 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongBEL: Long-Context and Document-Consistent Biomedical Entity Linking
May 13, 2026Biomedical entity linking maps textual mentions to concepts in structured knowledge bases such as UMLS or SNOMED CT. Most existing systems link each mention independently, using only the mention or its surrounding sentence. This ignores dependencies between mentions in the same document and can lead to inconsistent predictions, especially when the same concept appears under different surface forms. We introduce LongBEL, a document-level generative framework that combines full-document context with a memory of previous predictions. To make this memory robust, LongBEL is trained with cross-validated predictions rather than gold labels, reducing the mismatch between training and inference and limiting cascading errors. Experiments on five biomedical benchmarks across English, French, and Spanish show that LongBEL improves over sentence-level generative baselines, with the largest gains on datasets where concepts frequently recur within documents. An ensemble of local, global, and memory-based variants achieves the best results across all benchmarks. Further analysis shows that the largest gains occur on recurring concepts, suggesting that LongBEL mainly improves document-level consistency rather than isolated mention disambiguation.
SynCABEL: Synthetic Contextualized Augmentation for Biomedical Entity Linking
Jan 27, 2026We present SynCABEL (Synthetic Contextualized Augmentation for Biomedical Entity Linking), a framework that addresses a central bottleneck in supervised biomedical entity linking (BEL): the scarcity of expert-annotated training data. SynCABEL leverages large language models to generate context-rich synthetic training examples for all candidate concepts in a target knowledge base, providing broad supervision without manual annotation. We demonstrate that SynCABEL, when combined with decoder-only models and guided inference establish new state-of-the-art results across three widely used multilingual benchmarks: MedMentions for English, QUAERO for French, and SPACCC for Spanish. Evaluating data efficiency, we show that SynCABEL reaches the performance of full human supervision using up to 60% less annotated data, substantially reducing reliance on labor-intensive and costly expert labeling. Finally, acknowledging that standard evaluation based on exact code matching often underestimates clinically valid predictions due to ontology redundancy, we introduce an LLM-as-a-judge protocol. This analysis reveals that SynCABEL significantly improves the rate of clinically valid predictions. Our synthetic datasets, models, and code are released to support reproducibility and future research.
Impact of translation on biomedical information extraction from real-life clinical notes
Jun 03, 2023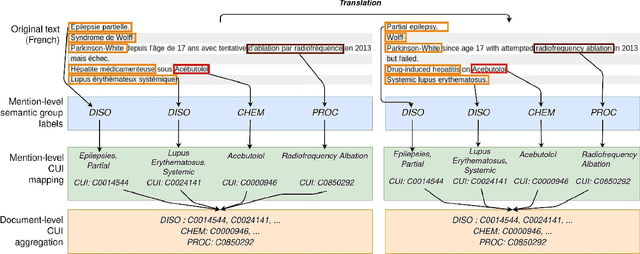
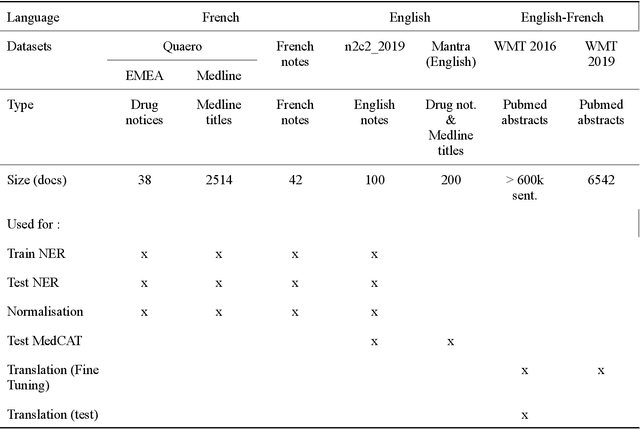
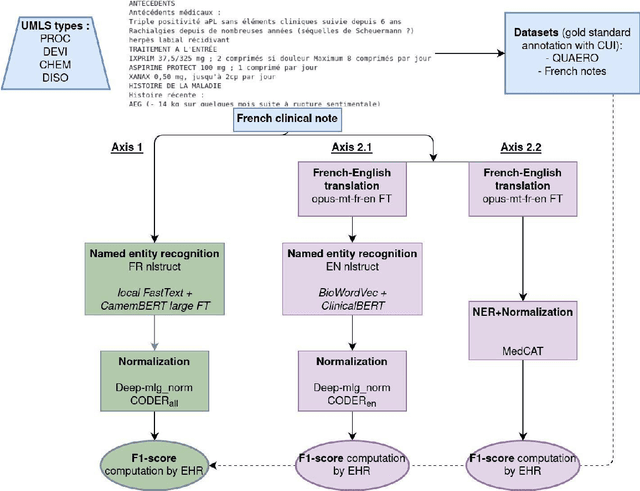
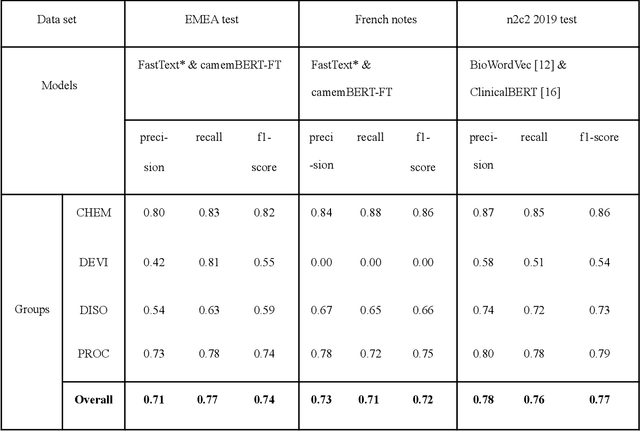
