 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Higher-Order Mixed Memberships via the $\ell_{2,\infty}$ Tensor Perturbation Bound
Dec 16, 2022Higher-order multiway data is ubiquitous in machine learning and statistics and often exhibits community-like structures, where each component (node) along each different mode has a community membership associated with it. In this paper we propose the tensor mixed-membership blockmodel, a generalization of the tensor blockmodel positing that memberships need not be discrete, but instead are convex combinations of latent communities. We establish the identifiability of our model and propose a computationally efficient estimation procedure based on the higher-order orthogonal iteration algorithm (HOOI) for tensor SVD composed with a simplex corner-finding algorithm. We then demonstrate the consistency of our estimation procedure by providing a per-node error bound, which showcases the effect of higher-order structures on estimation accuracy. To prove our consistency result, we develop the $\ell_{2,\infty}$ tensor perturbation bound for HOOI under independent, possibly heteroskedastic, subgaussian noise that may be of independent interest. Our analysis uses a novel leave-one-out construction for the iterates, and our bounds depend only on spectral properties of the underlying low-rank tensor under nearly optimal signal-to-noise ratio conditions such that tensor SVD is computationally feasible. Whereas other leave-one-out analyses typically focus on sequences constructed by analyzing the output of a given algorithm with a small part of the noise removed, our leave-one-out analysis constructions use both the previous iterates and the additional tensor structure to eliminate a potential additional source of error. Finally, we apply our methodology to real and simulated data, including applications to two flight datasets and a trade network dataset, demonstrating some effects not identifiable from the model with discrete community memberships.
Learning Good State and Action Representations via Tensor Decomposition
May 03, 2021



The transition kernel of a continuous-state-action Markov decision process (MDP) admits a natural tensor structure. This paper proposes a tensor-inspired unsupervised learning method to identify meaningful low-dimensional state and action representations from empirical trajectories. The method exploits the MDP's tensor structure by kernelization, importance sampling and low-Tucker-rank approximation. This method can be further used to cluster states and actions respectively and find the best discrete MDP abstraction. We provide sharp statistical error bounds for tensor concentration and the preservation of diffusion distance after embedding.
An Optimal Statistical and Computational Framework for Generalized Tensor Estimation
Feb 26, 2020
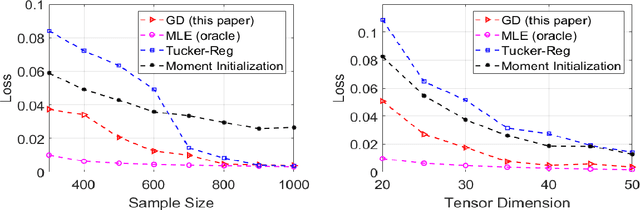
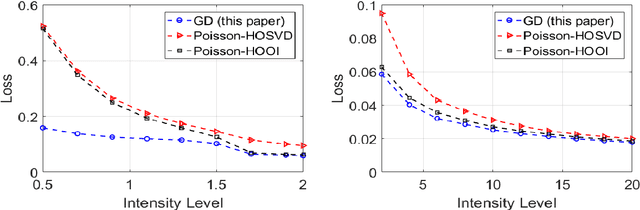
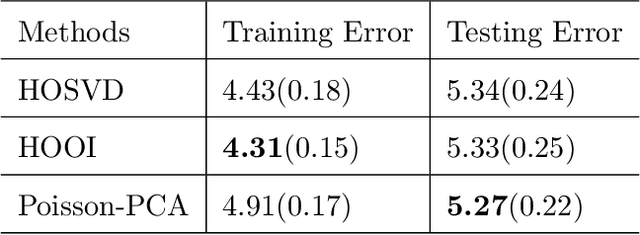
This paper describes a flexible framework for generalized low-rank tensor estimation problems that includes many important instances arising from applications in computational imaging, genomics, and network analysis. The proposed estimator consists of finding a low-rank tensor fit to the data under generalized parametric models. To overcome the difficulty of non-convexity in these problems, we introduce a unified approach of projected gradient descent that adapts to the underlying low-rank structure. Under mild conditions on the loss function, we establish both an upper bound on statistical error and the linear rate of computational convergence through a general deterministic analysis. Then we further consider a suite of generalized tensor estimation problems, including sub-Gaussian tensor denoising, tensor regression, and Poisson and binomial tensor PCA. We prove that the proposed algorithm achieves the minimax optimal rate of convergence in estimation error. Finally, we demonstrate the superiority of the proposed framework via extensive experiments on both simulated and real data.
