 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantisation for Robust Segmentation
Jul 05, 2022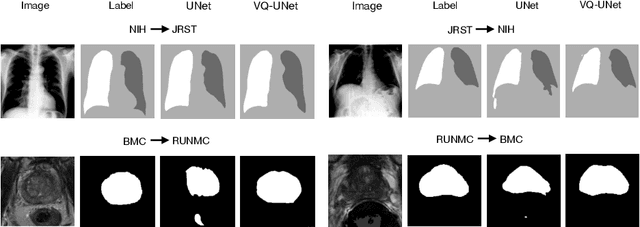
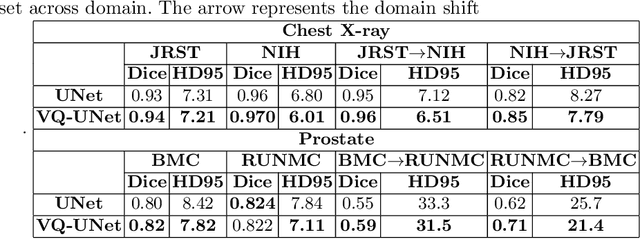


The reliability of segmentation models in the medical domain depends on the model's robustness to perturbations in the input space. Robustness is a particular challenge in medical imaging exhibiting various sources of image noise, corruptions, and domain shifts. Obtaining robustness is often attempted via simulating heterogeneous environments, either heuristically in the form of data augmentation or by learning to generate specific perturbations in an adversarial manner. We propose and justify that learning a discrete representation in a low dimensional embedding space improves robustness of a segmentation model. This is achieved with a dictionary learning method called vector quantisation. We use a set of experiments designed to analyse robustness in both the latent and output space under domain shift and noise perturbations in the input space. We adapt the popular UNet architecture, inserting a quantisation block in the bottleneck. We demonstrate improved segmentation accuracy and better robustness on three segmentation tasks. Code is available at \url{https://github.com/AinkaranSanthi/Vector-Quantisation-for-Robust-Segmentation}
Hierarchical Symbolic Reasoning in Hyperbolic Space for Deep Discriminative Models
Jul 05, 2022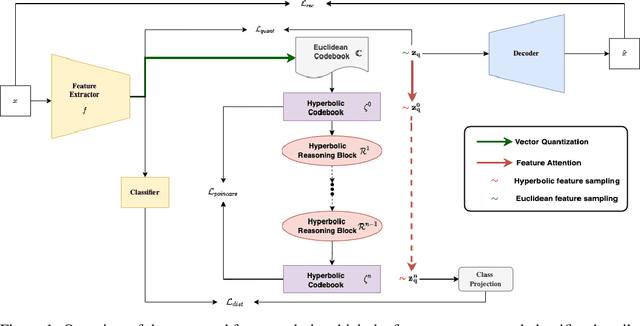
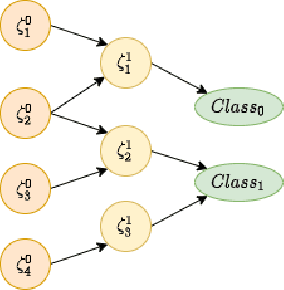
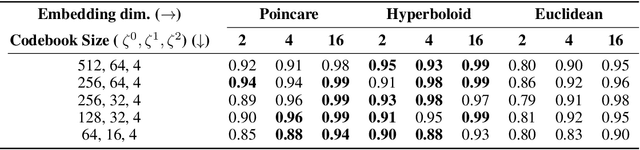
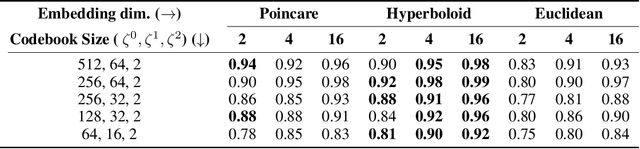
Explanations for \emph{black-box} models help us understand model decisions as well as provide information on model biases and inconsistencies. Most of the current explainability techniques provide a single level of explanation, often in terms of feature importance scores or feature attention maps in input space. Our focus is on explaining deep discriminative models at \emph{multiple levels of abstraction}, from fine-grained to fully abstract explanations. We achieve this by using the natural properties of \emph{hyperbolic geometry} to more efficiently model a hierarchy of symbolic features and generate \emph{hierarchical symbolic rules} as part of our explanations. Specifically, for any given deep discriminative model, we distill the underpinning knowledge by discretisation of the continuous latent space using vector quantisation to form symbols, followed by a \emph{hyperbolic reasoning block} to induce an \emph{abstraction tree}. We traverse the tree to extract explanations in terms of symbolic rules and its corresponding visual semantics. We demonstrate the effectiveness of our method on the MNIST and AFHQ high-resolution animal faces dataset. Our framework is available at \url{https://github.com/koriavinash1/SymbolicInterpretability}.
