 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving 100X faster simulations of complex biological phenomena by coupling ML to HPC ensembles
Apr 26, 2021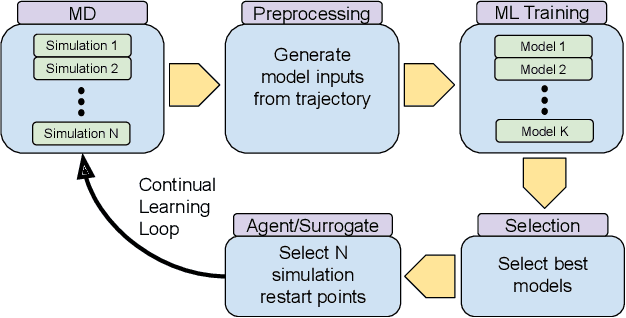
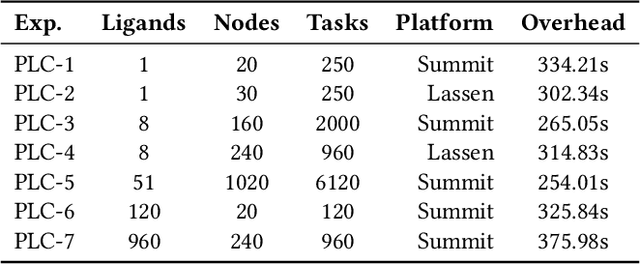
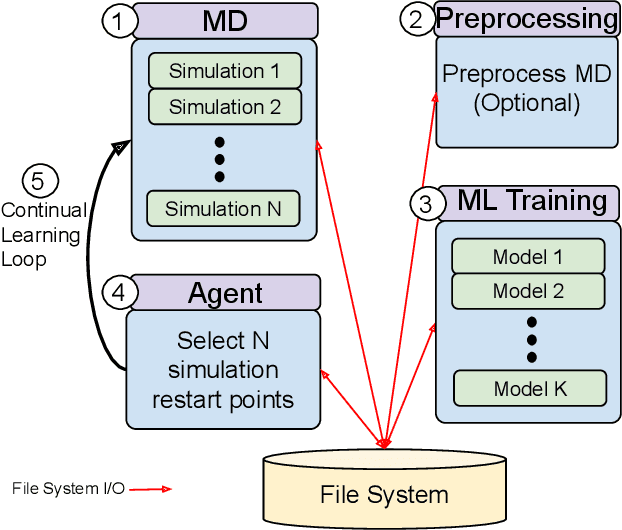
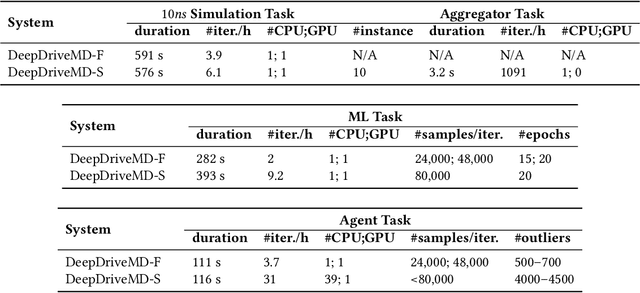
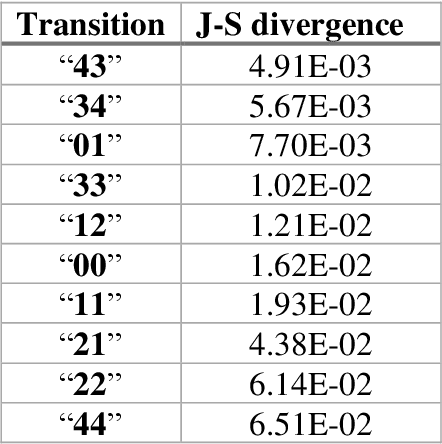
The use of ML methods to dynamically steer ensemble-based simulations promises significant improvements in the performance of scientific applications. We present DeepDriveMD, a tool for a range of prototypical ML-driven HPC simulation scenarios, and use it to quantify improvements in the scientific performance of ML-driven ensemble-based applications. We discuss its design and characterize its performance. Motivated by the potential for further scientific improvements and applicability to more sophisticated physical systems, we extend the design of DeepDriveMD to support stream-based communication between simulations and learning methods. It demonstrates a 100x speedup to fold proteins, and performs 1.6x more simulations per unit time, improving resource utilization compared to the sequential framework. Experiments are performed on leadership-class platforms, at scales of up to O(1000) nodes, and for production workloads. We establish DeepDriveMD as a high-performance framework for ML-driven HPC simulation scenarios, that supports diverse simulation and ML back-ends, and which enables new scientific insights by improving length- and time-scale accessed.
Pandemic Drugs at Pandemic Speed: Accelerating COVID-19 Drug Discovery with Hybrid Machine Learning- and Physics-based Simulations on High Performance Computers
Mar 04, 2021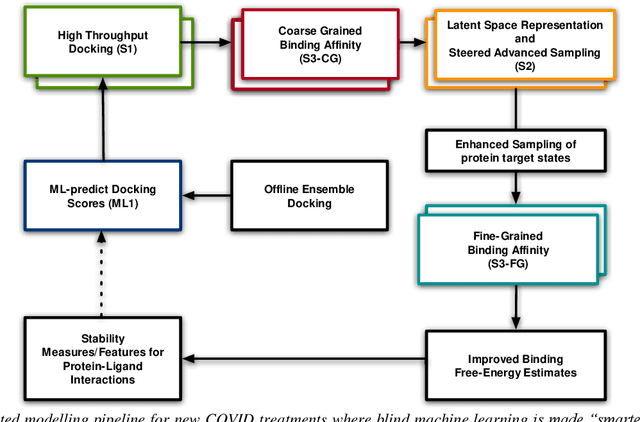

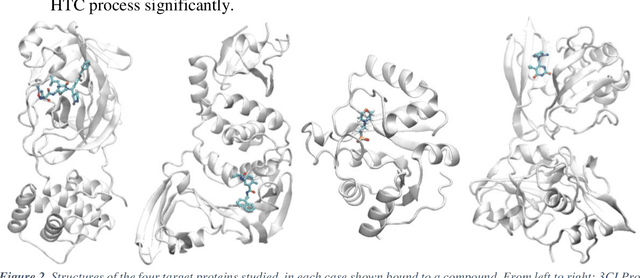
The race to meet the challenges of the global pandemic has served as a reminder that the existing drug discovery process is expensive, inefficient and slow. There is a major bottleneck screening the vast number of potential small molecules to shortlist lead compounds for antiviral drug development. New opportunities to accelerate drug discovery lie at the interface between machine learning methods, in this case developed for linear accelerators, and physics-based methods. The two in silico methods, each have their own advantages and limitations which, interestingly, complement each other. Here, we present an innovative method that combines both approaches to accelerate drug discovery. The scale of the resulting workflow is such that it is dependent on high performance computing. We have demonstrated the applicability of this workflow on four COVID-19 target proteins and our ability to perform the required large-scale calculations to identify lead compounds on a variety of supercomputers.