 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Detection on Technical Drawings for the Digitization of Brown-field Processes
Paper and Code
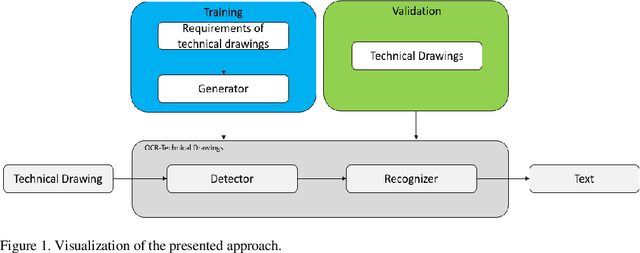
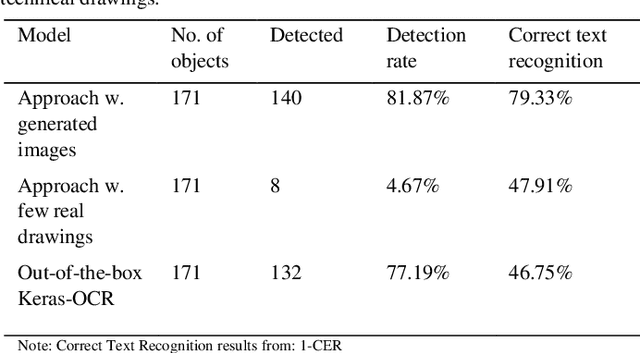
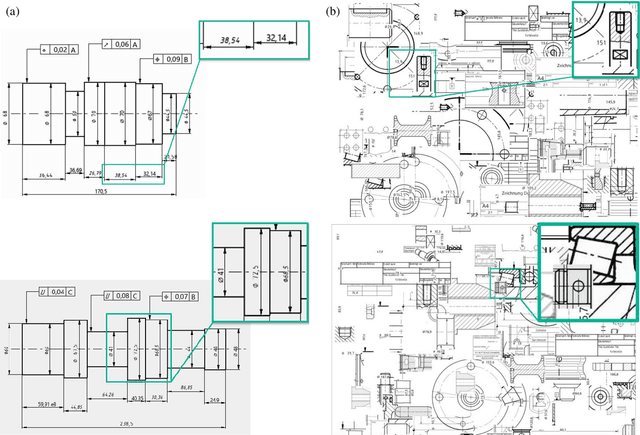

This paper addresses the issue of autonomously detecting text on technical drawings. The detection of text on technical drawings is a critical step towards autonomous production machines, especially for brown-field processes, where no closed CAD-CAM solutions are available yet. Automating the process of reading and detecting text on technical drawings reduces the effort for handling inefficient media interruptions due to paper-based processes, which are often todays quasi-standard in brown-field processes. However, there are no reliable methods available yet to solve the issue of automatically detecting text on technical drawings. The unreliable detection of the contents on technical drawings using classical detection and object character recognition (OCR) tools is mainly due to the limited number of technical drawings and the captcha-like structure of the contents. Text is often combined with unknown symbols and interruptions by lines. Additionally, due to intellectual property rights and technical know-how issues, there are no out-of-the box training datasets available in the literature to train such models. This paper combines a domain knowledge-based generator to generate realistic technical drawings with a state-of-the-art object detection model to solve the issue of detecting text on technical drawings. The generator yields artificial technical drawings in a large variety and can be considered as a data augmentation generator. These artificial drawings are used for training, while the model is tested on real data. The authors show that artificially generated data of technical drawings improve the detection quality with an increasing number of drawings.