 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks on Symmetric Spaces of Noncompact Type
Jan 03, 2026Recent works have demonstrated promising performances of neural networks on hyperbolic spaces and symmetric positive definite (SPD) manifolds. These spaces belong to a family of Riemannian manifolds referred to as symmetric spaces of noncompact type. In this paper, we propose a novel approach for developing neural networks on such spaces. Our approach relies on a unified formulation of the distance from a point to a hyperplane on the considered spaces. We show that some existing formulations of the point-to-hyperplane distance can be recovered by our approach under specific settings. Furthermore, we derive a closed-form expression for the point-to-hyperplane distance in higher-rank symmetric spaces of noncompact type equipped with G-invariant Riemannian metrics. The derived distance then serves as a tool to design fully-connected (FC) layers and an attention mechanism for neural networks on the considered spaces. Our approach is validated on challenging benchmarks for image classification, electroencephalogram (EEG) signal classification, image generation, and natural language inference.
Siegel Neural Networks
Nov 12, 2025Riemannian symmetric spaces (RSS) such as hyperbolic spaces and symmetric positive definite (SPD) manifolds have become popular spaces for representation learning. In this paper, we propose a novel approach for building discriminative neural networks on Siegel spaces, a family of RSS that is largely unexplored in machine learning tasks. For classification applications, one focus of recent works is the construction of multiclass logistic regression (MLR) and fully-connected (FC) layers for hyperbolic and SPD neural networks. Here we show how to build such layers for Siegel neural networks. Our approach relies on the quotient structure of those spaces and the notation of vector-valued distance on RSS. We demonstrate the relevance of our approach on two applications, i.e., radar clutter classification and node classification. Our results successfully demonstrate state-of-the-art performance across all datasets.
Matrix Manifold Neural Networks++
May 29, 2024

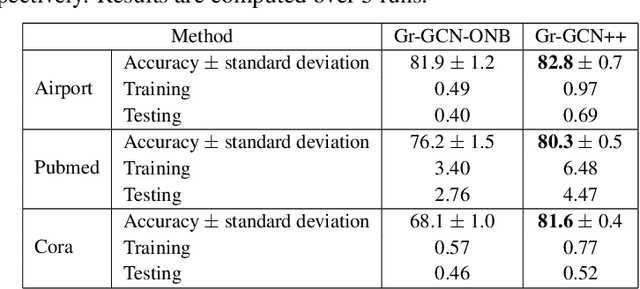

Deep neural networks (DNNs) on Riemannian manifolds have garnered increasing interest in various applied areas. For instance, DNNs on spherical and hyperbolic manifolds have been designed to solve a wide range of computer vision and nature language processing tasks. One of the key factors that contribute to the success of these networks is that spherical and hyperbolic manifolds have the rich algebraic structures of gyrogroups and gyrovector spaces. This enables principled and effective generalizations of the most successful DNNs to these manifolds. Recently, some works have shown that many concepts in the theory of gyrogroups and gyrovector spaces can also be generalized to matrix manifolds such as Symmetric Positive Definite (SPD) and Grassmann manifolds. As a result, some building blocks for SPD and Grassmann neural networks, e.g., isometric models and multinomial logistic regression (MLR) can be derived in a way that is fully analogous to their spherical and hyperbolic counterparts. Building upon these works, we design fully-connected (FC) and convolutional layers for SPD neural networks. We also develop MLR on Symmetric Positive Semi-definite (SPSD) manifolds, and propose a method for performing backpropagation with the Grassmann logarithmic map in the projector perspective. We demonstrate the effectiveness of the proposed approach in the human action recognition and node classification tasks.
