 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification
Apr 09, 2020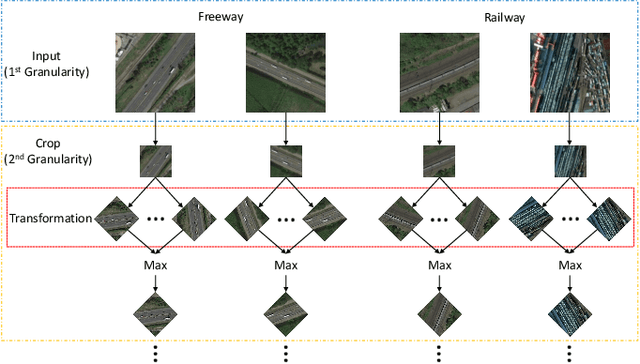
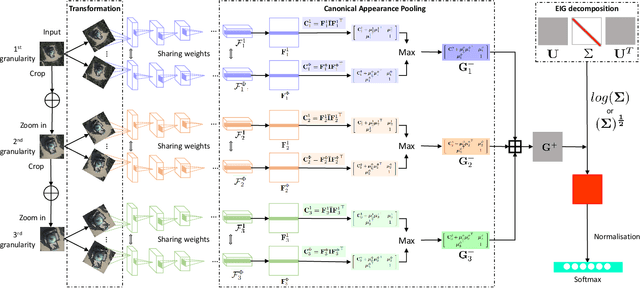
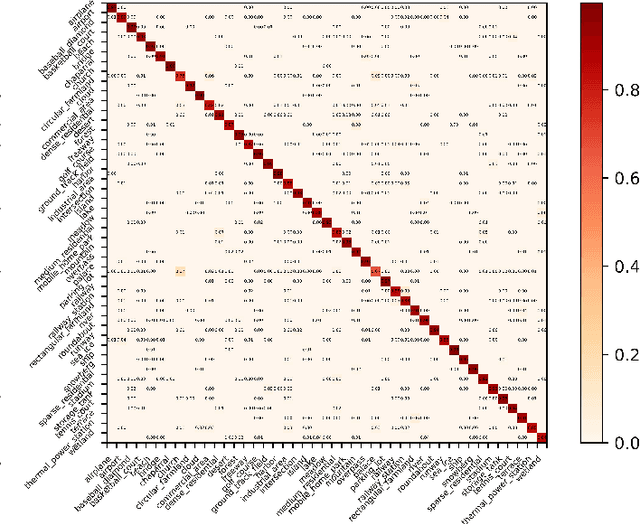
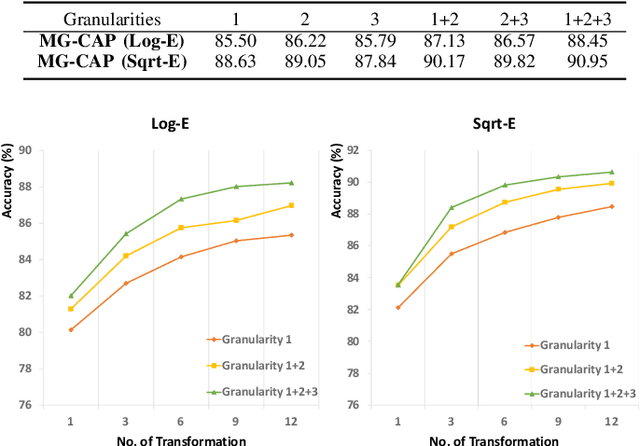
Recognising remote sensing scene images remains challenging due to large visual-semantic discrepancies. These mainly arise due to the lack of detailed annotations that can be employed to align pixel-level representations with high-level semantic labels. As the tagging process is labour-intensive and subjective, we hereby propose a novel Multi-Granularity Canonical Appearance Pooling (MG-CAP) to automatically capture the latent ontological structure of remote sensing datasets. We design a granular framework that allows progressively cropping the input image to learn multi-grained features. For each specific granularity, we discover the canonical appearance from a set of pre-defined transformations and learn the corresponding CNN features through a maxout-based Siamese style architecture. Then, we replace the standard CNN features with Gaussian covariance matrices and adopt the proper matrix normalisations for improving the discriminative power of features. Besides, we provide a stable solution for training the eigenvalue-decomposition function (EIG) in a GPU and demonstrate the corresponding back-propagation using matrix calculus. Extensive experiments have shown that our framework can achieve promising results in public remote sensing scene datasets.
* This paper is going to be published by IEEE Transactions on Image Processing