 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight Experience Replay with Kronecker Product Approximate Curvature
Oct 09, 2020
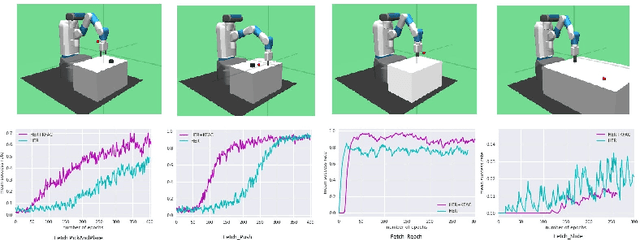
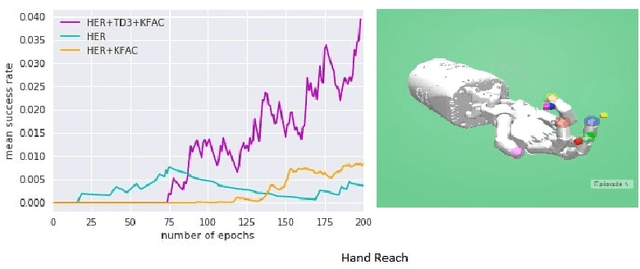
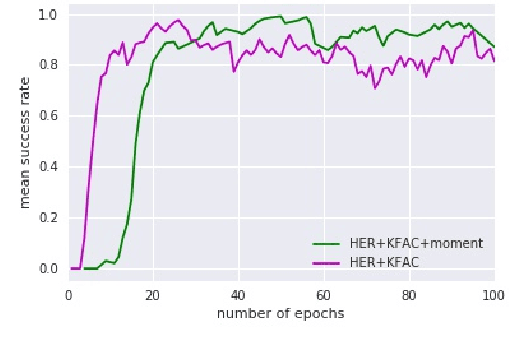
Hindsight Experience Replay (HER) is one of the efficient algorithm to solve Reinforcement Learning tasks related to sparse rewarded environments.But due to its reduced sample efficiency and slower convergence HER fails to perform effectively. Natural gradients solves these challenges by converging the model parameters better. It avoids taking bad actions that collapse the training performance. However updating parameters in neural networks requires expensive computation and thus increase in training time. Our proposed method solves the above mentioned challenges with better sample efficiency and faster convergence with increased success rate. A common failure mode for DDPG is that the learned Q-function begins to dramatically overestimate Q-values, which then leads to the policy breaking, because it exploits the errors in the Q-function. We solve this issue by including Twin Delayed Deep Deterministic Policy Gradients(TD3) in HER. TD3 learns two Q-functions instead of one and it adds noise tothe target action, to make it harder for the policy to exploit Q-function errors. The experiments are done with the help of OpenAis Mujoco environments. Results on these environments show that our algorithm (TDHER+KFAC) performs better inmost of the scenarios
Learning Active Spine Behaviors for Dynamic and Efficient Locomotion in Quadruped Robots
May 16, 2019
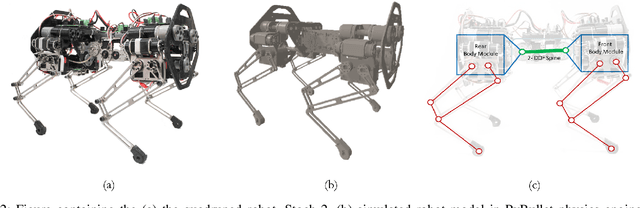
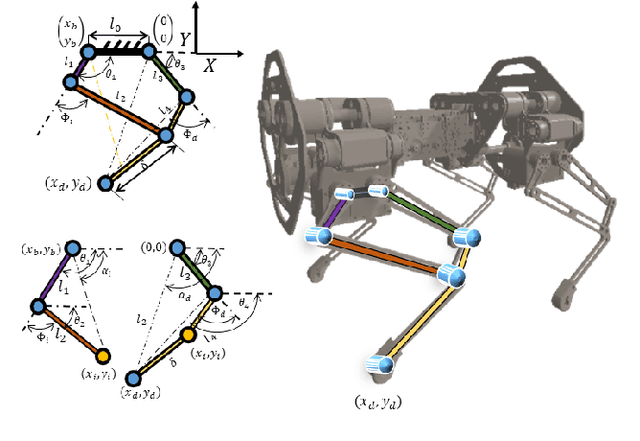
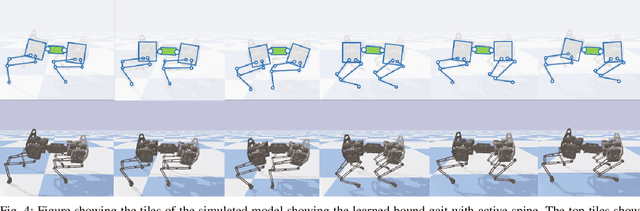
