 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Resolution-Adaptive 8 mm$^\text{2}$ 9.98 Gb/s 39.7 pJ/b 32-Antenna All-Digital Spatial Equalizer for mmWave Massive MU-MIMO in 65nm CMOS
Jul 23, 2021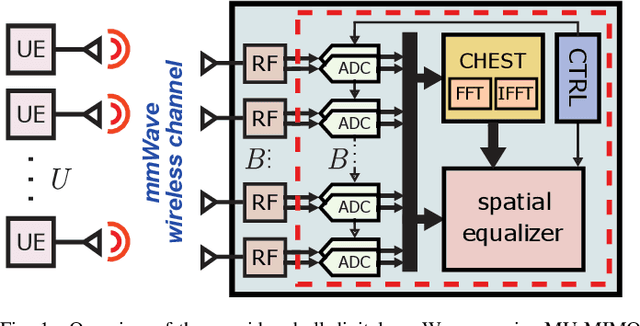

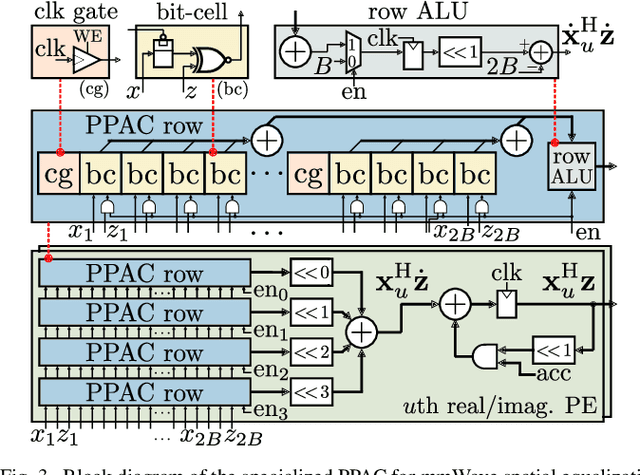
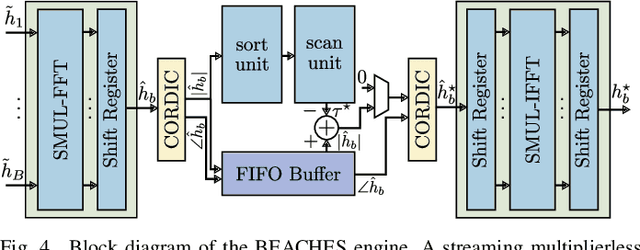
All-digital millimeter-wave (mmWave) massive multi-user multiple-input multiple-output (MU-MIMO) receivers enable extreme data rates but require high power consumption. In order to reduce power consumption, this paper presents the first resolution-adaptive all-digital receiver ASIC that is able to adjust the resolution of the data-converters and baseband-processing engine to the instantaneous communication scenario. The scalable 32-antenna, 65 nm CMOS receiver occupies a total area of 8 mm$^\text{2}$ and integrates analog-to-digital converters (ADCs) with programmable gain and resolution, beamspace channel estimation, and a resolution-adaptive processing-in-memory spatial equalizer. With 6-bit ADC samples and a 4-bit spatial equalizer, our ASIC achieves a throughput of 9.98 Gb/s while being at least 2x more energy-efficient than state-of-the-art designs.
Resolution-Adaptive All-Digital Spatial Equalization for mmWave Massive MU-MIMO
Jul 23, 2021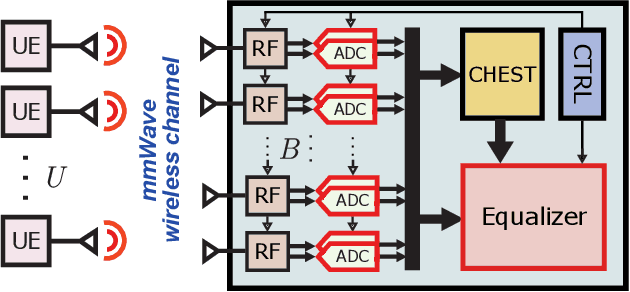
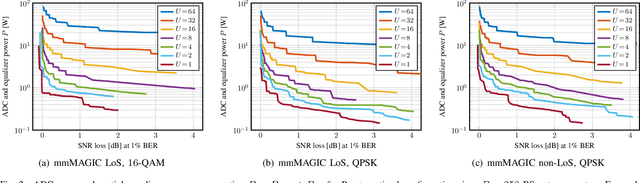
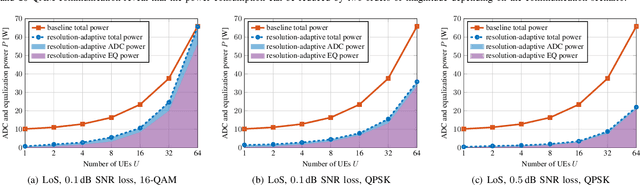
All-digital basestation (BS) architectures for millimeter-wave (mmWave) massive multi-user multiple-input multiple-output (MU-MIMO), which equip each radio-frequency chain with dedicated data converters, have advantages in spectral efficiency, flexibility, and baseband-processing simplicity over hybrid analog-digital solutions. For all-digital architectures to be competitive with hybrid solutions in terms of power consumption, novel signal-processing methods and baseband architectures are necessary. In this paper, we demonstrate that adapting the resolution of the analog-to-digital converters (ADCs) and spatial equalizer of an all-digital system to the communication scenario (e.g., the number of users, modulation scheme, and propagation conditions) enables orders-of-magnitude power savings for realistic mmWave channels. For example, for a 256-BS-antenna 16-user system supporting 1 GHz bandwidth, a traditional baseline architecture designed for a 64-user worst-case scenario would consume 23 W in 28 nm CMOS for the ADC array and the spatial equalizer, whereas a resolution-adaptive architecture is able to reduce the power consumption by 6.7x.