The objective of our study is to determine whether using English tools to extract and normalize French medical concepts on translations provides comparable performance to French models trained on a set of annotated French clinical notes. We compare two methods: a method involving French language models and a method involving English language models. For the native French method, the Named Entity Recognition (NER) and normalization steps are performed separately. For the translated English method, after the first translation step, we compare a two-step method and a terminology-oriented method that performs extraction and normalization at the same time. We used French, English and bilingual annotated datasets to evaluate all steps (NER, normalization and translation) of our algorithms. Concerning the results, the native French method performs better than the translated English one with a global f1 score of 0.51 [0.47;0.55] against 0.39 [0.34;0.44] and 0.38 [0.36;0.40] for the two English methods tested. In conclusion, despite the recent improvement of the translation models, there is a significant performance difference between the two approaches in favor of the native French method which is more efficient on French medical texts, even with few annotated documents.
Detecting automatically the layout of clinical documents to enhance the performances of downstream natural language processing
May 23, 2023


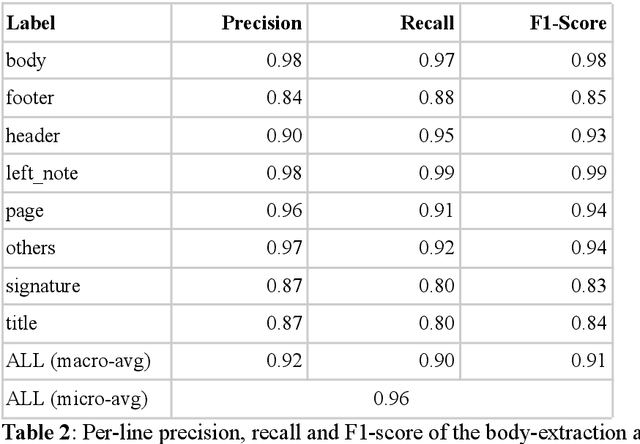
Objective:Develop and validate an algorithm for analyzing the layout of PDF clinical documents to improve the performance of downstream natural language processing tasks. Materials and Methods: We designed an algorithm to process clinical PDF documents and extract only clinically relevant text. The algorithm consists of several steps: initial text extraction using a PDF parser, followed by classification into categories such as body text, left notes, and footers using a Transformer deep neural network architecture, and finally an aggregation step to compile the lines of a given label in the text. We evaluated the technical performance of the body text extraction algorithm by applying it to a random sample of documents that were annotated. Medical performance was evaluated by examining the extraction of medical concepts of interest from the text in their respective sections. Finally, we tested an end-to-end system on a medical use case of automatic detection of acute infection described in the hospital report. Results:Our algorithm achieved per-line precision, recall, and F1 score of 98.4, 97.0, and 97.7, respectively, for body line extraction. The precision, recall, and F1 score per document for the acute infection detection algorithm were 82.54 (95CI 72.86-91.60), 85.24 (95CI 76.61-93.70), 83.87 (95CI 76, 92-90.08) with exploitation of the results of the advanced body extraction algorithm, respectively. Conclusion:We have developed and validated a system for extracting body text from clinical documents in PDF format by identifying their layout. We were able to demonstrate that this preprocessing allowed us to obtain better performances for a common downstream task, i.e., the extraction of medical concepts in their respective sections, thus proving the interest of this method on a clinical use case.