 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlowing Down Forgetting in Continual Learning
Nov 11, 2024



A common challenge in continual learning (CL) is catastrophic forgetting, where the performance on old tasks drops after new, additional tasks are learned. In this paper, we propose a novel framework called ReCL to slow down forgetting in CL. Our framework exploits an implicit bias of gradient-based neural networks due to which these converge to margin maximization points. Such convergence points allow us to reconstruct old data from previous tasks, which we then combine with the current training data. Our framework is flexible and can be applied on top of existing, state-of-the-art CL methods to slow down forgetting. We further demonstrate the performance gain from our framework across a large series of experiments, including different CL scenarios (class incremental, domain incremental, task incremental learning) different datasets (MNIST, CIFAR10), and different network architectures. Across all experiments, we find large performance gains through ReCL. To the best of our knowledge, our framework is the first to address catastrophic forgetting by leveraging models in CL as their own memory buffers.
Cross-domain Transfer of defect features in technical domains based on partial target data
Nov 24, 2022A common challenge in real world classification scenarios with sequentially appending target domain data is insufficient training datasets during the training phase. Therefore, conventional deep learning and transfer learning classifiers are not applicable especially when individual classes are not represented or are severely underrepresented at the outset. In many technical domains, however, it is only the defect or worn reject classes that are insufficiently represented, while the non-defect class is often available from the beginning. The proposed classification approach addresses such conditions and is based on a CNN encoder. Following a contrastive learning approach, it is trained with a modified triplet loss function using two datasets: Besides the non-defective target domain class 1st dataset, a state-of-the-art labeled source domain dataset that contains highly related classes e.g., a related manufacturing error or wear defect but originates from a highly different domain e.g., different product, material, or appearance = 2nd dataset is utilized. The approach learns the classification features from the source domain dataset while at the same time learning the differences between the source and the target domain in a single training step, aiming to transfer the relevant features to the target domain. The classifier becomes sensitive to the classification features and by architecture robust against the highly domain-specific context. The approach is benchmarked in a technical and a non-technical domain and shows convincing classification results. In particular, it is shown that the domain generalization capabilities and classification results are improved by the proposed architecture, allowing for larger domain shifts between source and target domains.