In this work, we provide a simulation framework to perform systematic studies on the effects of spinal joint compliance and actuation on bounding performance of a 16-DOF quadruped spined robot Stoch 2. Fast quadrupedal locomotion with active spine is an extremely hard problem, and involves a complex coordination between the various degrees of freedom. Therefore, past attempts at addressing this problem have not seen much success. Deep-Reinforcement Learning seems to be a promising approach, after its recent success in a variety of robot platforms, and the goal of this paper is to use this approach to realize the aforementioned behaviors. With this learning framework, the robot reached a bounding speed of 2.1 m/s with a maximum Froude number of 2. Simulation results also show that use of active spine, indeed, increased the stride length, improved the cost of transport, and also reduced the natural frequency to more realistic values.
Design, Development and Experimental Realization of a Quadrupedal Research Platform: Stoch
Feb 27, 2019
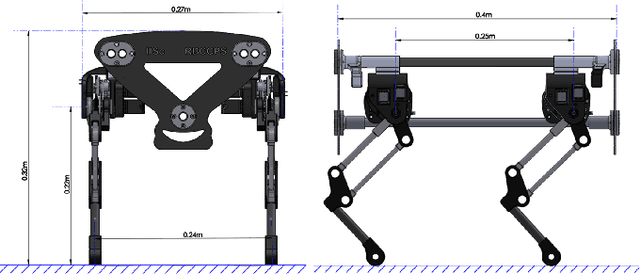
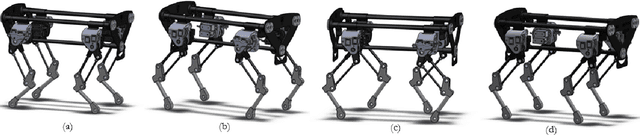
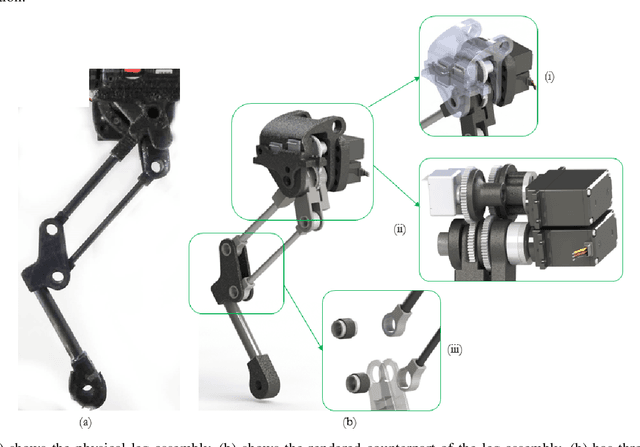
In this paper, we present a complete description of the hardware design and control architecture of our custom built quadruped robot, called the `Stoch'. Our goal is to realize a robust, modular, and a reliable quadrupedal platform, using which various locomotion behaviors are explored. This platform enables us to explore different research problems in legged locomotion, which use both traditional and learning based techniques. We discuss the merits and limitations of the platform in terms of exploitation of available behaviours, fast rapid prototyping, reproduction and repair. Towards the end, we will demonstrate trotting, bounding behaviors, and preliminary results in turning. In addition, we will also show various gait transitions i.e., trot-to-turn and trot-to-bound behaviors.
