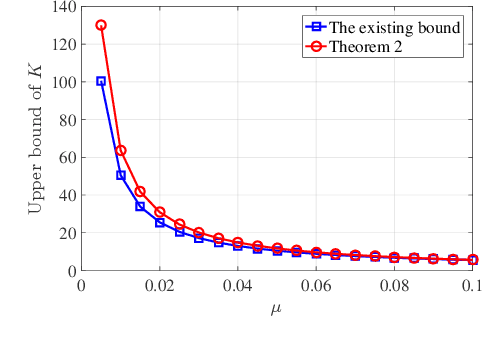
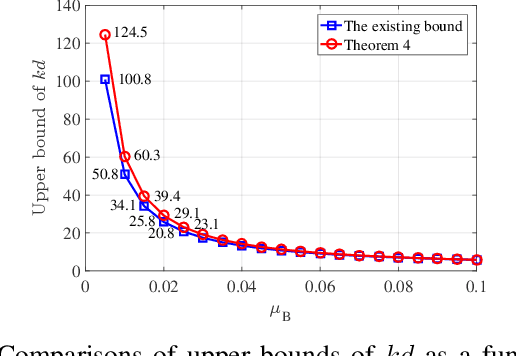
Orthogonal least squares (OLS)-type algorithms are efficient in reconstructing sparse signals, which include the well-known OLS, multiple OLS (MOLS) and block OLS (BOLS). In this paper, we first investigate the noiseless exact recovery conditions of these algorithms. Specifically, based on mutual incoherence property (MIP), we provide theoretical analysis of OLS and MOLS to ensure that the correct nonzero support can be selected during the iterative procedure. Nevertheless, theoretical analysis for BOLS utilizes the block-MIP to deal with the block sparsity. Furthermore, the noiseless MIP-based analyses are extended to the noisy scenario. Our results indicate that for K-sparse signals, when MIP or SNR satisfies certain conditions, OLS and MOLS obtain reliable reconstruction in at most K iterations, while BOLS succeeds in at most (K/d) iterations where d is the block length. It is shown that our derived theoretical results improve the existing ones, which are verified by simulation tests.
An Experimental Study of Class Imbalance in Federated Learning
Sep 09, 2021
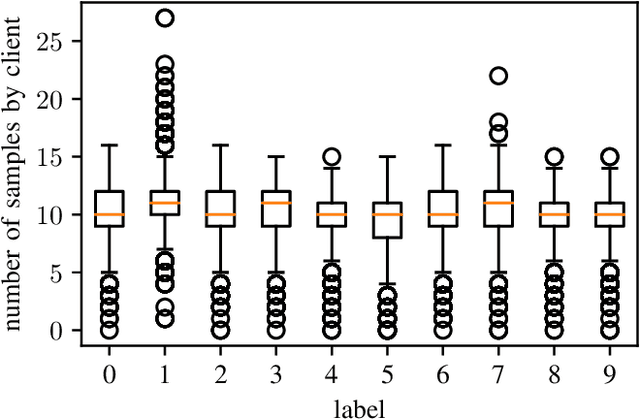
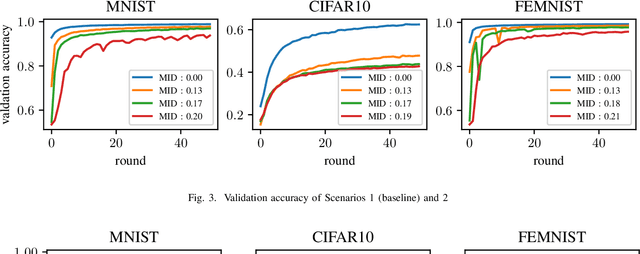
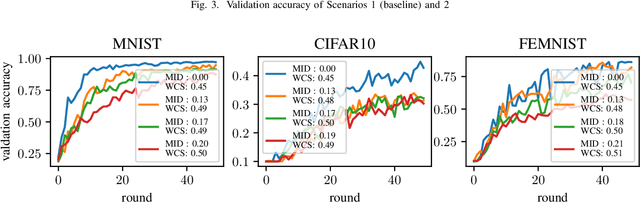
Federated learning is a distributed machine learning paradigm that trains a global model for prediction based on a number of local models at clients while local data privacy is preserved. Class imbalance is believed to be one of the factors that degrades the global model performance. However, there has been very little research on if and how class imbalance can affect the global performance. class imbalance in federated learning is much more complex than that in traditional non-distributed machine learning, due to different class imbalance situations at local clients. Class imbalance needs to be re-defined in distributed learning environments. In this paper, first, we propose two new metrics to define class imbalance -- the global class imbalance degree (MID) and the local difference of class imbalance among clients (WCS). Then, we conduct extensive experiments to analyze the impact of class imbalance on the global performance in various scenarios based on our definition. Our results show that a higher MID and a larger WCS degrade more the performance of the global model. Besides, WCS is shown to slow down the convergence of the global model by misdirecting the optimization.