Discriminative Feature Learning through Feature Distance Loss
May 25, 2022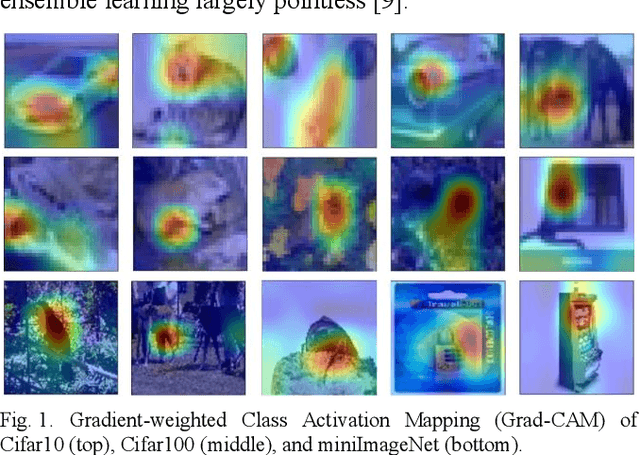
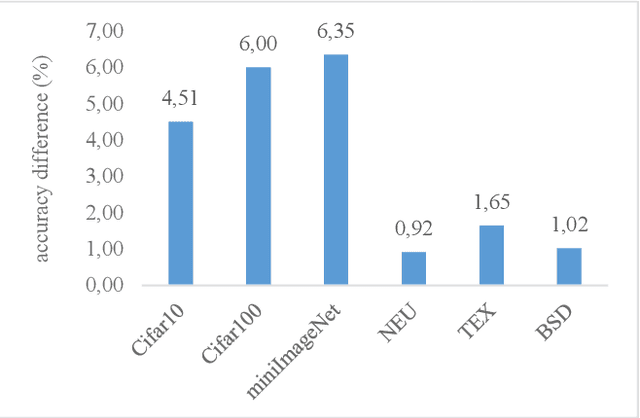
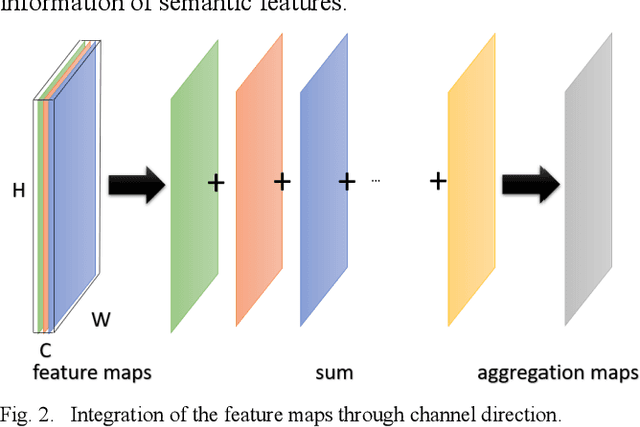
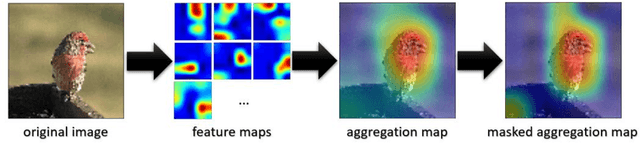
Convolutional neural networks have shown remarkable ability to learn discriminative semantic features in image recognition tasks. Though, for classification they often concentrate on specific regions in images. This work proposes a novel method that combines variant rich base models to concentrate on different important image regions for classification. A feature distance loss is implemented while training an ensemble of base models to force them to learn discriminative feature concepts. The experiments on benchmark convolutional neural networks (VGG16, ResNet, AlexNet), popular datasets (Cifar10, Cifar100, miniImageNet, NEU, BSD, TEX), and different training samples (3, 5, 10, 20, 50, 100 per class) show our methods effectiveness and generalization ability. Our method outperforms ensemble versions of the base models without feature distance loss, and the Class Activation Maps explicitly proves the ability to learn different discriminative feature concepts.
Text Detection on Technical Drawings for the Digitization of Brown-field Processes
May 05, 2022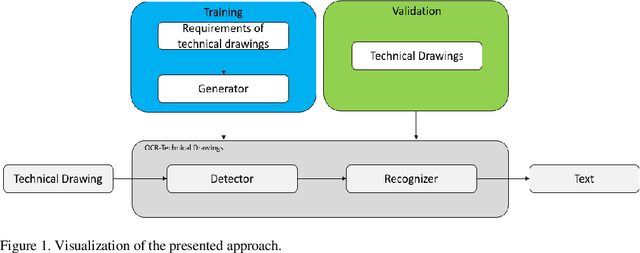
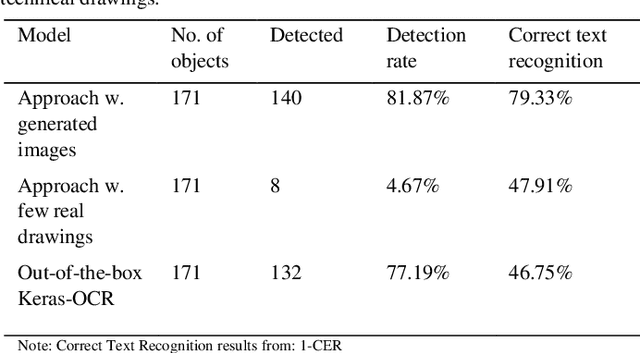
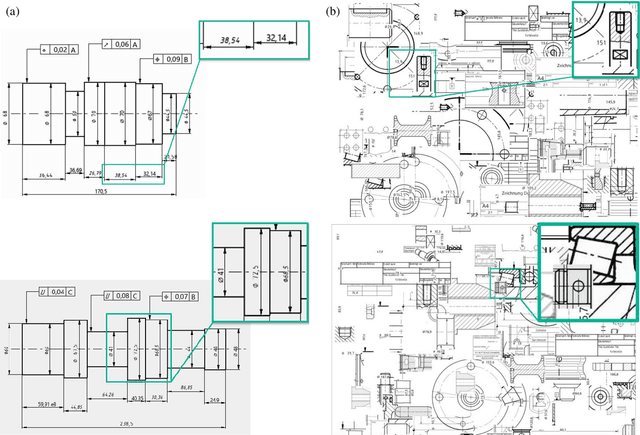

This paper addresses the issue of autonomously detecting text on technical drawings. The detection of text on technical drawings is a critical step towards autonomous production machines, especially for brown-field processes, where no closed CAD-CAM solutions are available yet. Automating the process of reading and detecting text on technical drawings reduces the effort for handling inefficient media interruptions due to paper-based processes, which are often todays quasi-standard in brown-field processes. However, there are no reliable methods available yet to solve the issue of automatically detecting text on technical drawings. The unreliable detection of the contents on technical drawings using classical detection and object character recognition (OCR) tools is mainly due to the limited number of technical drawings and the captcha-like structure of the contents. Text is often combined with unknown symbols and interruptions by lines. Additionally, due to intellectual property rights and technical know-how issues, there are no out-of-the box training datasets available in the literature to train such models. This paper combines a domain knowledge-based generator to generate realistic technical drawings with a state-of-the-art object detection model to solve the issue of detecting text on technical drawings. The generator yields artificial technical drawings in a large variety and can be considered as a data augmentation generator. These artificial drawings are used for training, while the model is tested on real data. The authors show that artificially generated data of technical drawings improve the detection quality with an increasing number of drawings.