Anomaly Detection via Multi-Scale Contrasted Memory
Nov 16, 2022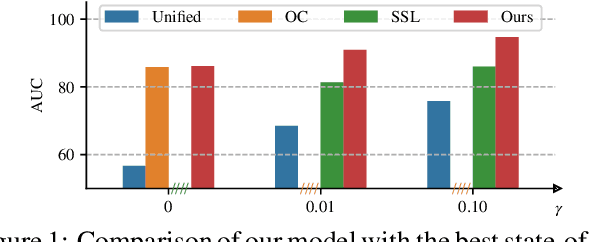
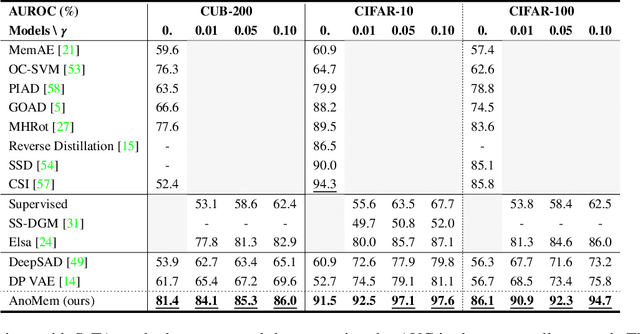
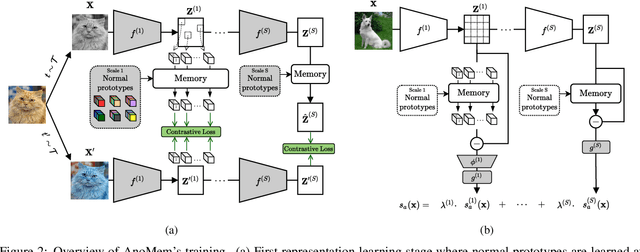
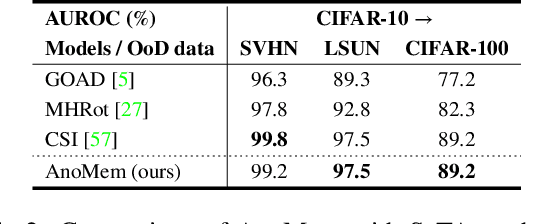
Deep anomaly detection (AD) aims to provide robust and efficient classifiers for one-class and unbalanced settings. However current AD models still struggle on edge-case normal samples and are often unable to keep high performance over different scales of anomalies. Moreover, there currently does not exist a unified framework efficiently covering both one-class and unbalanced learnings. In the light of these limitations, we introduce a new two-stage anomaly detector which memorizes during training multi-scale normal prototypes to compute an anomaly deviation score. First, we simultaneously learn representations and memory modules on multiple scales using a novel memory-augmented contrastive learning. Then, we train an anomaly distance detector on the spatial deviation maps between prototypes and observations. Our model highly improves the state-of-the-art performance on a wide range of object, style and local anomalies with up to 35\% error relative improvement on CIFAR-10. It is also the first model to keep high performance across the one-class and unbalanced settings.
Efficient Anomaly Detection Using Self-Supervised Multi-Cue Tasks
Nov 24, 2021
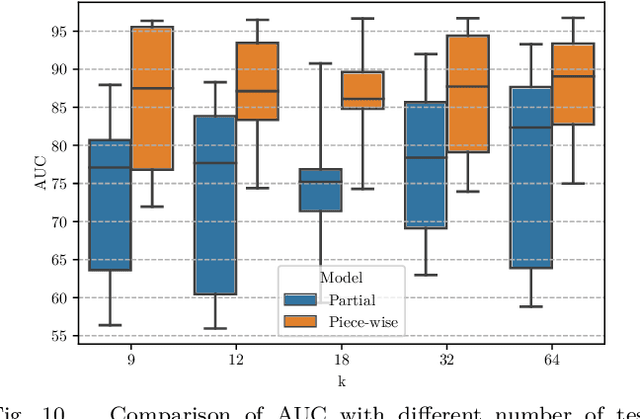
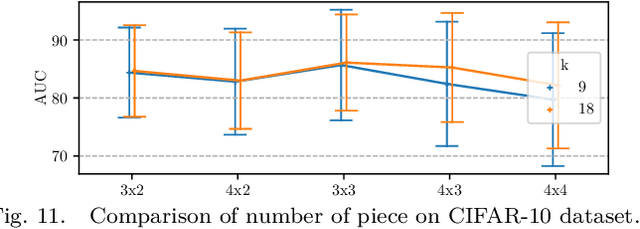
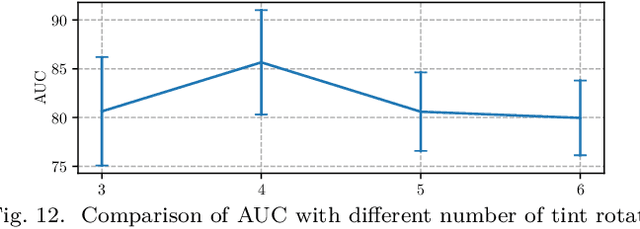
Deep anomaly detection has proven to be an efficient and robust approach in several fields. The introduction of self-supervised learning has greatly helped many methods including anomaly detection where simple geometric transformation recognition tasks are used. However these methods do not perform well on fine-grained problems since they lack finer features and are usually highly dependent on the anomaly type. In this paper, we explore each step of self-supervised anomaly detection with pretext tasks. First, we introduce novel discriminative and generative