 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenTRIM: Tool Risk Mitigation for Agentic AI
Jan 18, 2026AI agents are autonomous systems that combine LLMs with external tools to solve complex tasks. While such tools extend capability, improper tool permissions introduce security risks such as indirect prompt injection and tool misuse. We characterize these failures as unbalanced tool-driven agency. Agents may retain unnecessary permissions (excessive agency) or fail to invoke required tools (insufficient agency), amplifying the attack surface and reducing performance. We introduce AgenTRIM, a framework for detecting and mitigating tool-driven agency risks without altering an agent's internal reasoning. AgenTRIM addresses these risks through complementary offline and online phases. Offline, AgenTRIM reconstructs and verifies the agent's tool interface from code and execution traces. At runtime, it enforces per-step least-privilege tool access through adaptive filtering and status-aware validation of tool calls. Evaluating on the AgentDojo benchmark, AgenTRIM substantially reduces attack success while maintaining high task performance. Additional experiments show robustness to description-based attacks and effective enforcement of explicit safety policies. Together, these results demonstrate that AgenTRIM provides a practical, capability-preserving approach to safer tool use in LLM-based agents.
A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments
May 19, 2020

Reinforcement learning (RL) algorithms find applications in inventory control, recommender systems, vehicular traffic management, cloud computing and robotics. The real-world complications of many tasks arising in these domains makes them difficult to solve with the basic assumptions underlying classical RL algorithms. RL agents in these applications often need to react and adapt to changing operating conditions. A significant part of research on single-agent RL techniques focuses on developing algorithms when the underlying assumption of stationary environment model is relaxed. This paper provides a survey of RL methods developed for handling dynamically varying environment models. The goal of methods not limited by the stationarity assumption is to help autonomous agents adapt to varying operating conditions. This is possible either by minimizing the rewards lost during learning by RL agent or by finding a suitable policy for the RL agent which leads to efficient operation of the underlying system. A representative collection of these algorithms is discussed in detail in this work along with their categorization and their relative merits and demerits. Additionally we also review works which are tailored to application domains. Finally, we discuss future enhancements for this field.
Reinforcement Learning in Non-Stationary Environments
May 10, 2019



Reinforcement learning (RL) methods learn optimal decisions in the presence of a stationary environment. However, the stationary assumption on the environment is very restrictive. In many real world problems like traffic signal control, robotic applications, one often encounters situations with non-stationary environments and in these scenarios, RL methods yield sub-optimal decisions. In this paper, we thus consider the problem of developing RL methods that obtain optimal decisions in a non-stationary environment. The goal of this problem is to maximize the long-term discounted reward achieved when the underlying model of the environment changes over time. To achieve this, we first adapt a change point algorithm to detect change in the statistics of the environment and then develop an RL algorithm that maximizes the long-run reward accrued. We illustrate that our change point method detects change in the model of the environment effectively and thus facilitates the RL algorithm in maximizing the long-run reward. We further validate the effectiveness of the proposed solution on non-stationary random Markov decision processes, a sensor energy management problem and a traffic signal control problem.
Memory-based Deep Reinforcement Learning for Obstacle Avoidance in UAV with Limited Environment Knowledge
Nov 08, 2018
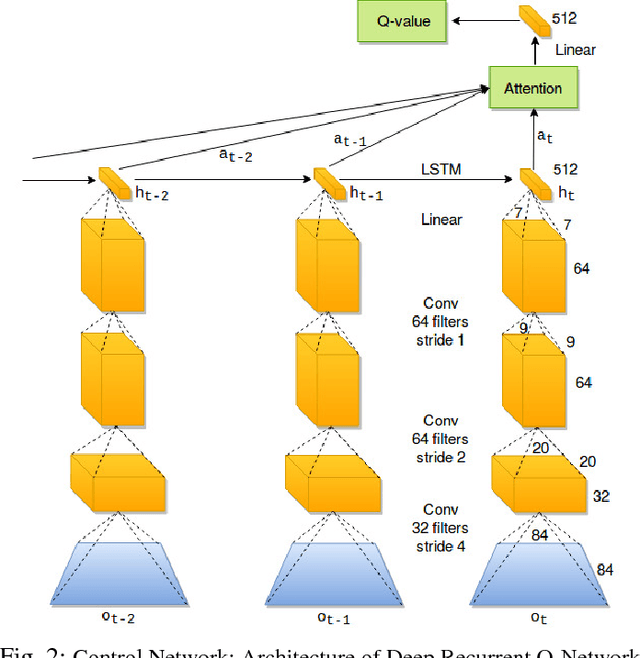
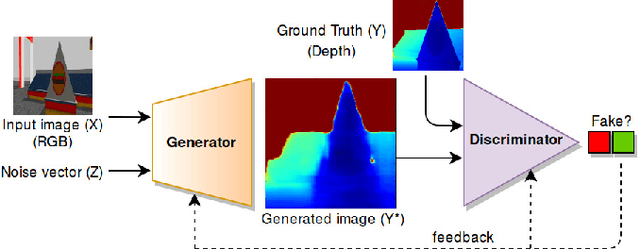

