 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Path Tracking Using the Simplex Architecture
Mar 13, 2025Robot navigation in complex environments necessitates controllers that are adaptive and safe. Traditional controllers like Regulated Pure Pursuit, Dynamic Window Approach, and Model-Predictive Path Integral, while reliable, struggle to adapt to dynamic conditions. Reinforcement Learning offers adaptability but lacks formal safety guarantees. To address this, we propose a path tracking controller leveraging the Simplex architecture. It combines a Reinforcement Learning controller for adaptiveness and performance with a high-assurance controller providing safety and stability. Our contribution is twofold. We firstly discuss general stability and safety considerations for designing controllers using the Simplex architecture. Secondly, we present a Simplex-based path tracking controller. Our simulation results, supported by preliminary in-field tests, demonstrate the controller's effectiveness in maintaining safety while achieving comparable performance to state-of-the-art methods.
An Event-Based Approach for the Conservative Compression of Covariance Matrices
Mar 09, 2024
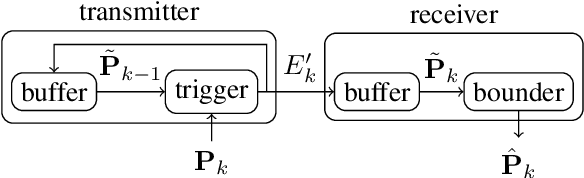

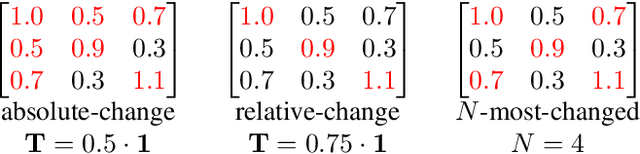
This work introduces a flexible and versatile method for the data-efficient yet conservative transmission of covariance matrices, where a matrix element is only transmitted if a so-called triggering condition is satisfied for the element. Here, triggering conditions can be parametrized on a per-element basis, applied simultaneously to yield combined triggering conditions or applied only to certain subsets of elements. This allows, e.g., to specify transmission accuracies for individual elements or to constrain the bandwidth available for the transmission of subsets of elements. Additionally, a methodology for learning triggering condition parameters from an application-specific dataset is presented. The performance of the proposed approach is quantitatively assessed in terms of data reduction and conservativeness using estimate data derived from real-world vehicle trajectories from the InD-dataset, demonstrating substantial data reduction ratios with minimal over-conservativeness. The feasibility of learning triggering condition parameters is demonstrated.
Exploiting Structure for Optimal Multi-Agent Bayesian Decentralized Estimation
Jul 20, 2023
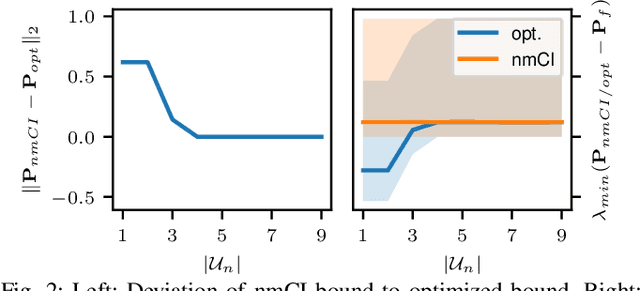


A key challenge in Bayesian decentralized data fusion is the `rumor propagation' or `double counting' phenomenon, where previously sent data circulates back to its sender. It is often addressed by approximate methods like covariance intersection (CI) which takes a weighted average of the estimates to compute the bound. The problem is that this bound is not tight, i.e. the estimate is often over-conservative. In this paper, we show that by exploiting the probabilistic independence structure in multi-agent decentralized fusion problems a tighter bound can be found using (i) an expansion to the CI algorithm that uses multiple (non-monolithic) weighting factors instead of one (monolithic) factor in the original CI and (ii) a general optimization scheme that is able to compute optimal bounds and fully exploit an arbitrary dependency structure. We compare our methods and show that on a simple problem, they converge to the same solution. We then test our new non-monolithic CI algorithm on a large-scale target tracking simulation and show that it achieves a tighter bound and a more accurate estimate compared to the original monolithic CI.