tasks which focus on different visual cues. A piece-wise jigsaw puzzle task focuses on structure cues, while a tint rotation recognition is used on each piece for colorimetry and a partial re-colorization task is performed. In order for the re-colorization task to focus more on the object rather than on the background, we propose to include the contextual color information of the image border. Then, we present a new out-of-distribution detection function and highlight its better stability compared to other out-of-distribution detection methods. Along with it, we also experiment different score fusion functions. Finally, we evaluate our method on a comprehensive anomaly detection protocol composed of object anomalies with classical object recognition, style anomalies with fine-grained classification and local anomalies with face anti-spoofing datasets. Our model can more accurately learn highly discriminative features using these self-supervised tasks. It outperforms state-of-the-art with up to 36% relative error improvement on object anomalies and 40% on face anti-spoofing problems.
Fine-grained Anomaly Detection via Multi-task Self-Supervision
Apr 20, 2021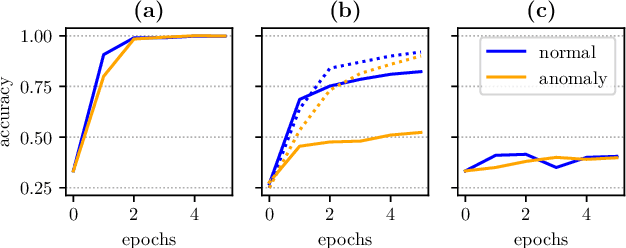
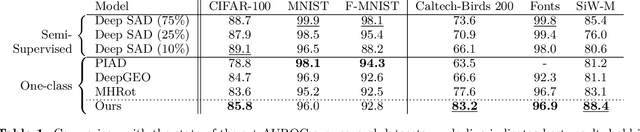
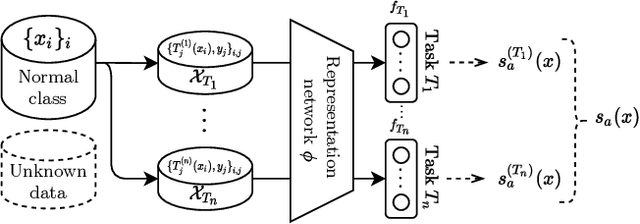
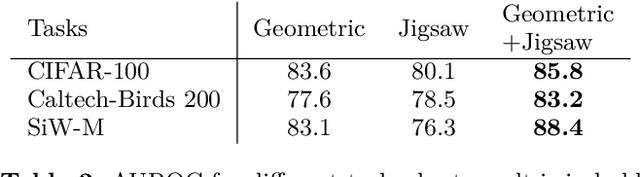
Detecting anomalies using deep learning has become a major challenge over the last years, and is becoming increasingly promising in several fields. The introduction of self-supervised learning has greatly helped many methods including anomaly detection where simple geometric transformation recognition tasks are used. However these methods do not perform well on fine-grained problems since they lack finer features. By combining in a multi-task framework high-scale shape features oriented task with low-scale fine features oriented task, our method greatly improves fine-grained anomaly detection. It outperforms state-of-the-art with up to 31% relative error reduction measured with AUROC on various anomaly detection problems.