ISLET: Fast and Optimal Low-rank Tensor Regression via Importance Sketching
Nov 09, 2019

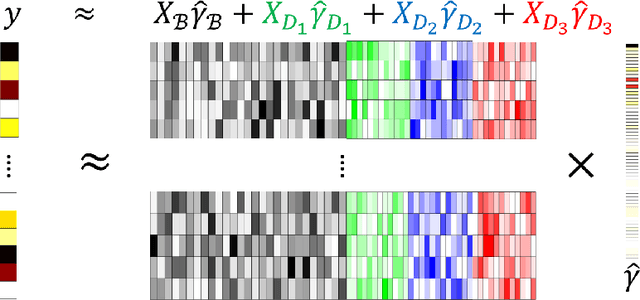
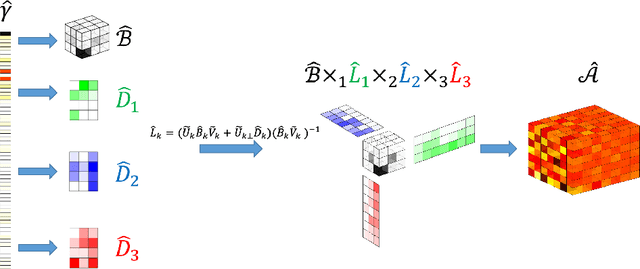
In this paper, we develop a novel procedure for low-rank tensor regression, namely \underline{I}mportance \underline{S}ketching \underline{L}ow-rank \underline{E}stimation for \underline{T}ensors (ISLET). The central idea behind ISLET is \emph{importance sketching}, i.e., carefully designed sketches based on both the responses and low-dimensional structure of the parameter of interest. We show that the proposed method is sharply minimax optimal in terms of the mean-squared error under low-rank Tucker assumptions and under randomized Gaussian ensemble design. In addition, if a tensor is low-rank with group sparsity, our procedure also achieves minimax optimality. Further, we show through numerical studies that ISLET achieves comparable or better mean-squared error performance to existing state-of-the-art methods whilst having substantial storage and run-time advantages including capabilities for parallel and distributed computing. In particular, our procedure performs reliable estimation with tensors of dimension $p = O(10^8)$ and is $1$ or $2$ orders of magnitude faster than baseline methods.
Sparse Group Lasso: Optimal Sample Complexity, Convergence Rate, and Statistical Inference
Sep 21, 2019

In this paper, we study sparse group Lasso for high-dimensional double sparse linear regression, where the parameter of interest is simultaneously element-wise and group-wise sparse. This problem is an important instance of the simultaneously structured model -- an actively studied topic in statistics and machine learning. In the noiseless case, we provide matching upper and lower bounds on sample complexity for the exact recovery of sparse vectors and for stable estimation of approximately sparse vectors, respectively. In the noisy case, we develop upper and matching minimax lower bounds for estimation error. We also consider the debiased sparse group Lasso and investigate its asymptotic property for the purpose of statistical inference. Finally, numerical studies are provided to support the theoretical results.