Discriminative Feature Learning through Feature Distance Loss
May 25, 2022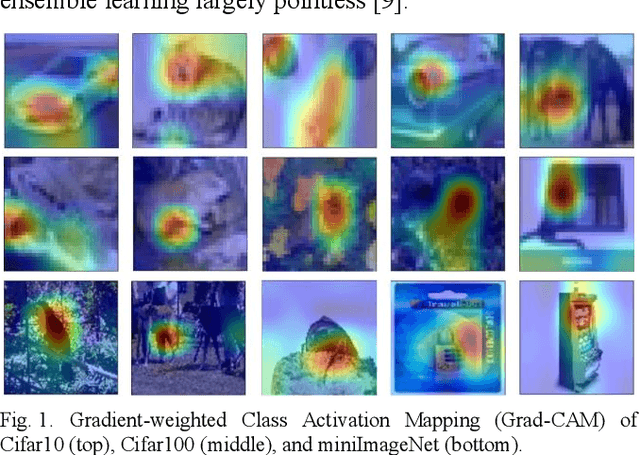
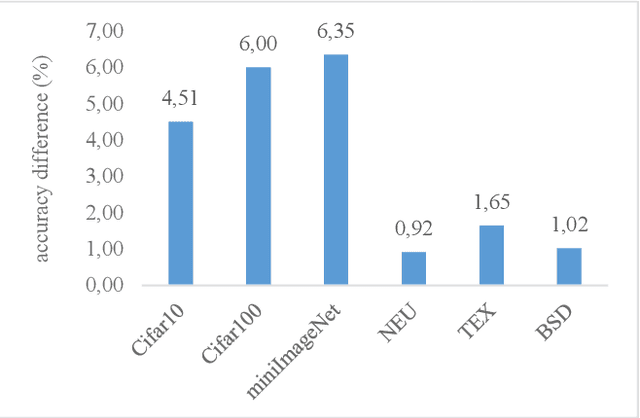
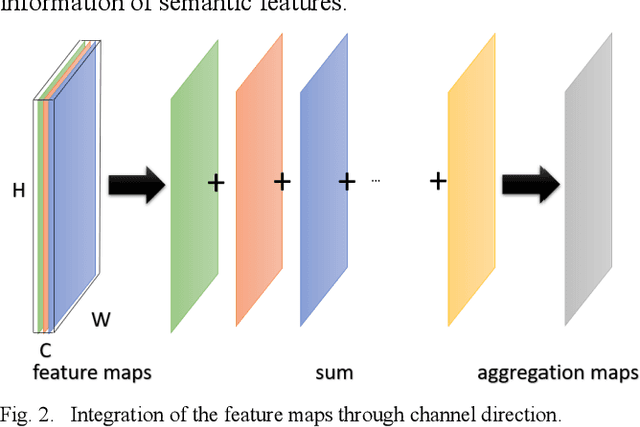
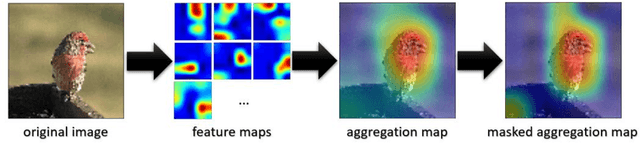
Convolutional neural networks have shown remarkable ability to learn discriminative semantic features in image recognition tasks. Though, for classification they often concentrate on specific regions in images. This work proposes a novel method that combines variant rich base models to concentrate on different important image regions for classification. A feature distance loss is implemented while training an ensemble of base models to force them to learn discriminative feature concepts. The experiments on benchmark convolutional neural networks (VGG16, ResNet, AlexNet), popular datasets (Cifar10, Cifar100, miniImageNet, NEU, BSD, TEX), and different training samples (3, 5, 10, 20, 50, 100 per class) show our methods effectiveness and generalization ability. Our method outperforms ensemble versions of the base models without feature distance loss, and the Class Activation Maps explicitly proves the ability to learn different discriminative feature concepts.
