 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Example Games
Jul 01, 2020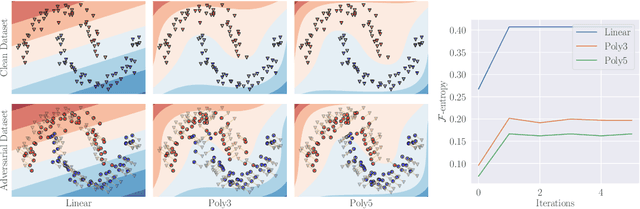

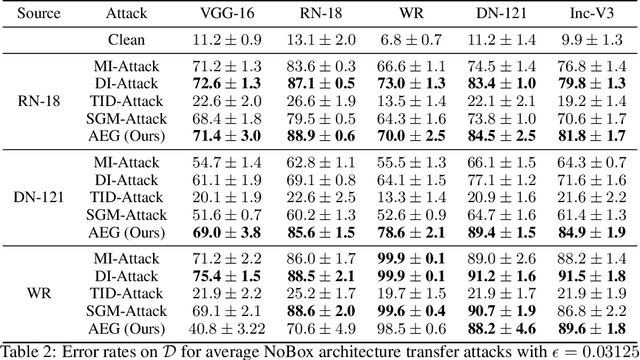

The existence of adversarial examples capable of fooling trained neural network classifiers calls for a much better understanding of possible attacks, in order to guide the development of safeguards against them. It includes attack methods in the highly challenging non-interactive blackbox setting, where adversarial attacks are generated without any access, including queries, to the target model. Prior works in this setting have relied mainly on algorithmic innovations derived from empirical observations (e.g., that momentum helps), and the field currently lacks a firm theoretical basis for understanding transferability in adversarial attacks. In this work, we address this gap and lay the theoretical foundations for crafting transferable adversarial examples to entire function classes. We introduce Adversarial Examples Games (AEG), a novel framework that models adversarial examples as two-player min-max games between an attack generator and a representative classifier. We prove that the saddle point of an AEG game corresponds to a generating distribution of adversarial examples against entire function classes. Training the generator only requires the ability to optimize a representative classifier from a given hypothesis class, enabling BlackBox transfer to unseen classifiers from the same class. We demonstrate the efficacy of our approach on the MNIST and CIFAR-10 datasets against both undefended and robustified models, achieving competitive performance with state-of-the-art BlackBox transfer approaches.
Generalizable Adversarial Attacks Using Generative Models
Jun 12, 2019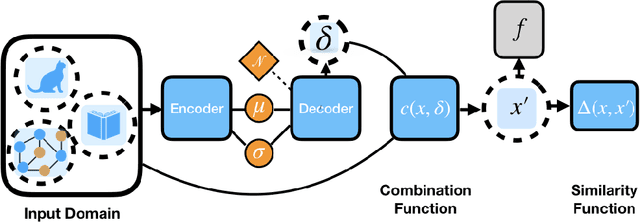



Adversarial attacks on deep neural networks traditionally rely on a constrained optimization paradigm, where an optimization procedure is used to obtain a single adversarial perturbation for a given input example. Here, we instead view adversarial attacks as a generative modelling problem, with the goal of producing entire distributions of adversarial examples given an unperturbed input. We show that this generative perspective can be used to design a unified encoder-decoder framework, which is domain-agnostic in that the same framework can be employed to attack different domains with minimal modification. Across three diverse domains---images, text, and graphs---our approach generates whitebox attacks with success rates that are competitive with or superior to existing approaches, with a new state-of-the-art achieved in the graph domain. Finally, we demonstrate that our generative framework can efficiently generate a diverse set of attacks for a single given input, and is even capable of attacking unseen test instances in a zero-shot manner, exhibiting attack generalization.
Clustering-Oriented Representation Learning with Attractive-Repulsive Loss
Dec 18, 2018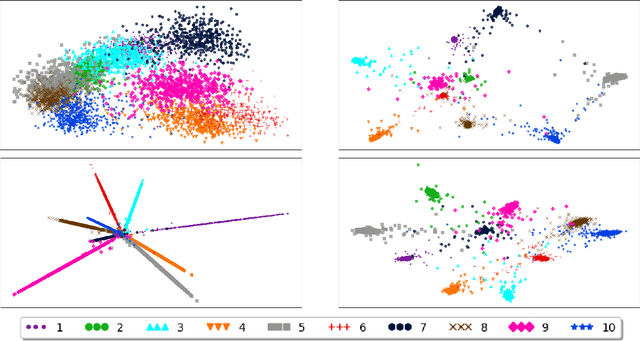
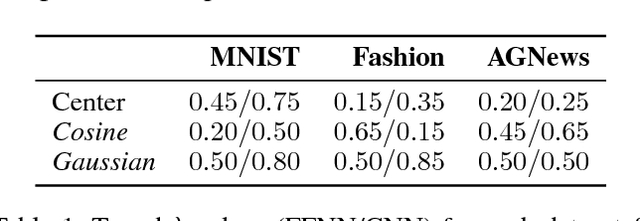
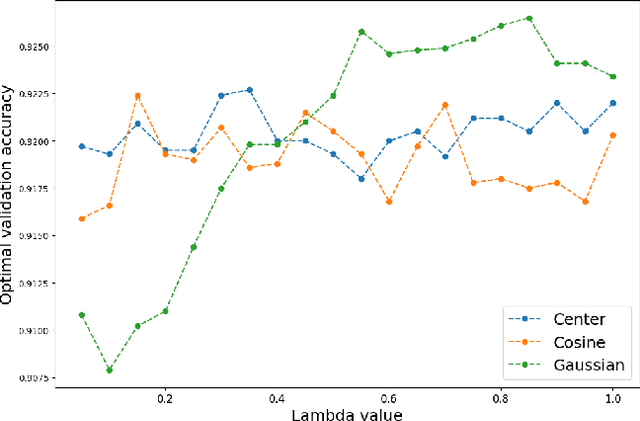

