 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Metric Learning with Virtual Classes and Examples Mining
Jun 11, 2020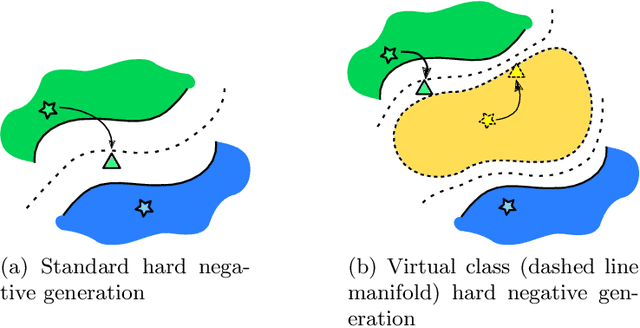

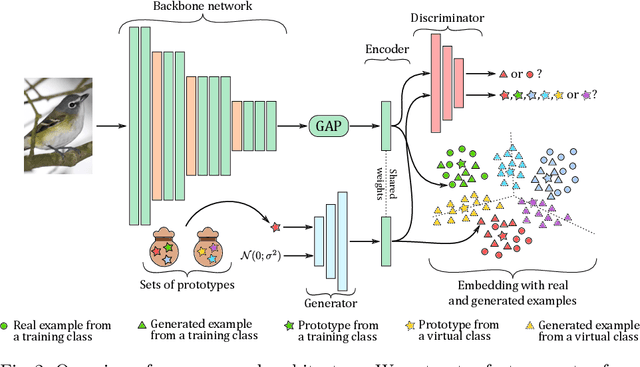
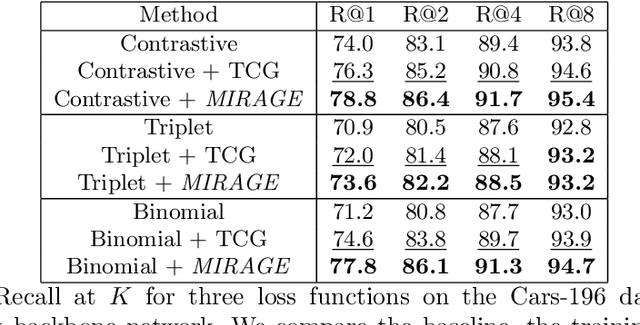
In deep metric learning, the training procedure relies on sampling informative tuples. However, as the training procedure progresses, it becomes nearly impossible to sample relevant hard negative examples without proper mining strategies or generation-based methods. Recent work on hard negative generation have shown great promises to solve the mining problem. However, this generation process is difficult to tune and often leads to incorrectly labelled examples. To tackle this issue, we introduce MIRAGE, a generation-based method that relies on virtual classes entirely composed of generated examples that act as buffer areas between the training classes. We empirically show that virtual classes significantly improve the results on popular datasets (Cub-200-2011, Cars-196 and Stanford Online Products) compared to other generation methods.
DIABLO: Dictionary-based Attention Block for Deep Metric Learning
Apr 30, 2020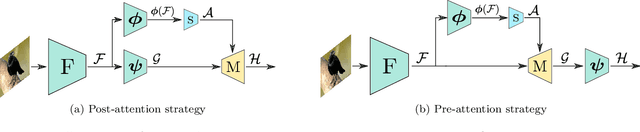
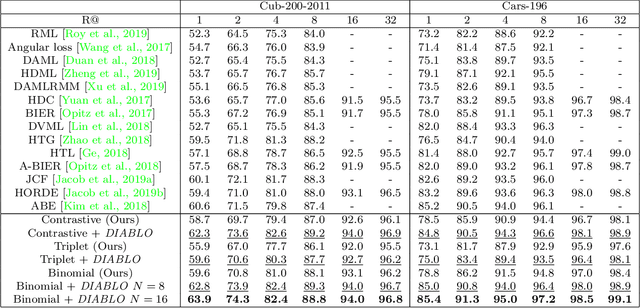
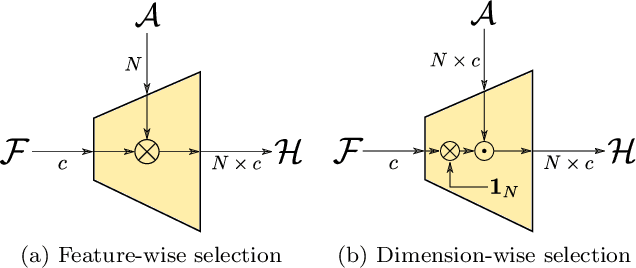