Improving Deep Metric Learning with Virtual Classes and Examples Mining
Jun 11, 2020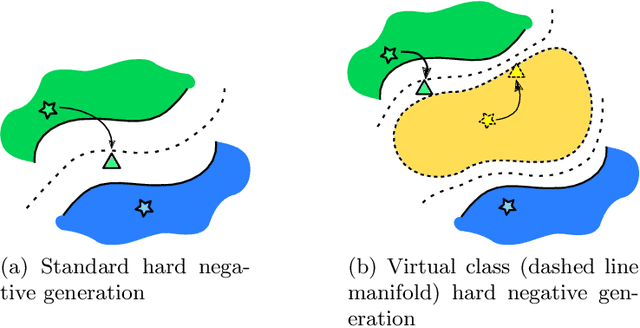

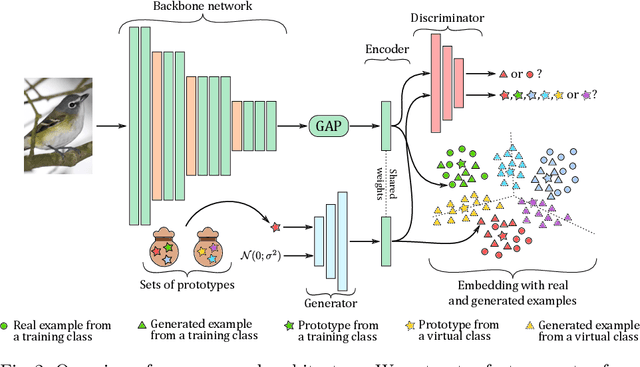
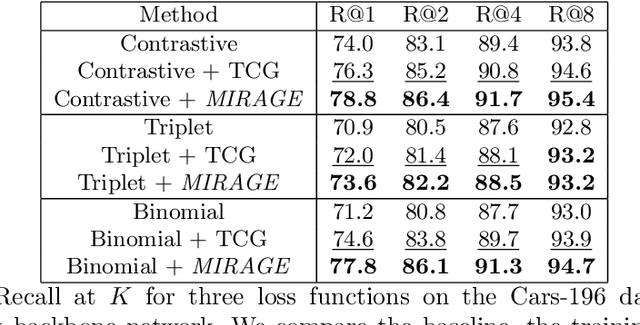
In deep metric learning, the training procedure relies on sampling informative tuples. However, as the training procedure progresses, it becomes nearly impossible to sample relevant hard negative examples without proper mining strategies or generation-based methods. Recent work on hard negative generation have shown great promises to solve the mining problem. However, this generation process is difficult to tune and often leads to incorrectly labelled examples. To tackle this issue, we introduce MIRAGE, a generation-based method that relies on virtual classes entirely composed of generated examples that act as buffer areas between the training classes. We empirically show that virtual classes significantly improve the results on popular datasets (Cub-200-2011, Cars-196 and Stanford Online Products) compared to other generation methods.
DIABLO: Dictionary-based Attention Block for Deep Metric Learning
Apr 30, 2020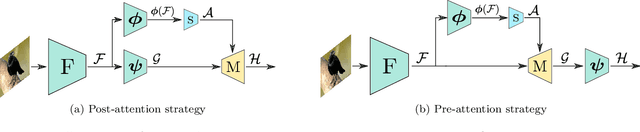
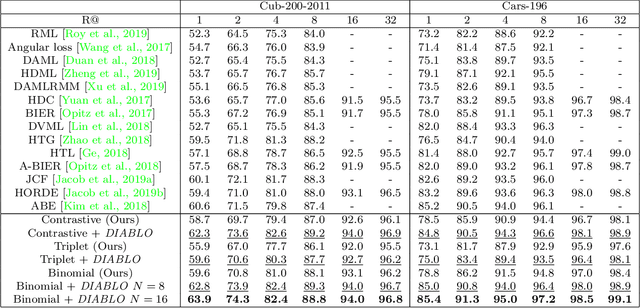
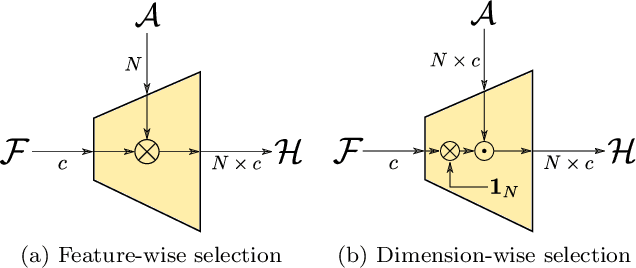

Recent breakthroughs in representation learning of unseen classes and examples have been made in deep metric learning by training at the same time the image representations and a corresponding metric with deep networks. Recent contributions mostly address the training part (loss functions, sampling strategies, etc.), while a few works focus on improving the discriminative power of the image representation. In this paper, we propose DIABLO, a dictionary-based attention method for image embedding. DIABLO produces richer representations by aggregating only visually-related features together while being easier to train than other attention-based methods in deep metric learning. This is experimentally confirmed on four deep metric learning datasets (Cub-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval) for which DIABLO shows state-of-the-art performances.