Analysis of the Visually Detectable Wear Progress on Ball Screws
May 02, 2022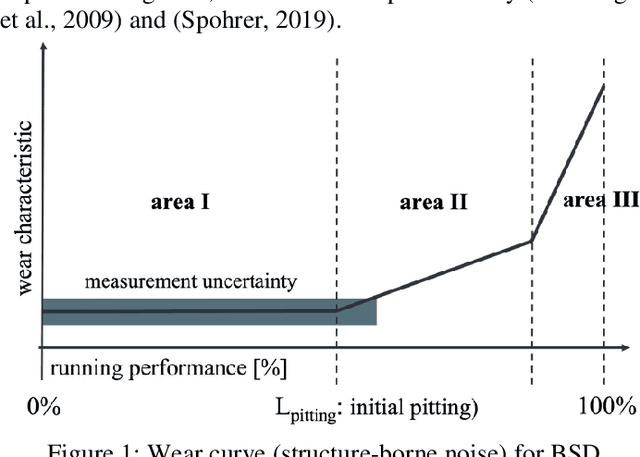

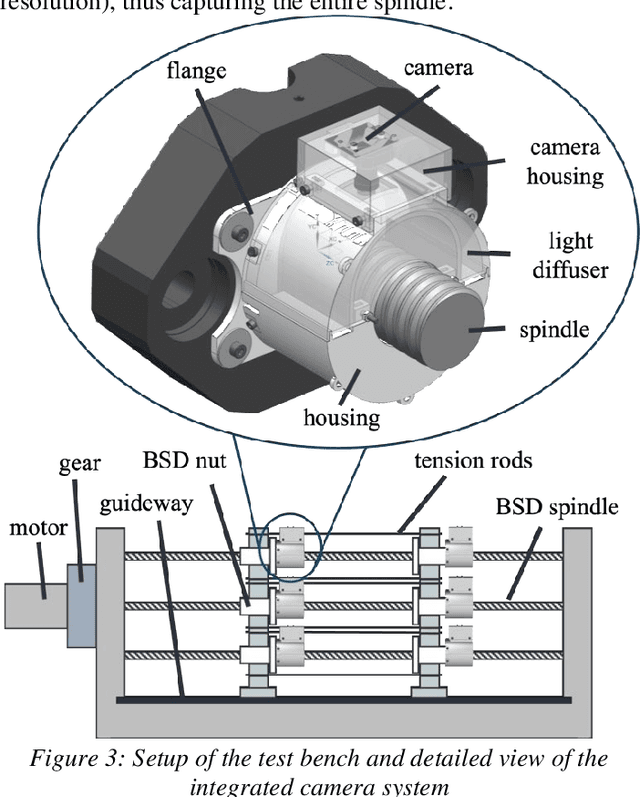

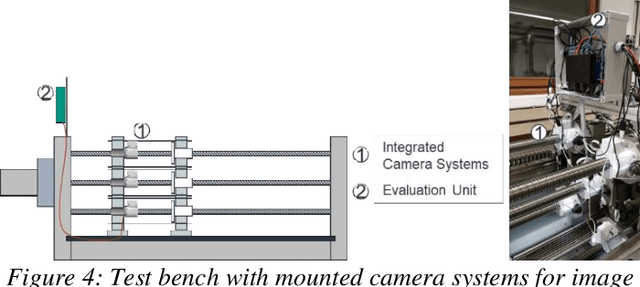
The actual progression of pitting on ball screw drive spindles is not well known since previous studies have only relied on the investigation of indirect wear effects (e. g. temperature, motor current, structure-borne noise). Using images from a camera system for ball screw drives, this paper elaborates on the visual analysis of pitting itself. Due to its direct, condition-based assessment of the wear state, an image-based approach offers several advantages, such as: Good interpretability, low influence of environmental conditions, and high spatial resolution. The study presented in this paper is based on a dataset containing the entire wear progression from original condition to component failure of ten ball screw drive spindles. The dataset is being analyzed regarding the following parameters: Axial length, tangential length, and surface area of each pit, the total number of pits, and the time of initial visual appearance of each pit. The results provide evidence that wear development can be quantified based on visual wear characteristics. In addition, using the dedicated camera system, the actual course of the growth curve of individual pits can be captured during machine operation. Using the findings of the analysis, the authors propose a formula for standards-based wear quantification based on geometric wear characteristics.
Industrial Machine Tool Component Surface Defect Dataset
Mar 24, 2021


Using machine learning (ML) techniques in general and deep learning techniques in specific needs a certain amount of data often not available in large quantities in technical domains. The manual inspection of machine tool components and the manual end-of-line check of products are labor-intensive tasks in industrial applications that companies often want to automate. To automate classification processes and develop reliable and robust machine learning-based classification and wear prognostics models, one needs real-world datasets to train and test the models. The dataset is available under https://doi.org/10.5445/IR/1000129520.