Realizing Learned Quadruped Locomotion Behaviors through Kinematic Motion Primitives
Feb 26, 2019
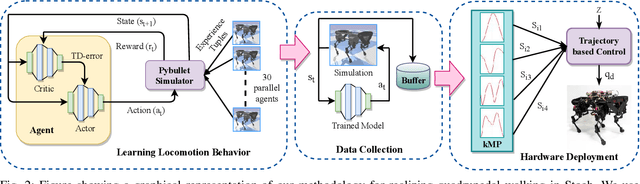
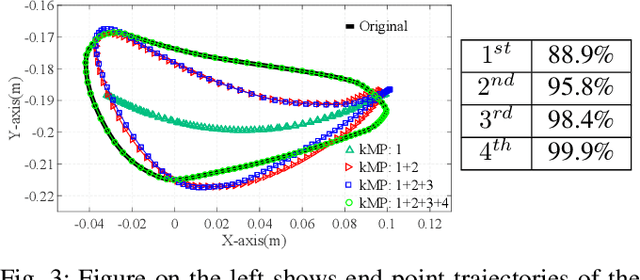
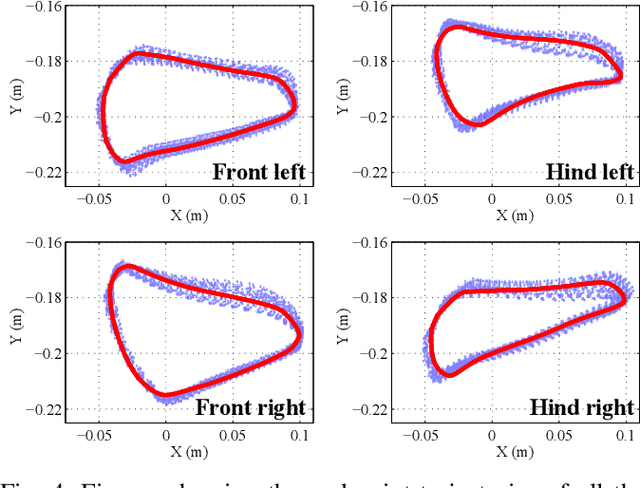
Humans and animals are believed to use a very minimal set of trajectories to perform a wide variety of tasks including walking. Our main objective in this paper is two fold 1) Obtain an effective tool to realize these basic motion patterns for quadrupedal walking, called the kinematic motion primitives (kMPs), via trajectories learned from deep reinforcement learning (D-RL) and 2) Realize a set of behaviors, namely trot, walk, gallop and bound from these kinematic motion primitives in our custom four legged robot, called the `Stoch'. D-RL is a data driven approach, which has been shown to be very effective for realizing all kinds of robust locomotion behaviors, both in simulation and in experiment. On the other hand, kMPs are known to capture the underlying structure of walking and yield a set of derived behaviors. We first generate walking gaits from D-RL, which uses policy gradient based approaches. We then analyze the resulting walking by using principal component analysis. We observe that the kMPs extracted from PCA followed a similar pattern irrespective of the type of gaits generated. Leveraging on this underlying structure, we then realize walking in Stoch by a straightforward reconstruction of joint trajectories from kMPs. This type of methodology improves the transferability of these gaits to real hardware, lowers the computational overhead on-board, and also avoids multiple training iterations by generating a set of derived behaviors from a single learned gait.