Choice modelling in the age of machine learning
Jan 28, 2021
Since its inception, the choice modelling field has been dominated by theory-driven models. The recent emergence and growing popularity of machine learning models offer an alternative data-driven approach. Machine learning models, techniques and practices could help overcome problems and limitations of the current theory-driven modelling paradigm, e.g. relating to the ad-hocness in search for the optimal model specification, and theory-driven choice model's inability to work with text and image data. However, despite the potential value of machine learning to improve choice modelling practices, the choice modelling field has been somewhat hesitant to embrace machine learning. The aim of this paper is to facilitate (further) integration of machine learning in the choice modelling field. To achieve this objective, we make the case that (further) integration of machine learning in the choice modelling field is beneficial for the choice modelling field, and, we shed light on where the benefits of further integration can be found. Specifically, we take the following approach. First, we clarify the similarities and differences between the two modelling paradigms. Second, we provide a literature overview on the use of machine learning for choice modelling. Third, we reinforce the strengths of the current theory-driven modelling paradigm and compare this with the machine learning modelling paradigm, Fourth, we identify opportunities for embracing machine learning for choice modelling, while recognising the strengths of the current theory-driven paradigm. Finally, we put forward a vision on the future relationship between the theory-driven choice models and machine learning.
Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification
Apr 09, 2020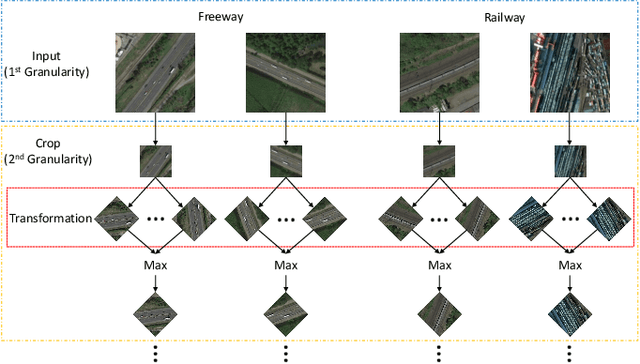
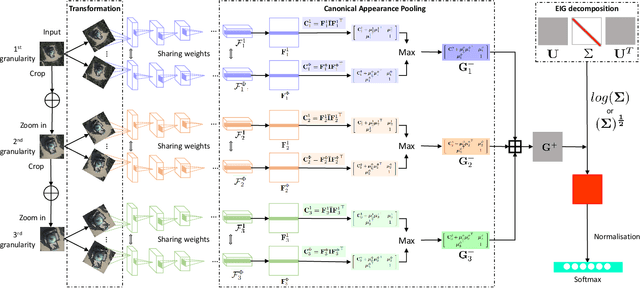
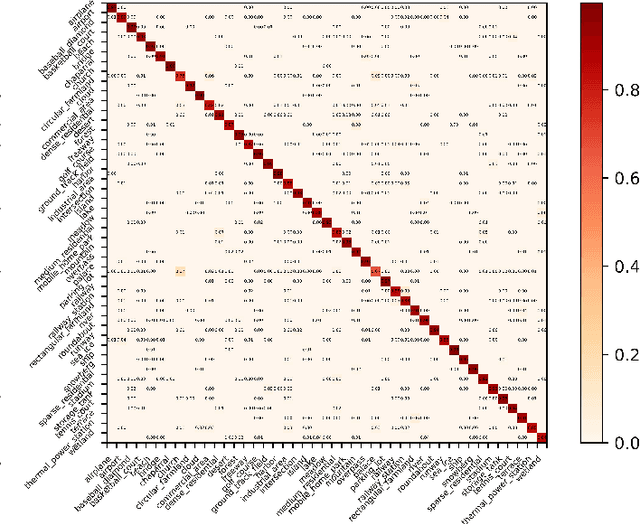
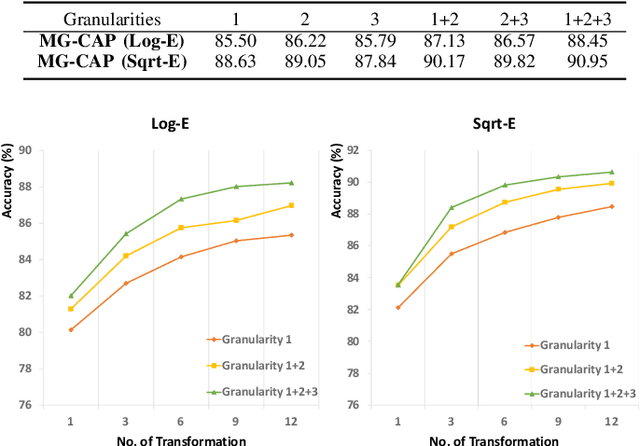
Recognising remote sensing scene images remains challenging due to large visual-semantic discrepancies. These mainly arise due to the lack of detailed annotations that can be employed to align pixel-level representations with high-level semantic labels. As the tagging process is labour-intensive and subjective, we hereby propose a novel Multi-Granularity Canonical Appearance Pooling (MG-CAP) to automatically capture the latent ontological structure of remote sensing datasets. We design a granular framework that allows progressively cropping the input image to learn multi-grained features. For each specific granularity, we discover the canonical appearance from a set of pre-defined transformations and learn the corresponding CNN features through a maxout-based Siamese style architecture. Then, we replace the standard CNN features with Gaussian covariance matrices and adopt the proper matrix normalisations for improving the discriminative power of features. Besides, we provide a stable solution for training the eigenvalue-decomposition function (EIG) in a GPU and demonstrate the corresponding back-propagation using matrix calculus. Extensive experiments have shown that our framework can achieve promising results in public remote sensing scene datasets.
* This paper is going to be published by IEEE Transactions on Image Processing