Compressive Light Field Reconstructions using Deep Learning
Feb 05, 2018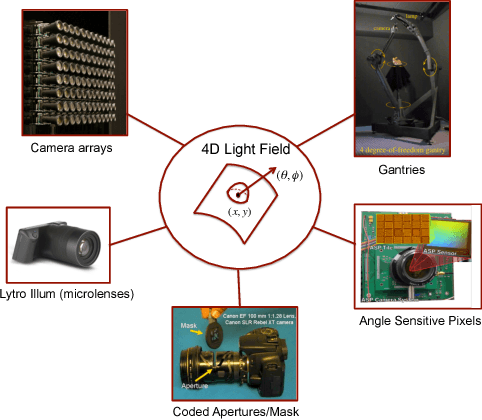


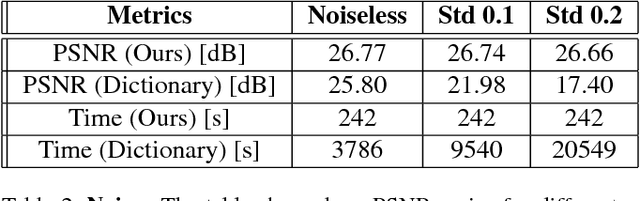
Light field imaging is limited in its computational processing demands of high sampling for both spatial and angular dimensions. Single-shot light field cameras sacrifice spatial resolution to sample angular viewpoints, typically by multiplexing incoming rays onto a 2D sensor array. While this resolution can be recovered using compressive sensing, these iterative solutions are slow in processing a light field. We present a deep learning approach using a new, two branch network architecture, consisting jointly of an autoencoder and a 4D CNN, to recover a high resolution 4D light field from a single coded 2D image. This network decreases reconstruction time significantly while achieving average PSNR values of 26-32 dB on a variety of light fields. In particular, reconstruction time is decreased from 35 minutes to 6.7 minutes as compared to the dictionary method for equivalent visual quality. These reconstructions are performed at small sampling/compression ratios as low as 8%, allowing for cheaper coded light field cameras. We test our network reconstructions on synthetic light fields, simulated coded measurements of real light fields captured from a Lytro Illum camera, and real coded images from a custom CMOS diffractive light field camera. The combination of compressive light field capture with deep learning allows the potential for real-time light field video acquisition systems in the future.