Siamese Basis Function Networks for Defect Classification
Dec 09, 2020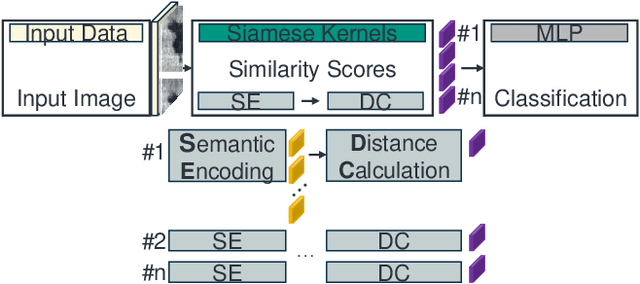
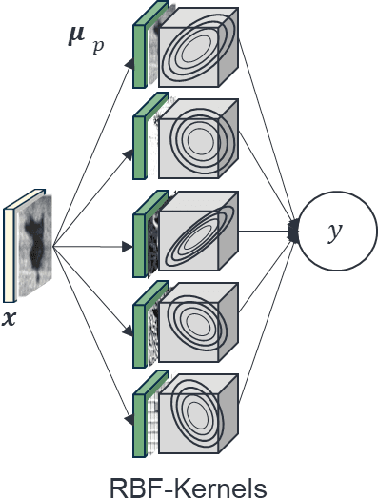
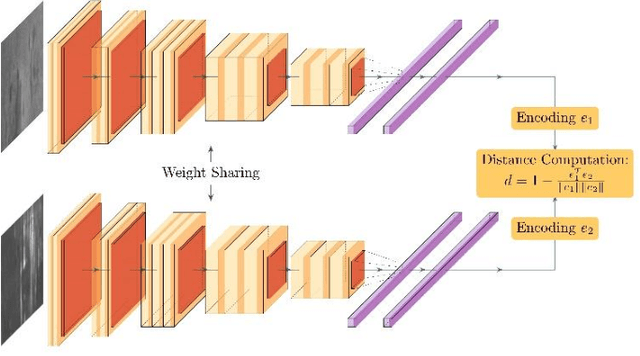
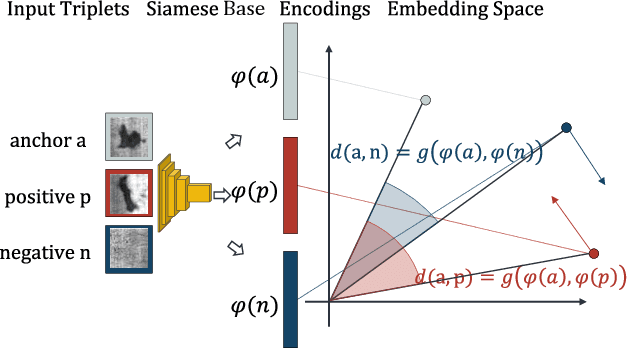
Defect classification on metallic surfaces is considered a critical issue since substantial quantities of steel and other metals are processed by the manufacturing industry on a daily basis. The authors propose a new approach where they introduce the usage of so called Siamese Kernels in a Basis Function Network to create the Siamese Basis Function Network (SBF-Network). The underlying idea is to classify by comparison using similarity scores. This classification is reinforced through efficient deep learning based feature extraction methods. First, a center image is assigned to each Siamese Kernel. The Kernels are then trained to generate encodings in a way that enables them to distinguish their center from other images in the dataset. Using this approach the authors created some kind of class-awareness inside the Siamese Kernels. To classify a given image, each Siamese Kernel generates a feature vector for its center as well as the given image. These vectors represent encodings of the respective images in a lower-dimensional space. The distance between each pair of encodings is then computed using the cosine distance together with radial basis functions. The distances are fed into a multilayer neural network to perform the classification. With this approach the authors achieved outstanding results on the state of the art NEU surface defect dataset.
A Stitching Algorithm for Automated Surface Inspection of Rotationally Symmetric Components
Dec 01, 2020

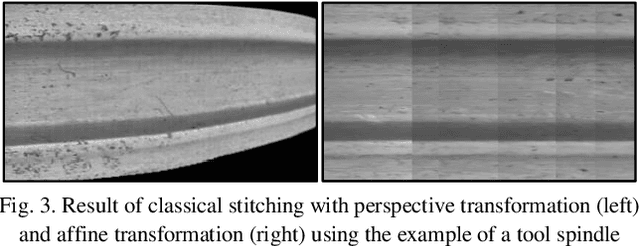
This paper provides a novel approach to stitching surface images of rotationally symmetric parts. It presents a process pipeline that uses a feature-based stitching approach to create a distortion-free and true-to-life image from a video file. The developed process thus enables, for example, condition monitoring without having to view many individual images. For validation purposes, this will be demonstrated in the paper using the concrete example of a worn ball screw drive spindle. The developed algorithm aims at reproducing the