 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRF-Net: Learning Local Reference Frames for 3D Local Shape Description and Matching
Jan 22, 2020
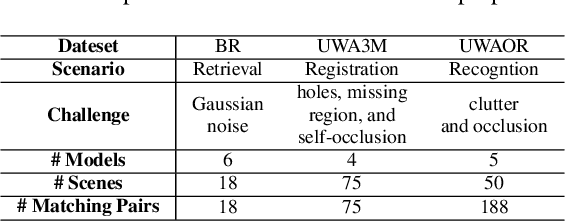
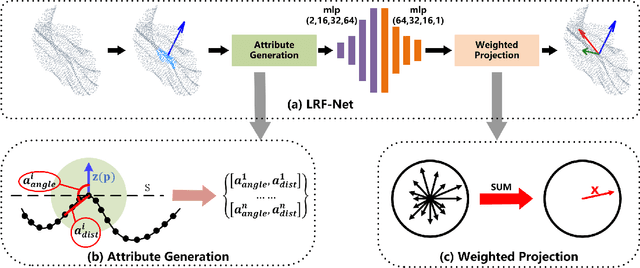
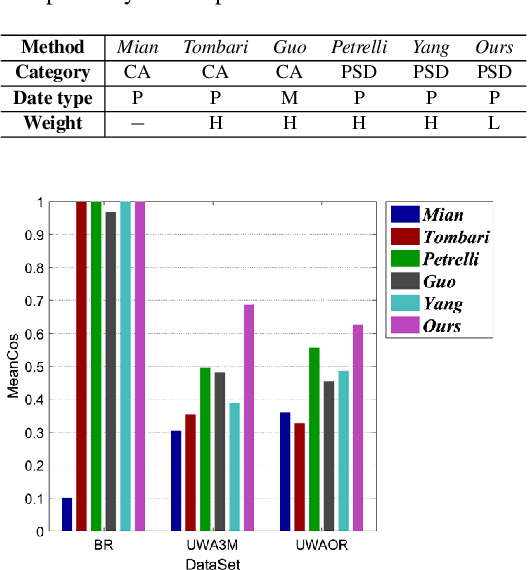
The local reference frame (LRF) acts as a critical role in 3D local shape description and matching. However, most of existing LRFs are hand-crafted and suffer from limited repeatability and robustness. This paper presents the first attempt to learn an LRF via a Siamese network that needs weak supervision only. In particular, we argue that each neighboring point in the local surface gives a unique contribution to LRF construction and measure such contributions via learned weights. Extensive analysis and comparative experiments on three public datasets addressing different application scenarios have demonstrated that LRF-Net is more repeatable and robust than several state-of-the-art LRF methods (LRF-Net is only trained on one dataset). In addition, LRF-Net can significantly boost the local shape description and 6-DoF pose estimation performance when matching 3D point clouds.
Rotation Invariant Point Cloud Classification: Where Local Geometry Meets Global Topology
Nov 01, 2019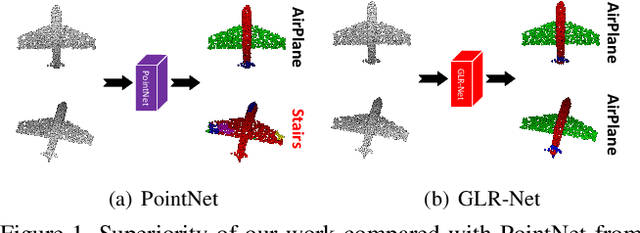
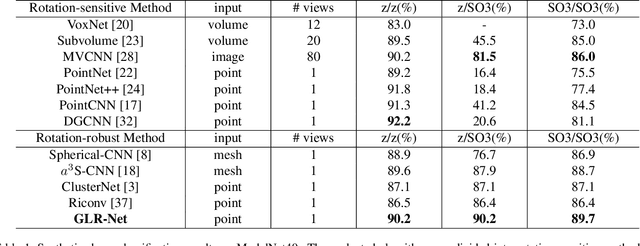
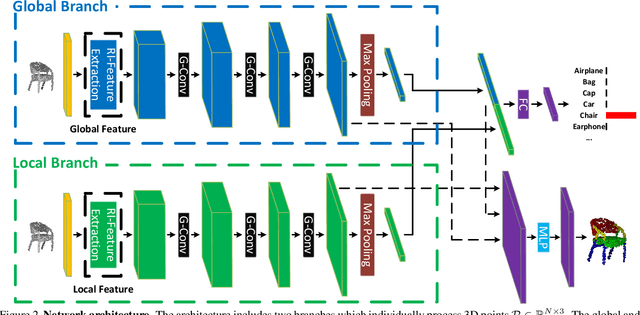
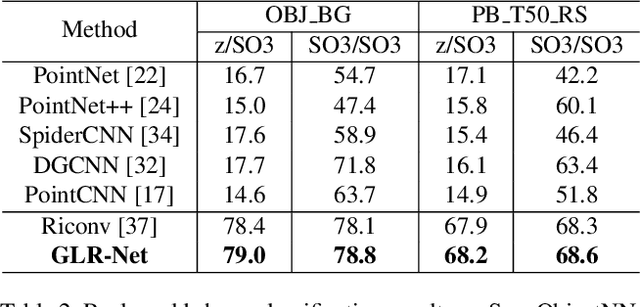
Point cloud analysis is a basic task in 3D computer vision, which attracts increasing research attention. Most previous works develop experiments on synthetic datasets where the data is well-aligned. However, the data is prone to being unaligned in the real world, which contains SO3 rotations. In this context, most existing works are ineffective due to the sensitivity of coordinate changes. For this reason, we address the issue of rotation by presenting a combination of global and local representations which are invariant to rotation. Moreover, we integrate the combination into a two-branch network where the highly dimensional features are hierarchically extracted. Compared with previous rotation-invariant works, the proposed representations effectively consider both global and local information. Extensive experiments have demonstrated that our method achieves state-of-the-art performance on the rotation-augmented version of ModelNet40, ShapeNet, and ScanObjectNN (real-world dataset).