Multiple Instance Learning with Auxiliary Task Weighting for Multiple Myeloma Classification
Jul 16, 2021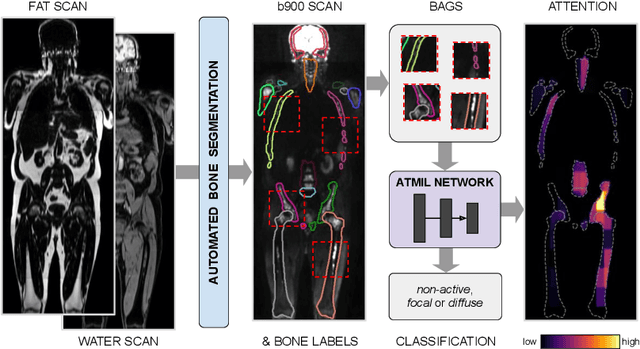
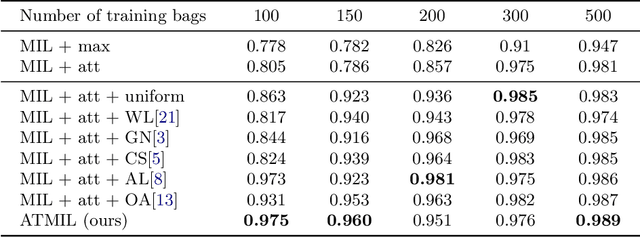
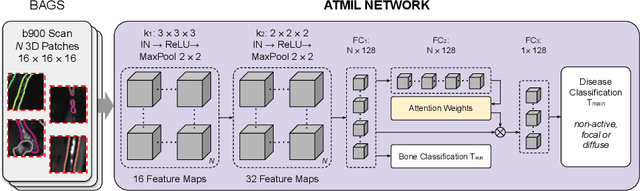
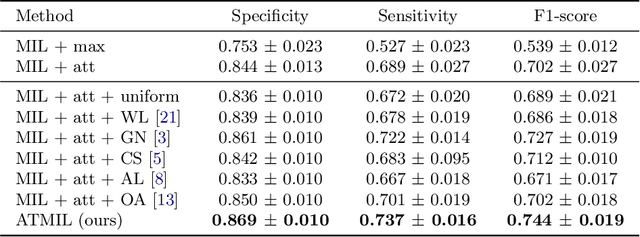
Whole body magnetic resonance imaging (WB-MRI) is the recommended modality for diagnosis of multiple myeloma (MM). WB-MRI is used to detect sites of disease across the entire skeletal system, but it requires significant expertise and is time-consuming to report due to the great number of images. To aid radiological reading, we propose an auxiliary task-based multiple instance learning approach (ATMIL) for MM classification with the ability to localize sites of disease. This approach is appealing as it only requires patient-level annotations where an attention mechanism is used to identify local regions with active disease. We borrow ideas from multi-task learning and define an auxiliary task with adaptive reweighting to support and improve learning efficiency in the presence of data scarcity. We validate our approach on both synthetic and real multi-center clinical data. We show that the MIL attention module provides a mechanism to localize bone regions while the adaptive reweighting of the auxiliary task considerably improves the performance.
Fully-automated deep learning slice-based muscle estimation from CT images for sarcopenia assessment
Jun 10, 2020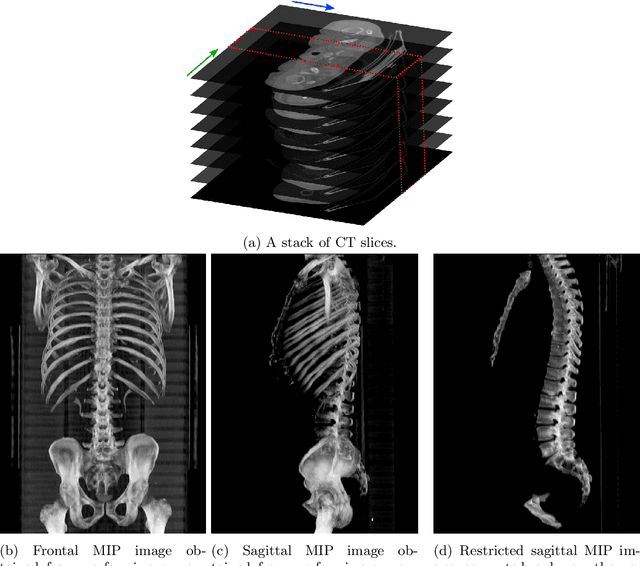
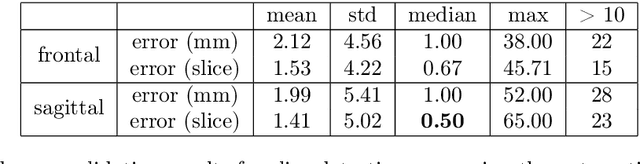
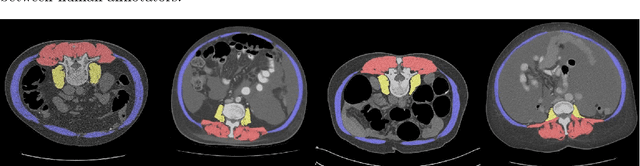

Objective: To demonstrate the effectiveness of using a deep learning-based approach for a fully automated slice-based measurement of muscle mass for assessing sarcopenia on CT scans of the abdomen without any case exclusion criteria. Materials and Methods: This retrospective study was conducted using a collection of public and privately available CT images (n = 1070). The method consisted of two stages: slice detection from a CT volume and single-slice CT segmentation. Both stages used Fully Convolutional Neural Networks (FCNN) and were based on a UNet-like architecture. Input data consisted of CT volumes with a variety of fields of view. The output