 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Transfer Limits of Vision Foundation Models
Jan 22, 2026Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.
T2-Only Prostate Cancer Prediction by Meta-Learning from Bi-Parametric MR Imaging
Nov 11, 2024


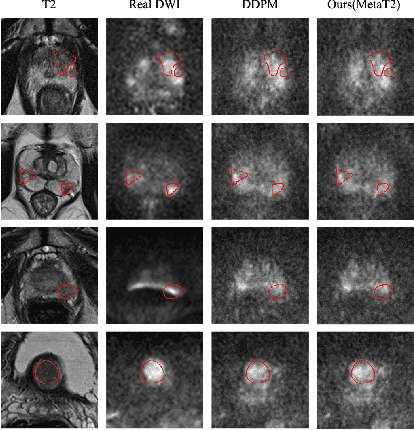
Current imaging-based prostate cancer diagnosis requires both MR T2-weighted (T2w) and diffusion-weighted imaging (DWI) sequences, with additional sequences for potentially greater accuracy improvement. However, measuring diffusion patterns in DWI sequences can be time-consuming, prone to artifacts and sensitive to imaging parameters. While machine learning (ML) models have demonstrated radiologist-level accuracy in detecting prostate cancer from these two sequences, this study investigates the potential of ML-enabled methods using only the T2w sequence as input during inference time. We first discuss the technical feasibility of such a T2-only approach, and then propose a novel ML formulation, where DWI sequences - readily available for training purposes - are only used to train a meta-learning model, which subsequently only uses T2w sequences at inference. Using multiple datasets from more than 3,000 prostate cancer patients, we report superior or comparable performance in localising radiologist-identified prostate cancer using our proposed T2-only models, compared with alternative models using T2-only or both sequences as input. Real patient cases are presented and discussed to demonstrate, for the first time, the exclusively true-positive cases from models with different input sequences.