Learning Markov models via low-rank optimization
Jun 28, 2019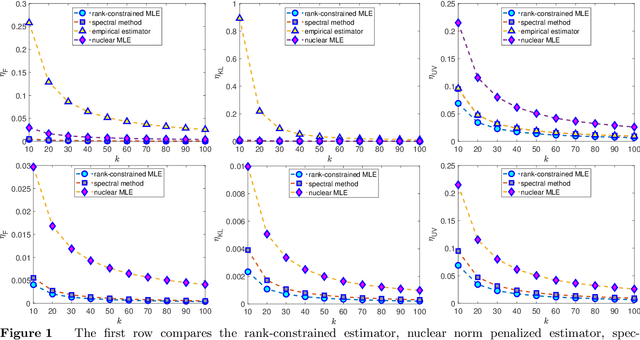
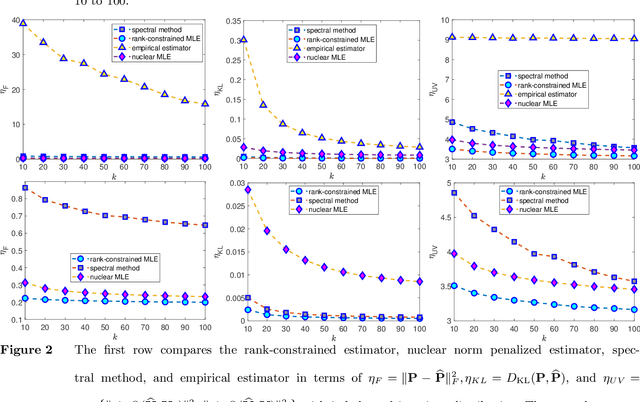
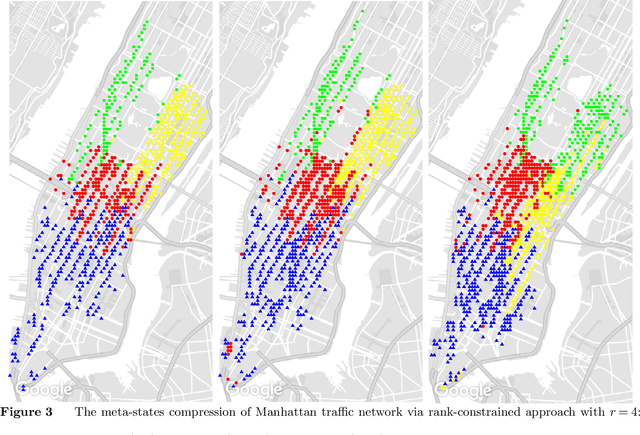
Modeling unknown systems from data is a precursor of system optimization and sequential decision making. In this paper, we focus on learning a Markov model from a single trajectory of states. Suppose that the transition model has a small rank despite of a large state space, meaning that the system admits a low-dimensional latent structure. We show that one can estimate the full transition model accurately using a trajectory of length that is proportional to the total number of states. We propose two maximum likelihood estimation methods: a convex approach with nuclear-norm regularization and a nonconvex approach with rank constraint. We show that both estimators enjoy optimal statistical rates in terms of the Kullback-Leiber divergence and the $\ell_2$ error. For computing the nonconvex estimator, we develop a novel DC (difference of convex function) programming algorithm that starts with the convex M-estimator and then successively refines the solution till convergence. Empirical experiments demonstrate consistent superiority of the nonconvex estimator over the convex one.
A Non-asymptotic, Sharp, and User-friendly Reverse Chernoff-Cramèr Bound
Oct 21, 2018The Chernoff-Cram\`er bound is a widely used technique to analyze the upper tail bound of random variable based on its moment generating function. By elementary proofs, we develop a user-friendly reverse Chernoff-Cram\`er bound that yields non-asymptotic lower tail bounds for generic random variables. The new reverse Chernoff-Cram\`er bound is used to derive a series of results, including the sharp lower tail bounds for the sum of independent sub-Gaussian and sub-exponential random variables, which matches the classic Hoefflding-type and Bernstein-type concentration inequalities, respectively. We also provide non-asymptotic matching upper and lower tail bounds for a suite of distributions, including gamma, beta, (regular, weighted, and noncentral) chi-squared, binomial, Poisson, Irwin-Hall, etc. We apply the result to develop matching upper and lower bounds for extreme value expectation of the sum of independent sub-Gaussian and sub-exponential random variables. A statistical application of sparse signal identification is finally studied.
Heteroskedastic PCA: Algorithm, Optimality, and Applications
Oct 19, 2018


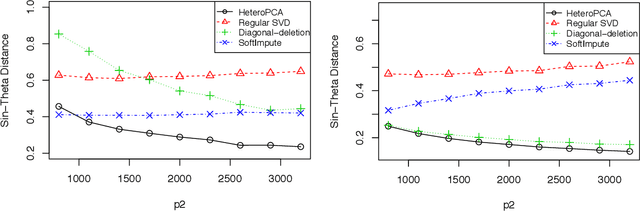
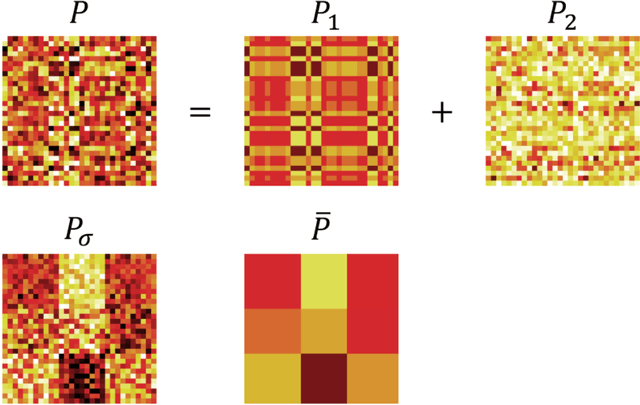
Principal component analysis (PCA) and singular value decomposition (SVD) are widely used in statistics, machine learning, and applied mathematics. It has been well studied in the case of homoskedastic noise, where the noise levels of the contamination are homogeneous. In this paper, we consider PCA and SVD in the presence of heteroskedastic noise, which arises naturally in a range of applications. We introduce a general framework for heteroskedastic PCA and propose an algorithm called HeteroPCA, which involves iteratively imputing the diagonal entries to remove the bias due to heteroskedasticity. This procedure is computationally efficient and provably optimal under the generalized spiked covariance model. A key technical step is a deterministic robust perturbation analysis on the singular subspace, which can be of independent interest. The effectiveness of the proposed algorithm is demonstrated in a suite of applications, including heteroskedastic low-rank matrix denoising, Poisson PCA, and SVD based on heteroskedastic and incomplete data.