functional principle of a line scan camera system, whereby the physical measuring systems are replaced by a feature-based approach. For evaluation of the stitching algorithms, metrics are used, some of which have only been developed in this work or have been supplemented by test procedures already in use. The applicability of the developed algorithm is not only limited to machine tool spindles. Instead, the developed method allows a general approach to the surface inspection of various rotationally symmetric components and can therefore be used in a variety of industrial applications. Deep-learning-based detection Algorithms can easily be implemented to generate a complete pipeline for failure detection and condition monitoring on rotationally symmetric parts.
GAN based ball screw drive picture database enlargement for failure classification
Nov 20, 2020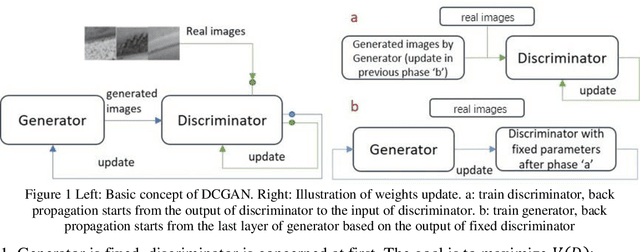

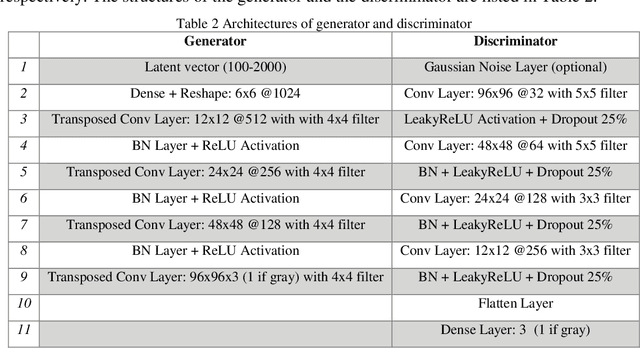
The lack of reliable large datasets is one of the biggest difficulties of using modern machine learning methods in the field of failure detection in the manufacturing industry. In order to develop the function of failure classification for ball screw surface, sufficient image data of surface failures is necessary. When training a neural network model based on a small dataset, the trained model may lack the generalization ability and may perform poorly in practice. The main goal of this paper is to generate synthetic images based on the generative adversarial network (GAN) to enlarge the image dataset of ball screw surface failures. Pitting failure and rust failure are two possible failure types on ball screw surface chosen in this paper to represent the surface failure classes. The quality and diversity of generated images are evaluated afterwards using qualitative methods including expert observation, t-SNE visualization and the quantitative method of FID score. To verify whether the GAN based generated images can increase failure classification performance, the real image dataset was augmented and replaced by GAN based generated images to do the classification task. The authors successfully created GAN based images of ball screw surface failures which showed positive effect on classification test performance.
