 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Learning With HORDE: High-Order Regularizer for Deep Embeddings
Paper and Code
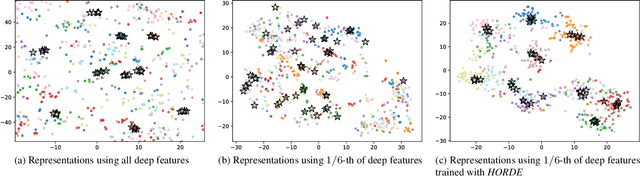
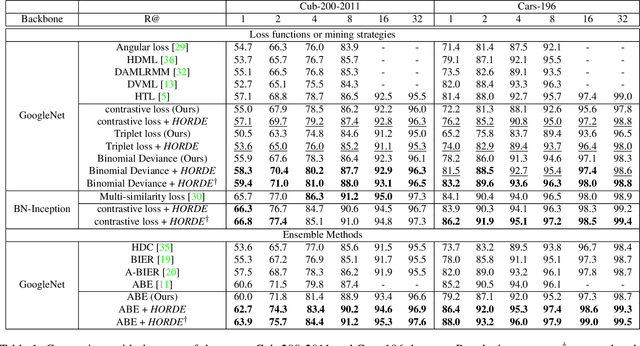
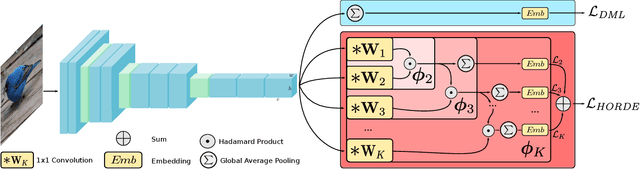

Learning an effective similarity measure between image representations is key to the success of recent advances in visual search tasks (e.g. verification or zero-shot learning). Although the metric learning part is well addressed, this metric is usually computed over the average of the extracted deep features. This representation is then trained to be discriminative. However, these deep features tend to be scattered across the feature space. Consequently, the representations are not robust to outliers, object occlusions, background variations, etc. In this paper, we tackle this scattering problem with a distribution-aware regularization named HORDE. This regularizer enforces visually-close images to have deep features with the same distribution which are well localized in the feature space. We provide a theoretical analysis supporting this regularization effect. We also show the effectiveness of our approach by obtaining state-of-the-art results on 4 well-known datasets (Cub-200-2011, Cars-196, Stanford Online Products and Inshop Clothes Retrieval).