consisted of a segmented muscle mass on a CT slice at the level of L3 vertebra. The muscle mass is segmented into erector spinae, psoas, and rectus abdominus muscle groups. The output was tested against manual ground-truth segmentation by an expert annotator. Results: 3-fold cross validation was used to evaluate the proposed method. The slice detection cross validation error was 1.41+-5.02 (in slices). The segmentation cross validation Dice overlaps were 0.97+-0.02, 0.95+-0.04, 0.94+-0.04 for erector spinae, psoas, and rectus abdominus, respectively, and 0.96+-0.02 for the combined muscle mass. Conclusion: A deep learning approach to detect CT slices and segment muscle mass to perform slice-based analysis of sarcopenia is an effective and promising approach. The use of FCNN to accurately and efficiently detect a slice in CT volumes with a variety of fields of view, occlusions, and slice thicknesses was demonstrated.
Automatic L3 slice detection in 3D CT images using fully-convolutional networks
Nov 22, 2018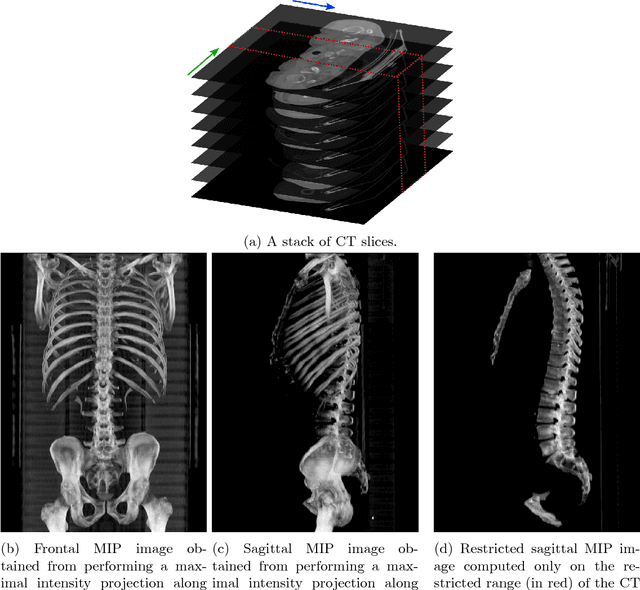


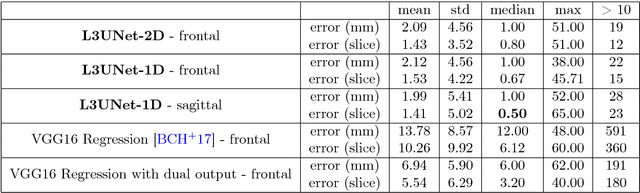
The analysis of single CT slices extracted at the third lumbar vertebra (L3) has garnered significant clinical interest in the past few years, in particular in regards to quantifying sarcopenia (muscle loss). In this paper, we propose an efficient method to automatically detect the L3 slice in 3D CT images. Our method works with images with a variety of fields of view, occlusions, and slice thicknesses. 3D CT images are first converted into 2D via Maximal Intensity Projection (MIP), reducing the dimensionality of the problem. The MIP images are then used as input to a 2D fully-convolutional network to predict the L3 slice locations in the form of 2D confidence maps. In addition we propose a variant architecture with less parameters allowing 1D confidence map prediction and slightly faster prediction time without loss of accuracy. Quantitative evaluation of our method on a dataset of 1006 3D CT images yields a median error of 1mm, similar to the inter-rater median error of 1mm obtained from two annotators, demonstrating the effectiveness of our method in efficiently and accurately detecting the L3 slice.