Learning to Fuse Local Geometric Features for 3D Rigid Data Matching
Apr 27, 2019
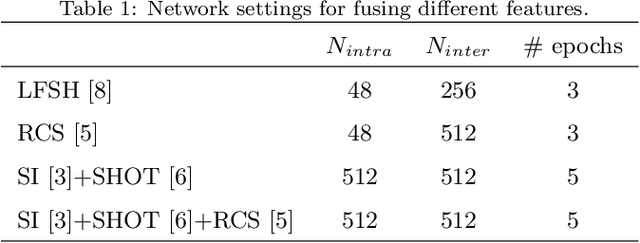
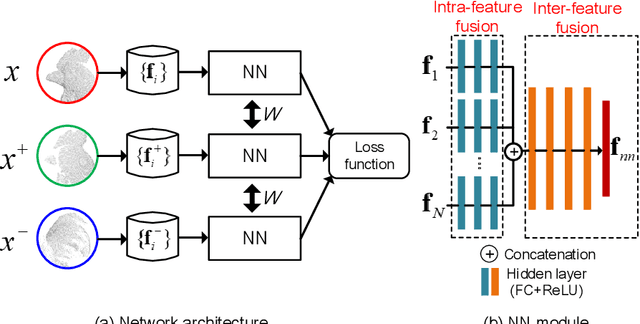
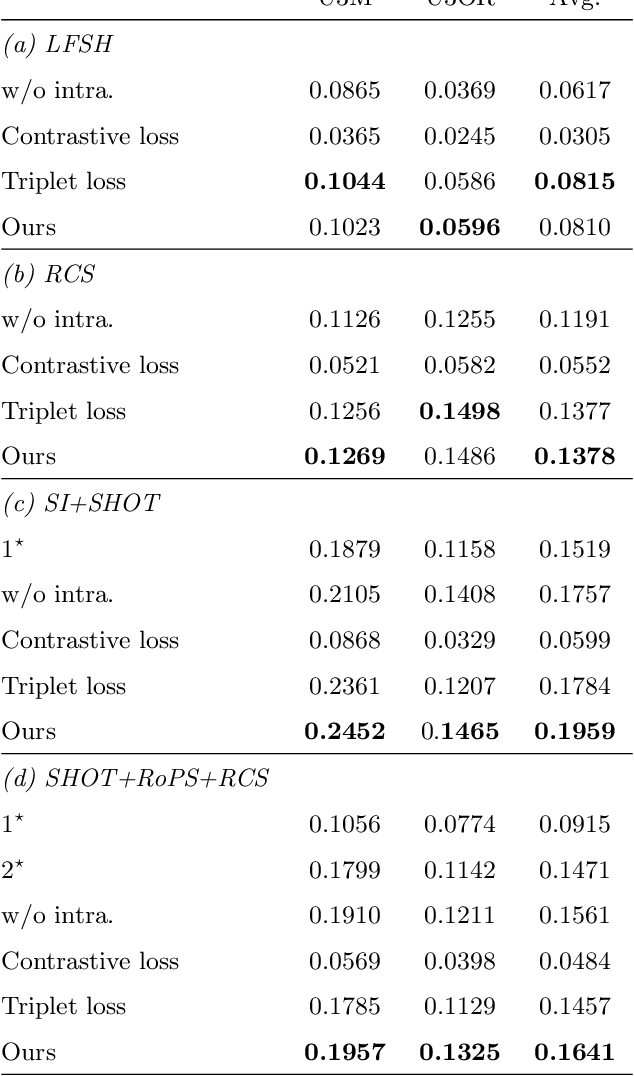
This paper presents a simple yet very effective data-driven approach to fuse both low-level and high-level local geometric features for 3D rigid data matching. It is a common practice to generate distinctive geometric descriptors by fusing low-level features from various viewpoints or subspaces, or enhance geometric feature matching by leveraging multiple high-level features. In prior works, they are typically performed via linear operations such as concatenation and min pooling. We show that more compact and distinctive representations can be achieved by optimizing a neural network (NN) model under the triplet framework that non-linearly fuses local geometric features in Euclidean spaces. The NN model is trained by an improved triplet loss function that fully leverages all pairwise relationships within the triplet. Moreover, the fused descriptor by our approach is also competitive to deep learned descriptors from raw data while being more lightweight and rotational invariant. Experimental results on four standard datasets with various data modalities and application contexts confirm the advantages of our approach in terms of both feature matching and geometric registration.