 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting automatically the layout of clinical documents to enhance the performances of downstream natural language processing
May 23, 2023


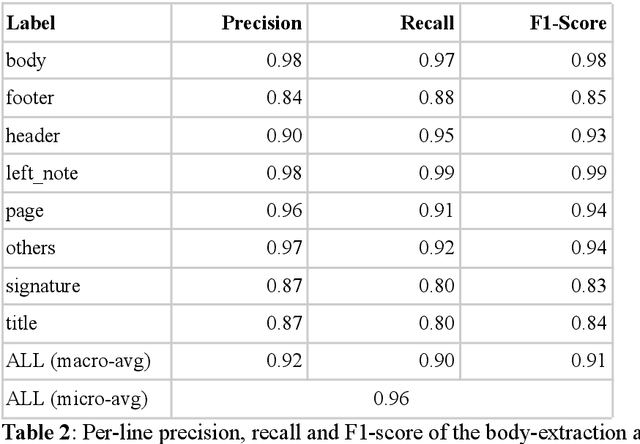
Objective:Develop and validate an algorithm for analyzing the layout of PDF clinical documents to improve the performance of downstream natural language processing tasks. Materials and Methods: We designed an algorithm to process clinical PDF documents and extract only clinically relevant text. The algorithm consists of several steps: initial text extraction using a PDF parser, followed by classification into categories such as body text, left notes, and footers using a Transformer deep neural network architecture, and finally an aggregation step to compile the lines of a given label in the text. We evaluated the technical performance of the body text extraction algorithm by applying it to a random sample of documents that were annotated. Medical performance was evaluated by examining the extraction of medical concepts of interest from the text in their respective sections. Finally, we tested an end-to-end system on a medical use case of automatic detection of acute infection described in the hospital report. Results:Our algorithm achieved per-line precision, recall, and F1 score of 98.4, 97.0, and 97.7, respectively, for body line extraction. The precision, recall, and F1 score per document for the acute infection detection algorithm were 82.54 (95CI 72.86-91.60), 85.24 (95CI 76.61-93.70), 83.87 (95CI 76, 92-90.08) with exploitation of the results of the advanced body extraction algorithm, respectively. Conclusion:We have developed and validated a system for extracting body text from clinical documents in PDF format by identifying their layout. We were able to demonstrate that this preprocessing allowed us to obtain better performances for a common downstream task, i.e., the extraction of medical concepts in their respective sections, thus proving the interest of this method on a clinical use case.
Development and validation of a natural language processing algorithm to pseudonymize documents in the context of a clinical data warehouse
Mar 23, 2023The objective of this study is to address the critical issue of de-identification of clinical reports in order to allow access to data for research purposes, while ensuring patient privacy. The study highlights the difficulties faced in sharing tools and resources in this domain and presents the experience of the Greater Paris University Hospitals (AP-HP) in implementing a systematic pseudonymization of text documents from its Clinical Data Warehouse. We annotated a corpus of clinical documents according to 12 types of identifying entities, and built a hybrid system, merging the results of a deep learning model as well as manual rules. Our results show an overall performance of 0.99 of F1-score. We discuss implementation choices and present experiments to better understand the effort involved in such a task, including dataset size, document types, language models, or rule addition. We share guidelines and code under a 3-Clause BSD license.
Learning structures of the French clinical language:development and validation of word embedding models using 21 million clinical reports from electronic health records
Jul 26, 2022
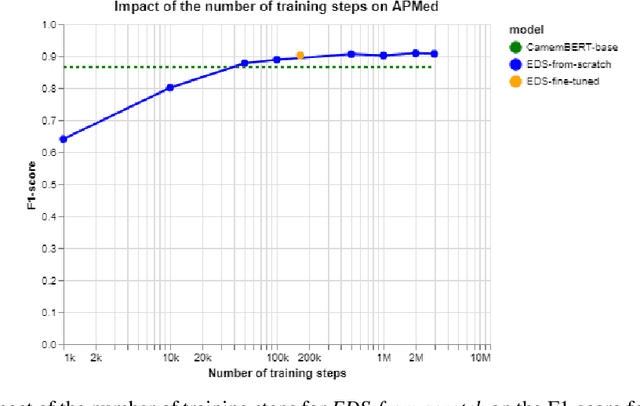