Context-based Image Segment Labeling (CBISL)
Nov 02, 2020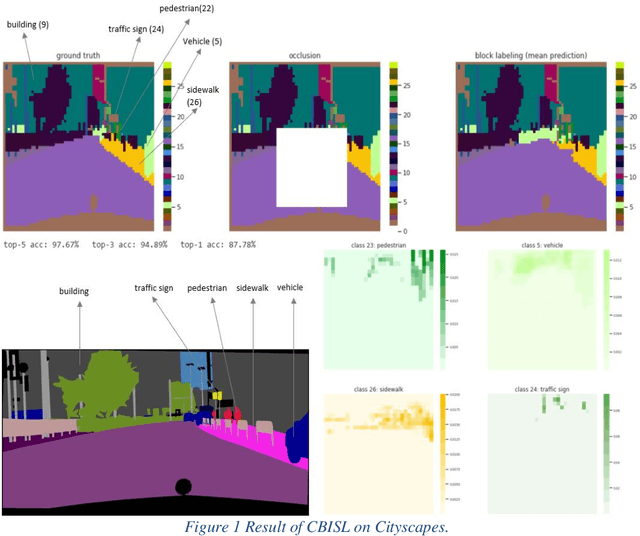
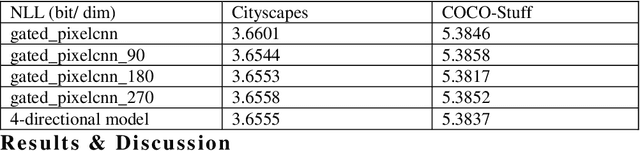
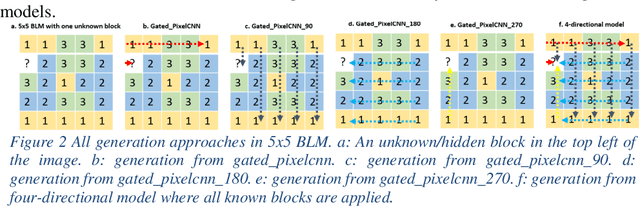
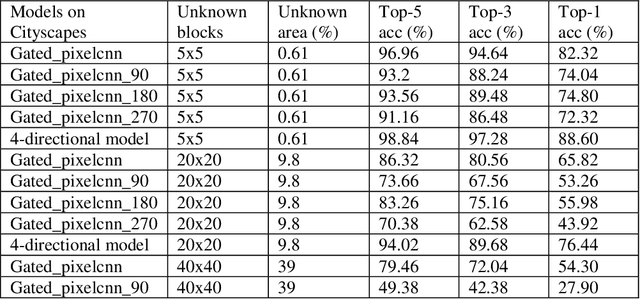
Working with images, one often faces problems with incomplete or unclear information. Image inpainting can be used to restore missing image regions but focuses, however, on low-level image features such as pixel intensity, pixel gradient orientation, and color. This paper aims to recover semantic image features (objects and positions) in images. Based on published gated PixelCNNs, we demonstrate a new approach referred to as quadro-directional PixelCNN to recover missing objects and return probable positions for objects based on the context. We call this approach context-based image segment labeling (CBISL). The results suggest that our four-directional model outperforms one-directional models (gated PixelCNN) and returns a human-comparable performance.