Optimal Sparse Singular Value Decomposition for High-dimensional High-order Data
Sep 06, 2018



In this article, we consider the sparse tensor singular value decomposition, which aims for dimension reduction on high-dimensional high-order data with certain sparsity structure. A method named Sparse Tensor Alternating Thresholding for Singular Value Decomposition (STAT-SVD) is proposed. The proposed procedure features a novel double projection \& thresholding scheme, which provides a sharp criterion for thresholding in each iteration. Compared with regular tensor SVD model, STAT-SVD permits more robust estimation under weaker assumptions. Both the upper and lower bounds for estimation accuracy are developed. The proposed procedure is shown to be minimax rate-optimal in a general class of situations. Simulation studies show that STAT-SVD performs well under a variety of configurations. We also illustrate the merits of the proposed procedure on a longitudinal tensor dataset on European country mortality rates.
Spectral State Compression of Markov Processes
Aug 28, 2018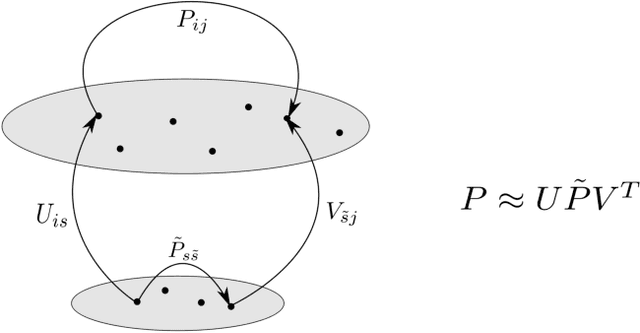

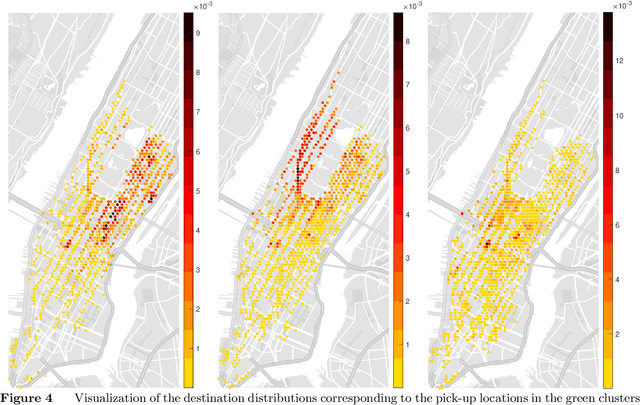
Model reduction of the Markov process is a basic problem in modeling state-transition systems. Motivated by the state aggregation approach rooted in control theory, we study the statistical state compression of a finite-state Markov chain from empirical trajectories. Through the lens of spectral decomposition, we study the rank and features of Markov processes, as well as properties like representability, aggregatability, and lumpability. We develop a class of spectral state compression methods for three tasks: (1) estimate the transition matrix of a low-rank Markov model, (2) estimate the leading subspace spanned by Markov features, and (3) recover latent structures of the state space like state aggregation and lumpable partition. The proposed methods provide an unsupervised learning framework for identifying Markov features and clustering states. We provide upper bounds for the estimation errors and nearly matching minimax lower bounds. Numerical studies are performed on synthetic data and a dataset of New York City taxi trips.