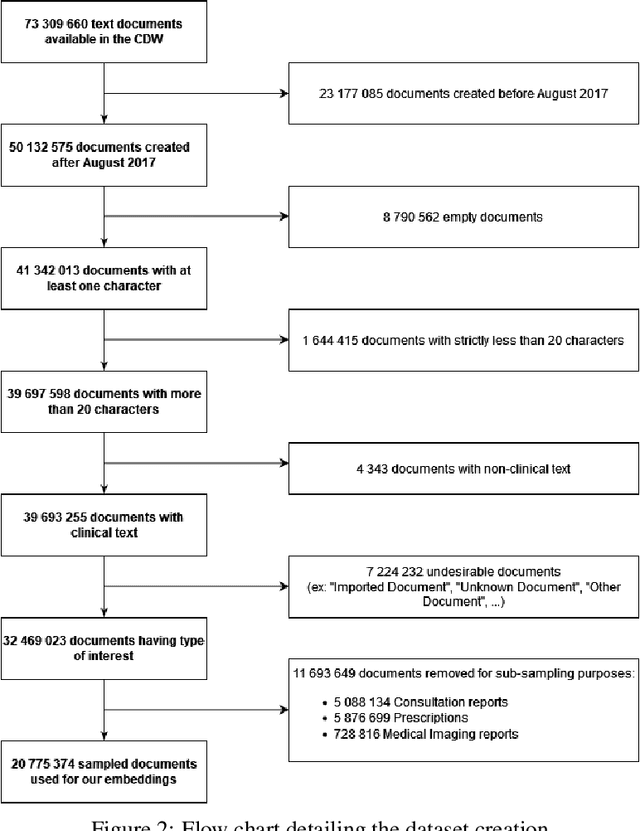
Background Clinical studies using real-world data may benefit from exploiting clinical reports, a particularly rich albeit unstructured medium. To that end, natural language processing can extract relevant information. Methods based on transfer learning using pre-trained language models have achieved state-of-the-art results in most NLP applications; however, publicly available models lack exposure to speciality-languages, especially in the medical field. Objective We aimed to evaluate the impact of adapting a language model to French clinical reports on downstream medical NLP tasks. Methods We leveraged a corpus of 21M clinical reports collected from August 2017 to July 2021 at the Greater Paris University Hospitals (APHP) to produce two CamemBERT architectures on speciality language: one retrained from scratch and the other using CamemBERT as its initialisation. We used two French annotated medical datasets to compare our language models to the original CamemBERT network, evaluating the statistical significance of improvement with the Wilcoxon test. Results Our models pretrained on clinical reports increased the average F1-score on APMed (an APHP-specific task) by 3 percentage points to 91%, a statistically significant improvement. They also achieved performance comparable to the original CamemBERT on QUAERO. These results hold true for the fine-tuned and from-scratch versions alike, starting from very few pre-training samples. Conclusions We confirm previous literature showing that adapting generalist pre-train language models such as CamenBERT on speciality corpora improves their performance for downstream clinical NLP tasks. Our results suggest that retraining from scratch does not induce a statistically significant performance gain compared to fine-tuning.
Adaptive Deep Kernel Learning
May 28, 2019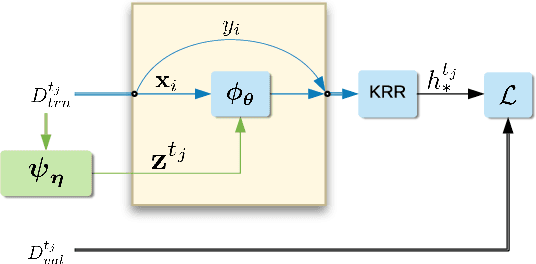

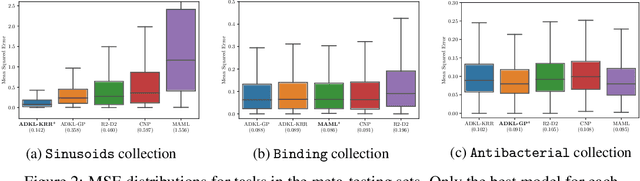
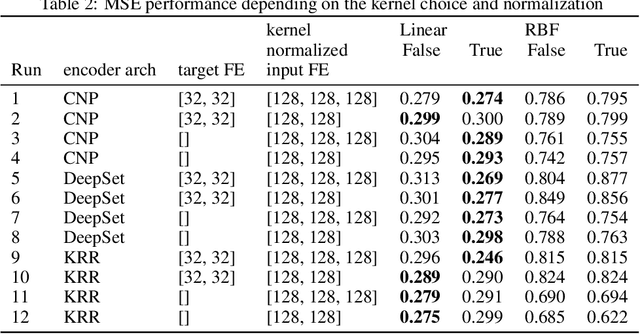
Deep kernel learning provides an elegant and principled framework for combining the structural properties of deep learning algorithms with the flexibility of kernel methods. By means of a deep neural network, it consists of learning a kernel operator which is combined with a differentiable kernel algorithm for inference. While previous work within this framework has mostly explored learning a single kernel for large datasets, we focus herein on learning a kernel family for a variety of tasks in few-shot regression settings. Compared to single deep kernel learning, our novel algorithm permits finding the appropriate kernel for each task during inference, rather than using the same for all tasks. As such, our algorithm performs more effectively with complex task distributions in few-shot learning, which we demonstrate by benchmarking against existing state-of-the-art algorithms using real-world, few-shot regression tasks related to drug discovery.