ASP Vision: Optically Computing the First Layer of Convolutional Neural Networks using Angle Sensitive Pixels
Nov 16, 2016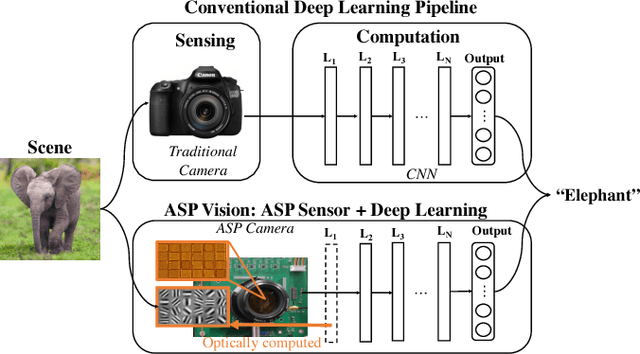
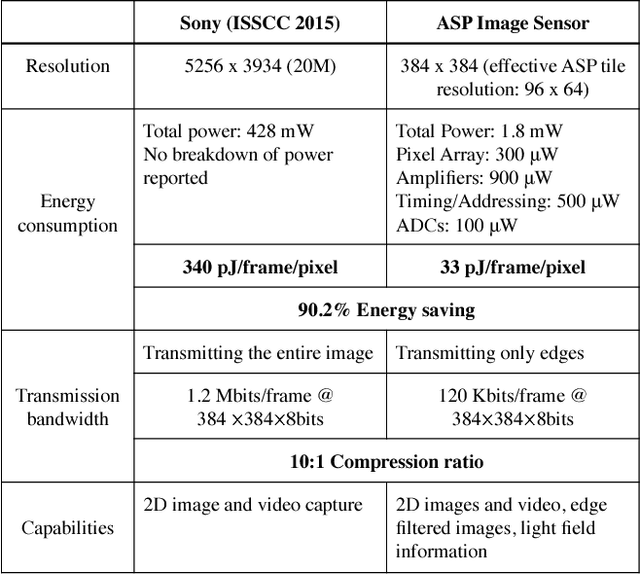

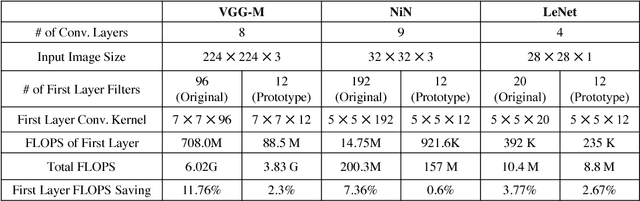
Deep learning using convolutional neural networks (CNNs) is quickly becoming the state-of-the-art for challenging computer vision applications. However, deep learning's power consumption and bandwidth requirements currently limit its application in embedded and mobile systems with tight energy budgets. In this paper, we explore the energy savings of optically computing the first layer of CNNs. To do so, we utilize bio-inspired Angle Sensitive Pixels (ASPs), custom CMOS diffractive image sensors which act similar to Gabor filter banks in the V1 layer of the human visual cortex. ASPs replace both image sensing and the first layer of a conventional CNN by directly performing optical edge filtering, saving sensing energy, data bandwidth, and CNN FLOPS to compute. Our experimental results (both on synthetic data and a hardware prototype) for a variety of vision tasks such as digit recognition, object recognition, and face identification demonstrate using ASPs while achieving similar performance compared to traditional deep learning pipelines.
Depth Fields: Extending Light Field Techniques to Time-of-Flight Imaging
Sep 02, 2015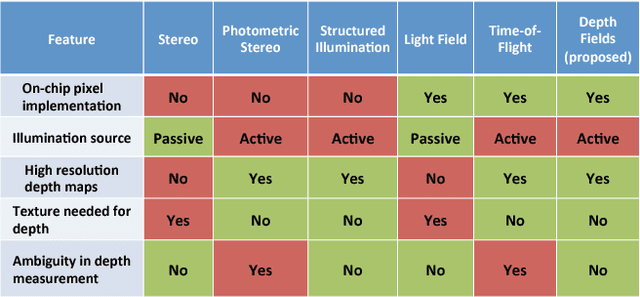

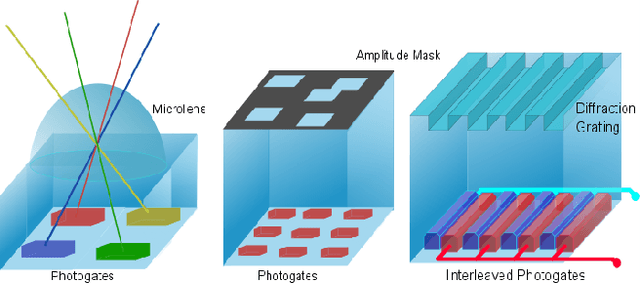
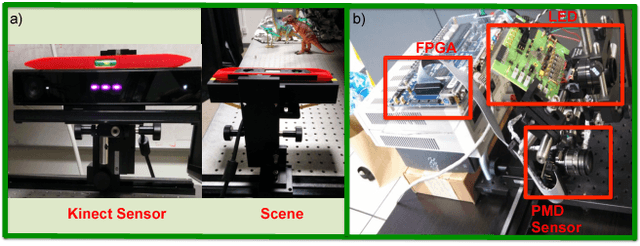
A variety of techniques such as light field, structured illumination, and time-of-flight (TOF) are commonly used for depth acquisition in consumer imaging, robotics and many other applications. Unfortunately, each technique suffers from its individual limitations preventing robust depth sensing. In this paper, we explore the strengths and weaknesses of combining light field and time-of-flight imaging, particularly the feasibility of an on-chip implementation as a single hybrid depth sensor. We refer to this combination as depth field imaging. Depth fields combine light field advantages such as synthetic aperture refocusing with TOF imaging advantages such as high depth resolution and coded signal processing to resolve multipath interference. We show applications including synthesizing virtual apertures for TOF imaging, improved depth mapping through partial and scattering occluders, and single frequency TOF phase unwrapping. Utilizing space, angle, and temporal coding, depth fields can improve depth sensing in the wild and generate new insights into the dimensions of light's plenoptic function.