Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-gram and Neural Language Models for Discriminating Similar Languages
Paper and Code
Aug 11, 2017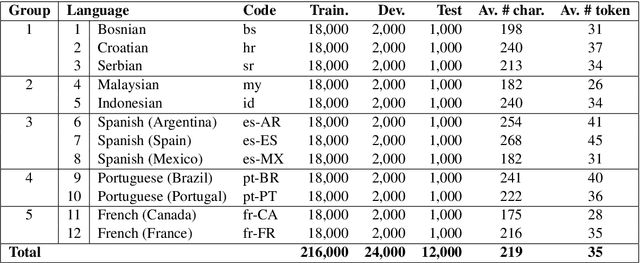
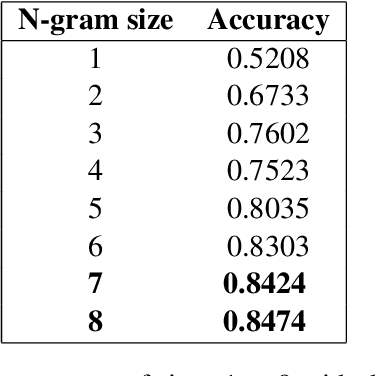
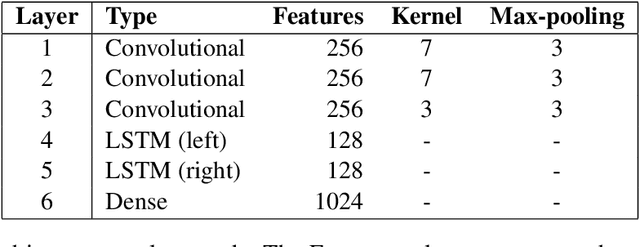

This paper describes our submission (named clac) to the 2016 Discriminating Similar Languages (DSL) shared task. We participated in the closed Sub-task 1 (Set A) with two separate machine learning techniques. The first approach is a character based Convolution Neural Network with a bidirectional long short term memory (BiLSTM) layer (CLSTM), which achieved an accuracy of 78.45% with minimal tuning. The second approach is a character-based n-gram model. This last approach achieved an accuracy of 88.45% which is close to the accuracy of 89.38% achieved by the best submission, and allowed us to rank #7 overall.
* Proceedings of the Third Workshop on NLP for Similar Languages,
Varieties and Dialects (VarDial3). A workshop of the 26th International
Conference on Computational Linguistics (COLING 2016, Osaka, Japan), pp
243-250 (2016) * 8 pages
View paper on