This paper presents our method for enabling a UAV quadrotor, equipped with a monocular camera, to autonomously avoid collisions with obstacles in unstructured and unknown indoor environments. When compared to obstacle avoidance in ground vehicular robots, UAV navigation brings in additional challenges because the UAV motion is no more constrained to a well-defined indoor ground or street environment. Horizontal structures in indoor and outdoor environments like decorative items, furnishings, ceiling fans, sign-boards, tree branches etc., also become relevant obstacles unlike those for ground vehicular robots. Thus, methods of obstacle avoidance developed for ground robots are clearly inadequate for UAV navigation. Current control methods using monocular images for UAV obstacle avoidance are heavily dependent on environment information. These controllers do not fully retain and utilize the extensively available information about the ambient environment for decision making. We propose a deep reinforcement learning based method for UAV obstacle avoidance (OA) and autonomous exploration which is capable of doing exactly the same. The crucial idea in our method is the concept of partial observability and how UAVs can retain relevant information about the environment structure to make better future navigation decisions. Our OA technique uses recurrent neural networks with temporal attention and provides better results compared to prior works in terms of distance covered during navigation without collisions. In addition, our technique has a high inference rate (a key factor in robotic applications) and is energy-efficient as it minimizes oscillatory motion of UAV and reduces power wastage.
Performance Tuning of Hadoop MapReduce: A Noisy Gradient Approach
Dec 16, 2016



Hadoop MapReduce is a framework for distributed storage and processing of large datasets that is quite popular in big data analytics. It has various configuration parameters (knobs) which play an important role in deciding the performance i.e., the execution time of a given big data processing job. Default values of these parameters do not always result in good performance and hence it is important to tune them. However, there is inherent difficulty in tuning the parameters due to two important reasons - firstly, the parameter search space is large and secondly, there are cross-parameter interactions. Hence, there is a need for a dimensionality-free method which can automatically tune the configuration parameters by taking into account the cross-parameter dependencies. In this paper, we propose a novel Hadoop parameter tuning methodology, based on a noisy gradient algorithm known as the simultaneous perturbation stochastic approximation (SPSA). The SPSA algorithm tunes the parameters by directly observing the performance of the Hadoop MapReduce system. The approach followed is independent of parameter dimensions and requires only $2$ observations per iteration while tuning. We demonstrate the effectiveness of our methodology in achieving good performance on popular Hadoop benchmarks namely \emph{Grep}, \emph{Bigram}, \emph{Inverted Index}, \emph{Word Co-occurrence} and \emph{Terasort}. Our method, when tested on a 25 node Hadoop cluster shows 66\% decrease in execution time of Hadoop jobs on an average, when compared to the default configuration. Further, we also observe a reduction of 45\% in execution times, when compared to prior methods.
Energy Sharing for Multiple Sensor Nodes with Finite Buffers
Mar 17, 2015



We consider the problem of finding optimal energy sharing policies that maximize the network performance of a system comprising of multiple sensor nodes and a single energy harvesting (EH) source. Sensor nodes periodically sense the random field and generate data, which is stored in the corresponding data queues. The EH source harnesses energy from ambient energy sources and the generated energy is stored in an energy buffer. Sensor nodes receive energy for data transmission from the EH source. The EH source has to efficiently share the stored energy among the nodes in order to minimize the long-run average delay in data transmission. We formulate the problem of energy sharing between the nodes in the framework of average cost infinite-horizon Markov decision processes (MDPs). We develop efficient energy sharing algorithms, namely Q-learning algorithm with exploration mechanisms based on the $\epsilon$-greedy method as well as upper confidence bound (UCB). We extend these algorithms by incorporating state and action space aggregation to tackle state-action space explosion in the MDP. We also develop a cross entropy based method that incorporates policy parameterization in order to find near optimal energy sharing policies. Through simulations, we show that our algorithms yield energy sharing policies that outperform the heuristic greedy method.