Memory-based Deep Reinforcement Learning for Obstacle Avoidance in UAV with Limited Environment Knowledge
Nov 08, 2018
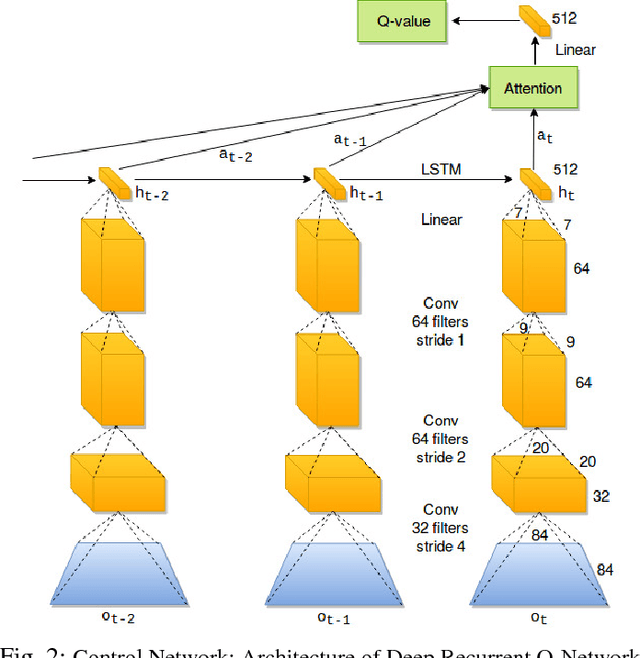
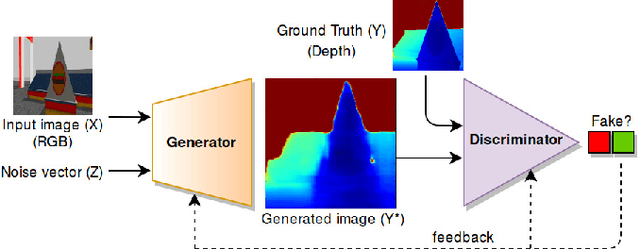

This paper presents our method for enabling a UAV quadrotor, equipped with a monocular camera, to autonomously avoid collisions with obstacles in unstructured and unknown indoor environments. When compared to obstacle avoidance in ground vehicular robots, UAV navigation brings in additional challenges because the UAV motion is no more constrained to a well-defined indoor ground or street environment. Horizontal structures in indoor and outdoor environments like decorative items, furnishings, ceiling fans, sign-boards, tree branches etc., also become relevant obstacles unlike those for ground vehicular robots. Thus, methods of obstacle avoidance developed for ground robots are clearly inadequate for UAV navigation. Current control methods using monocular images for UAV obstacle avoidance are heavily dependent on environment information. These controllers do not fully retain and utilize the extensively available information about the ambient environment for decision making. We propose a deep reinforcement learning based method for UAV obstacle avoidance (OA) and autonomous exploration which is capable of doing exactly the same. The crucial idea in our method is the concept of partial observability and how UAVs can retain relevant information about the environment structure to make better future navigation decisions. Our OA technique uses recurrent neural networks with temporal attention and provides better results compared to prior works in terms of distance covered during navigation without collisions. In addition, our technique has a high inference rate (a key factor in robotic applications) and is energy-efficient as it minimizes oscillatory motion of UAV and reduces power wastage.
Visual Rendering of Shapes on 2D Display Devices Guided by Hand Gestures
Oct 22, 2018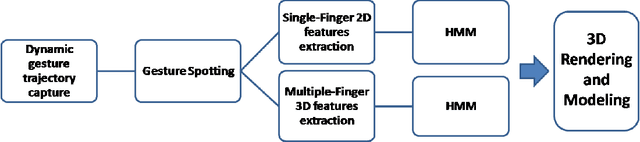
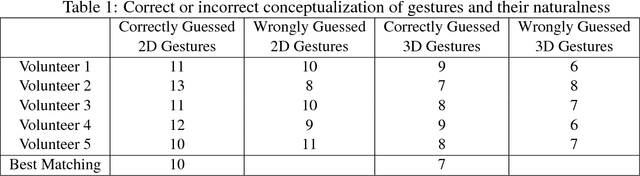


Designing of touchless user interface is gaining popularity in various contexts. Using such interfaces, users can interact with electronic devices even when the hands are dirty or non-conductive. Also, user with partial physical disability can interact with electronic devices using such systems. Research in this direction has got major boost because of the emergence of low-cost sensors such as Leap Motion, Kinect or RealSense devices. In this paper, we propose a Leap Motion controller-based methodology to facilitate rendering of 2D and 3D shapes on display devices. The proposed method tracks finger movements while users perform natural gestures within the field of view of the sensor. In the next phase, trajectories are analyzed to extract extended Npen++ features in 3D. These features represent finger movements during the gestures and they are fed to unidirectional left-to-right Hidden Markov Model (HMM) for training. A one-to-one mapping between gestures and shapes is proposed. Finally, shapes corresponding to these gestures are rendered over the display using MuPad interface. We have created a dataset of 5400 samples recorded by 10 volunteers. Our dataset contains 18 geometric and 18 non-geometric shapes such as "circle", "rectangle", "flower", "cone", "sphere" etc. The proposed methodology achieves an accuracy of 92.87% when evaluated using 5-fold cross validation method. Our experiments revel that the extended 3D features perform better than existing 3D features in the context of shape representation and classification. The method can be used for developing useful HCI applications for smart display devices.