The standard loss function used to train neural network classifiers, categorical cross-entropy (CCE), seeks to maximize accuracy on the training data; building useful representations is not a necessary byproduct of this objective. In this work, we propose clustering-oriented representation learning (COREL) as an alternative to CCE in the context of a generalized attractive-repulsive loss framework. COREL has the consequence of building latent representations that collectively exhibit the quality of natural clustering within the latent space of the final hidden layer, according to a predefined similarity function. Despite being simple to implement, COREL variants outperform or perform equivalently to CCE in a variety of scenarios, including image and news article classification using both feed-forward and convolutional neural networks. Analysis of the latent spaces created with different similarity functions facilitates insights on the different use cases COREL variants can satisfy, where the Cosine-COREL variant makes a consistently clusterable latent space, while Gaussian-COREL consistently obtains better classification accuracy than CCE.
Let's do it "again": A First Computational Approach to Detecting Adverbial Presupposition Triggers
Jun 11, 2018
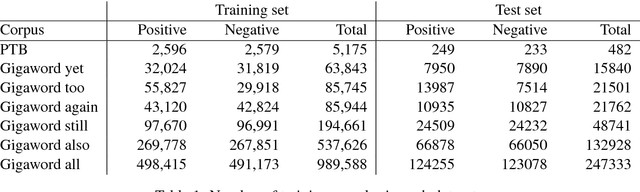
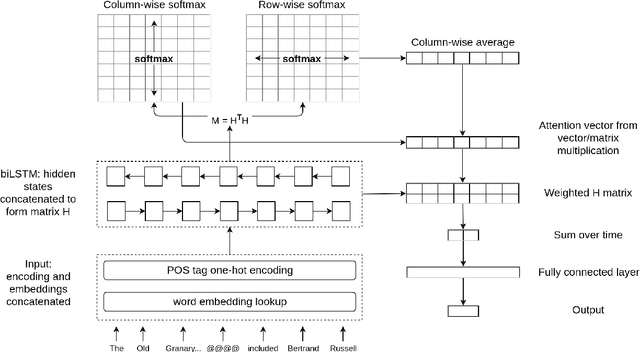
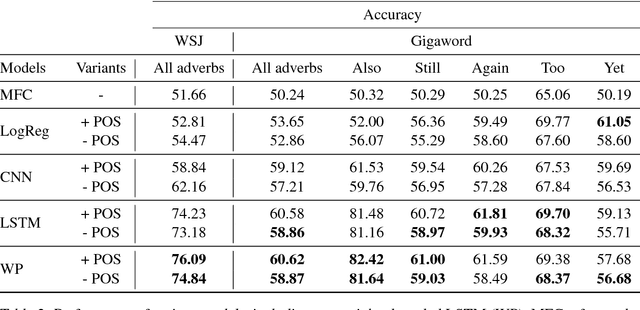
We introduce the task of predicting adverbial presupposition triggers such as also and again. Solving such a task requires detecting recurring or similar events in the discourse context, and has applications in natural language generation tasks such as summarization and dialogue systems. We create two new datasets for the task, derived from the Penn Treebank and the Annotated English Gigaword corpora, as well as a novel attention mechanism tailored