Metric Learning With HORDE: High-Order Regularizer for Deep Embeddings
Aug 07, 2019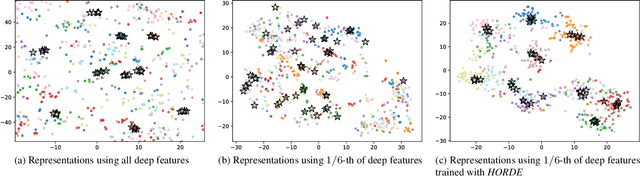
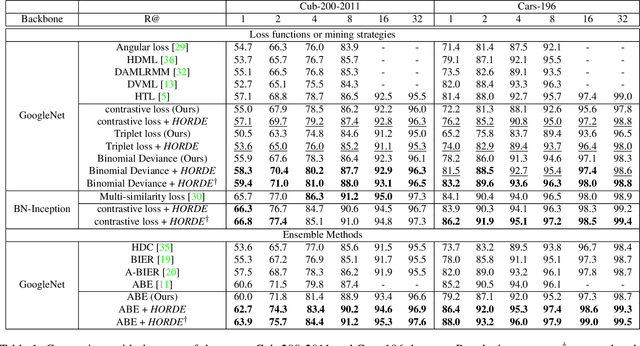
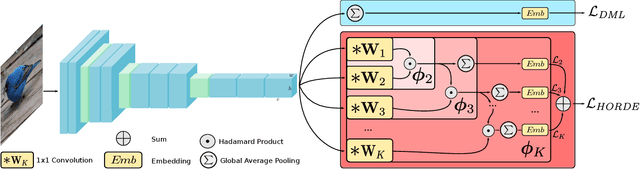

Learning an effective similarity measure between image representations is key to the success of recent advances in visual search tasks (e.g. verification or zero-shot learning). Although the metric learning part is well addressed, this metric is usually computed over the average of the extracted deep features. This representation is then trained to be discriminative. However, these deep features tend to be scattered across the feature space. Consequently, the representations are not robust to outliers, object occlusions, background variations, etc. In this paper, we tackle this scattering problem with a distribution-aware regularization named HORDE. This regularizer enforces visually-close images to have deep features with the same distribution which are well localized in the feature space. We provide a theoretical analysis supporting this regularization effect. We also show the effectiveness of our approach by obtaining state-of-the-art results on 4 well-known datasets (Cub-200-2011, Cars-196, Stanford Online Products and Inshop Clothes Retrieval).
Efficient Codebook and Factorization for Second Order Representation Learning
Jun 05, 2019
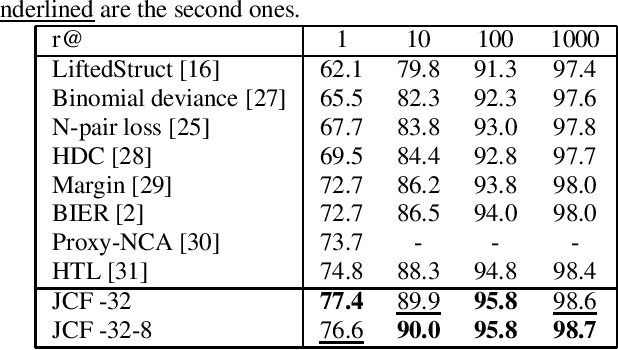

Learning rich and compact representations is an open topic in many fields such as object recognition or image retrieval. Deep neural networks have made a major breakthrough during the last few years for these tasks but their representations are not necessary as rich as needed nor as compact as expected. To build richer representations, high order statistics have been exploited and have shown excellent performances, but they produce higher dimensional features. While this drawback has been partially addressed with factorization schemes, the original compactness of first order models has never been retrieved, or at the cost of a strong performance decrease. Our method, by jointly integrating codebook strategy to factorization scheme, is able to produce compact representations while keeping the second order performances with few additional parameters. This formulation leads to state-of-the-art results on three image retrieval datasets.