Improved Pose Graph Optimization for Planar Motions Using Riemannian Geometry on the Manifold of Dual Quaternions
Jul 31, 2019
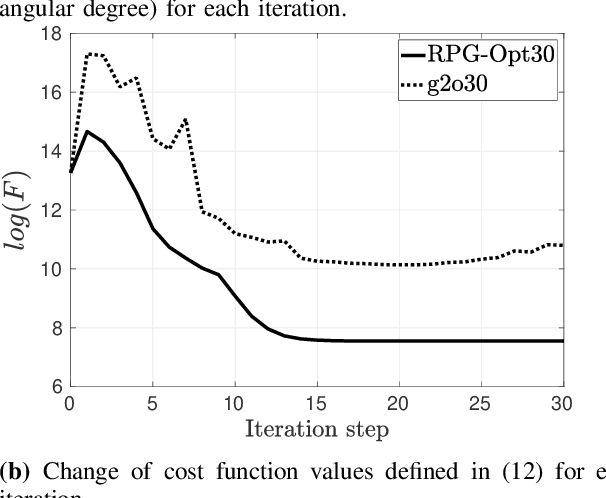
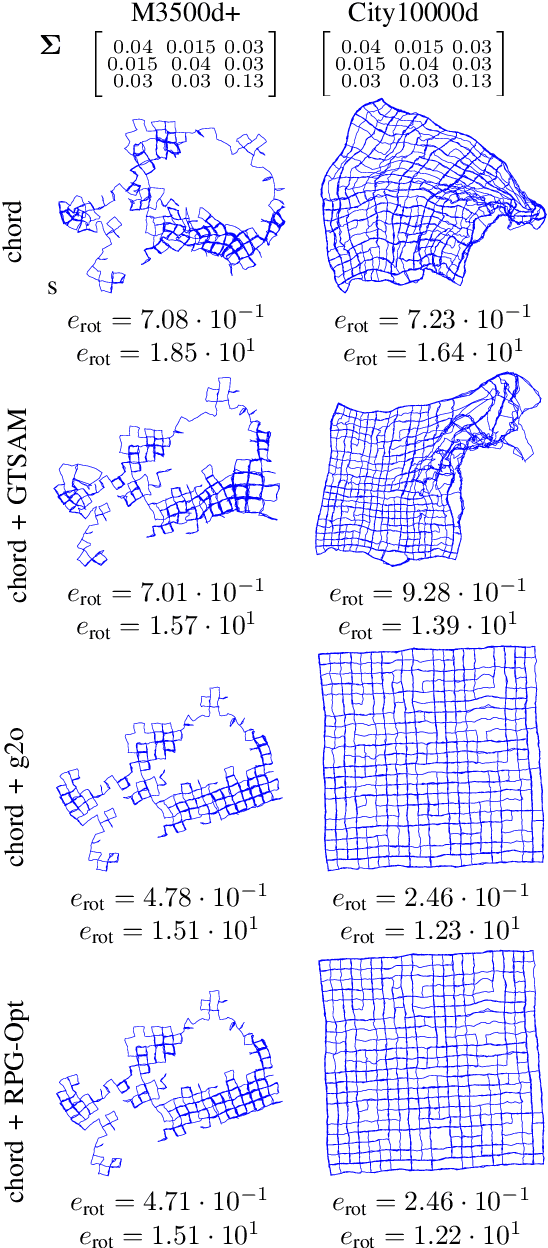

We present a novel Riemannian approach for planar pose graph optimization problems. By formulating the cost function based on the Riemannian metric on the manifold of dual quaternions representing planar motions, the nonlinear structure of the SE(2) group is inherently considered. To solve the on-manifold least squares problem, a Riemannian Gauss-Newton method using the exponential retraction is applied. The proposed Riemannian pose graph optimizer (RPG-Opt) is further compared with currently popular optimization frameworks using public planar pose graph datasets. Evaluations show that the proposed method gives equivalently accurate results as the state-of-the-art frameworks and shows better convergence robustness under large uncertainties of odometry measurements.