 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIABLO: Dictionary-based Attention Block for Deep Metric Learning
Paper and Code
Apr 30, 2020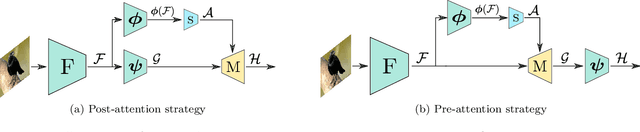
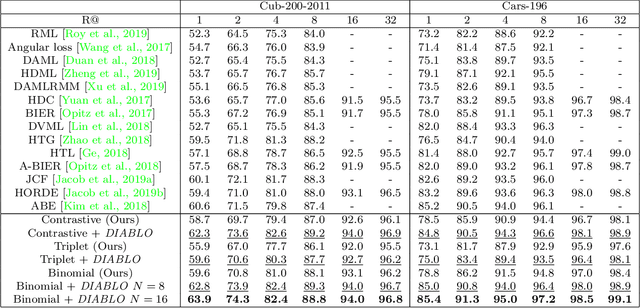
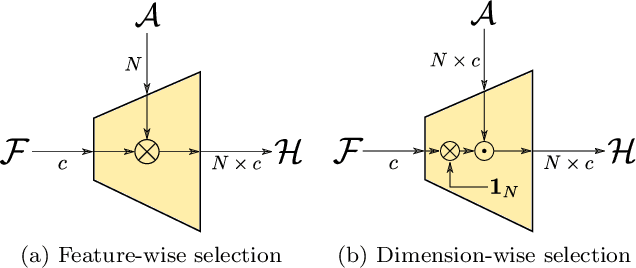

Recent breakthroughs in representation learning of unseen classes and examples have been made in deep metric learning by training at the same time the image representations and a corresponding metric with deep networks. Recent contributions mostly address the training part (loss functions, sampling strategies, etc.), while a few works focus on improving the discriminative power of the image representation. In this paper, we propose DIABLO, a dictionary-based attention method for image embedding. DIABLO produces richer representations by aggregating only visually-related features together while being easier to train than other attention-based methods in deep metric learning. This is experimentally confirmed on four deep metric learning datasets (Cub-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval) for which DIABLO shows state-of-the-art performances.