to this task. Our attention mechanism augments a baseline recurrent neural network without the need for additional trainable parameters, minimizing the added computational cost of our mechanism. We demonstrate that our model statistically outperforms a number of baselines, including an LSTM-based language model.
The CLaC Discourse Parser at CoNLL-2016
Aug 19, 2017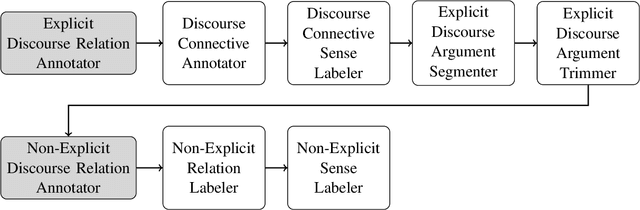
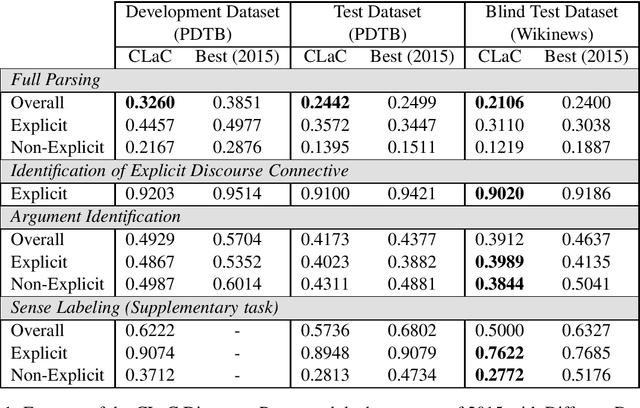
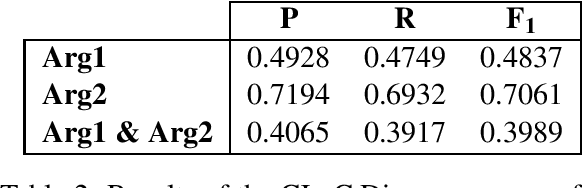
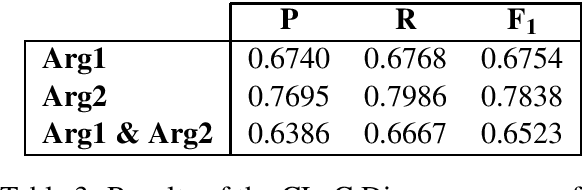
This paper describes our submission "CLaC" to the CoNLL-2016 shared task on shallow discourse parsing. We used two complementary approaches for the task. A standard machine learning approach for the parsing of explicit relations, and a deep learning approach for non-explicit relations. Overall, our parser achieves an F1-score of 0.2106 on the identification of discourse relations (0.3110 for explicit relations and 0.1219 for non-explicit relations) on the blind CoNLL-2016 test set.
N-gram and Neural Language Models for Discriminating Similar Languages
Aug 11, 2017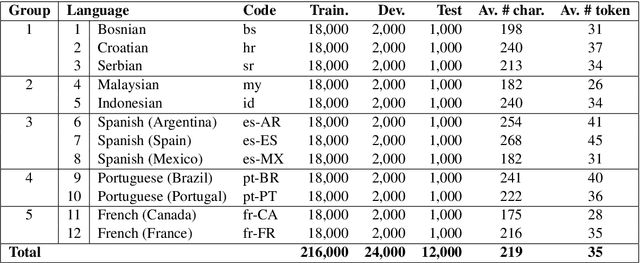
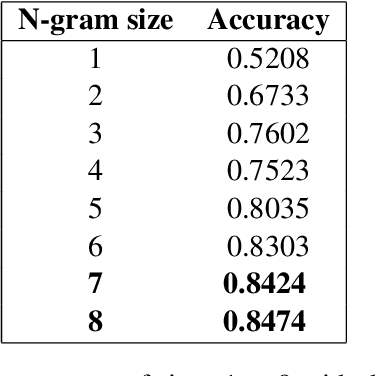
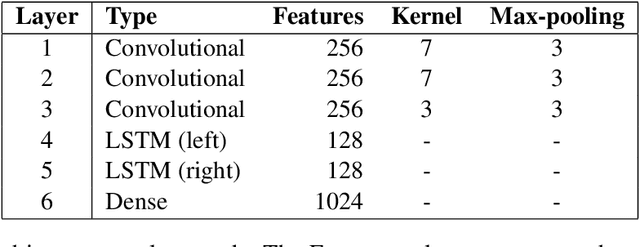

This paper describes our submission (named clac) to the 2016 Discriminating Similar Languages (DSL) shared task. We participated in the closed Sub-task 1 (Set A) with two separate machine learning techniques. The first approach is a character based Convolution Neural Network with a bidirectional long short term memory (BiLSTM) layer (CLSTM), which achieved an accuracy of 78.45% with minimal tuning. The second approach is a character-based n-gram model. This last approach achieved an accuracy of 88.45% which is close to the accuracy of 89.38% achieved by the best submission, and allowed us to rank #7 overall.
* 8 pages