Recent breakthroughs in representation learning of unseen classes and examples have been made in deep metric learning by training at the same time the image representations and a corresponding metric with deep networks. Recent contributions mostly address the training part (loss functions, sampling strategies, etc.), while a few works focus on improving the discriminative power of the image representation. In this paper, we propose DIABLO, a dictionary-based attention method for image embedding. DIABLO produces richer representations by aggregating only visually-related features together while being easier to train than other attention-based methods in deep metric learning. This is experimentally confirmed on four deep metric learning datasets (Cub-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval) for which DIABLO shows state-of-the-art performances.
Metric Learning With HORDE: High-Order Regularizer for Deep Embeddings
Aug 07, 2019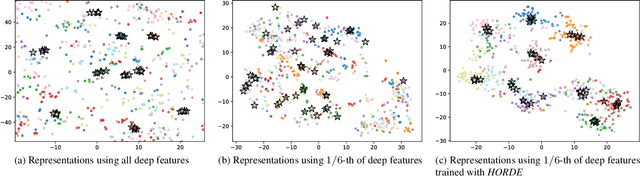
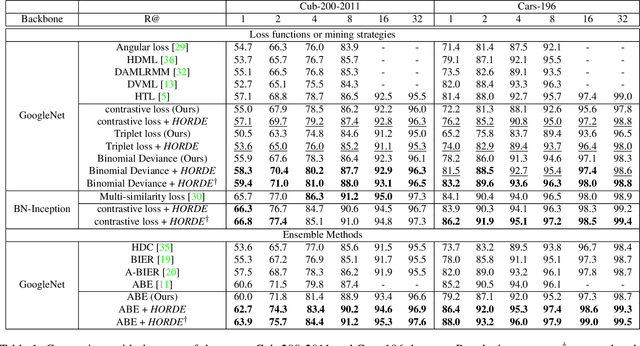
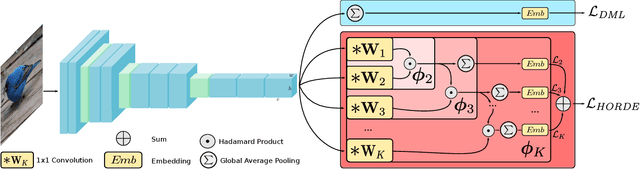

Learning an effective similarity measure between image representations is key to the success of recent advances in visual search tasks (e.g. verification or zero-shot learning). Although the metric learning part is well addressed, this metric is usually computed over the average of the extracted deep features. This representation is then trained to be discriminative. However, these deep features tend to be scattered across the feature space. Consequently, the representations are not robust to outliers, object occlusions, background variations, etc. In this paper, we tackle this scattering problem with a distribution-aware regularization named HORDE. This regularizer enforces visually-close images to have deep features with the same distribution which are well localized in the feature space. We provide a theoretical analysis supporting this regularization effect. We also show the effectiveness of our approach by obtaining state-of-the-art results on 4 well-known datasets (Cub-200-2011, Cars-196, Stanford Online Products and Inshop Clothes Retrieval).
Efficient Codebook and Factorization for Second Order Representation Learning
Jun 05, 2019
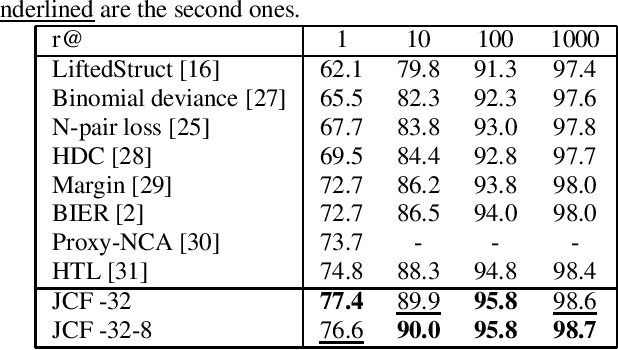

Learning rich and compact representations is an open topic in many fields such as object recognition or image retrieval. Deep neural networks have made a major breakthrough during the last few years for these tasks but their representations are not necessary as rich as needed nor as compact as expected. To build richer representations, high order statistics have been exploited and have shown excellent performances, but they produce higher dimensional features. While this drawback has been partially addressed with factorization schemes, the original compactness of first order models has never been retrieved, or at the cost of a strong performance decrease. Our method, by jointly integrating codebook strategy to factorization scheme, is able to produce compact representations while keeping the second order performances with few additional parameters. This formulation leads to state-of-the-art results on three image retrieval datasets.
Leveraging Implicit Spatial Information in Global Features for Image Retrieval
Jun 23, 2018
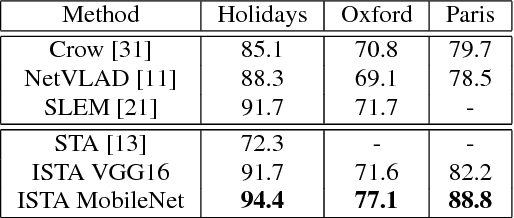

Most image retrieval methods use global features that aggregate local distinctive patterns into a single representation. However, the aggregation process destroys the relative spatial information by considering orderless sets of local descriptors. We propose to integrate relative spatial information into the aggregation process by taking into account co-occurrences of local patterns in a tensor framework. The resulting signature called Improved Spatial Tensor Aggregation (ISTA) is able to reach state of the art performances on well known datasets such as Holidays, Oxford5k and Paris6k.