 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVIPER: Improved Policy Distillation for Reinforcement-Learning-Based Robot Navigation
Sep 19, 2022
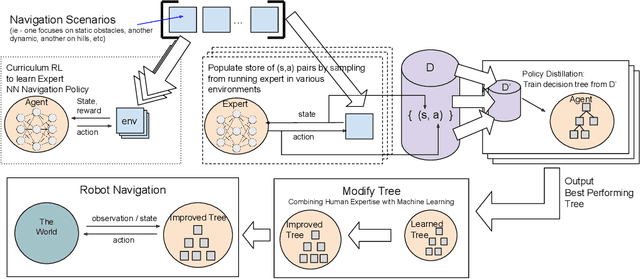
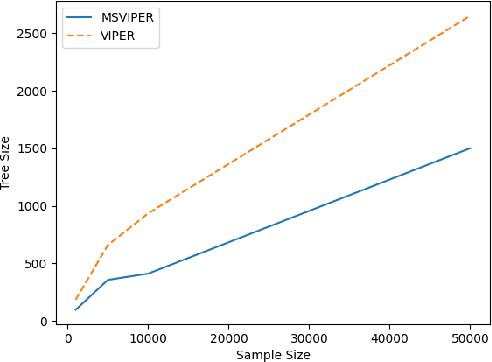

We present Multiple Scenario Verifiable Reinforcement Learning via Policy Extraction (MSVIPER), a new method for policy distillation to decision trees for improved robot navigation. MSVIPER learns an "expert" policy using any Reinforcement Learning (RL) technique involving learning a state-action mapping and then uses imitation learning to learn a decision-tree policy from it. We demonstrate that MSVIPER results in efficient decision trees and can accurately mimic the behavior of the expert policy. Moreover, we present efficient policy distillation and tree-modification techniques that take advantage of the decision tree structure to allow improvements to a policy without retraining. We use our approach to improve the performance of RL-based robot navigation algorithms for indoor and outdoor scenes. We demonstrate the benefits in terms of reduced freezing and oscillation behaviors (by up to 95\% reduction) for mobile robots navigating among dynamic obstacles and reduced vibrations and oscillation (by up to 17\%) for outdoor robot navigation on complex, uneven terrains.
XAI-N: Sensor-based Robot Navigation using Expert Policies and Decision Trees
Apr 22, 2021
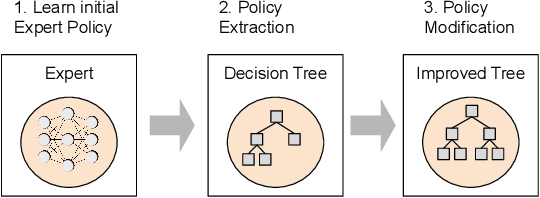


We present a novel sensor-based learning navigation algorithm to compute a collision-free trajectory for a robot in dense and dynamic environments with moving obstacles or targets. Our approach uses deep reinforcement learning-based expert policy that is trained using a sim2real paradigm. In order to increase the reliability and handle the failure cases of the expert policy, we combine with a policy extraction technique to transform the resulting policy into a decision tree format. The resulting decision tree has properties which we use to analyze and modify the policy and improve performance on navigation metrics including smoothness, frequency of oscillation, frequency of immobilization, and obstruction of target. We are able to modify the policy to address these imperfections without retraining, combining the learning power of deep learning with the control of domain-specific algorithms. We highlight the benefits of our algorithm in simulated environments and navigating a Clearpath Jackal robot among moving pedestrians.
A Robot's Expressive Language Affects Human Strategy and Perceptions in a Competitive Game
Oct 24, 2019
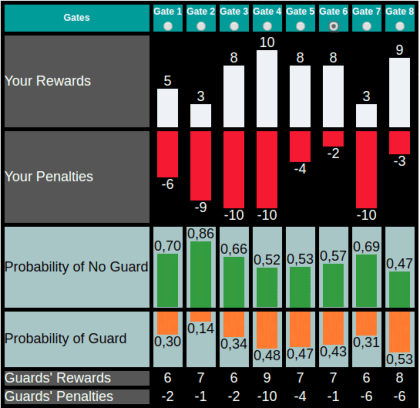
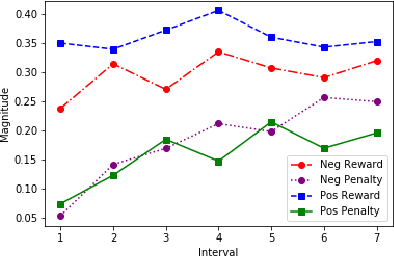

As robots are increasingly endowed with social and communicative capabilities, they will interact with humans in more settings, both collaborative and competitive. We explore human-robot relationships in the context of a competitive Stackelberg Security Game. We vary humanoid robot expressive language (in the form of "encouraging" or "discouraging" verbal commentary) and measure the impact on participants' rationality, strategy prioritization, mood, and perceptions of the robot. We learn that a robot opponent that makes discouraging comments causes a human to play a game less rationally and to perceive the robot more negatively. We also contribute a simple open source Natural Language Processing framework for generating expressive sentences, which was used to generate the speech of our autonomous social robot.
* RO-MAN 2019; 8 pages, 4 figures, 1 table
Conservative Q-Improvement: Reinforcement Learning for an Interpretable Decision-Tree Policy
Jul 02, 2019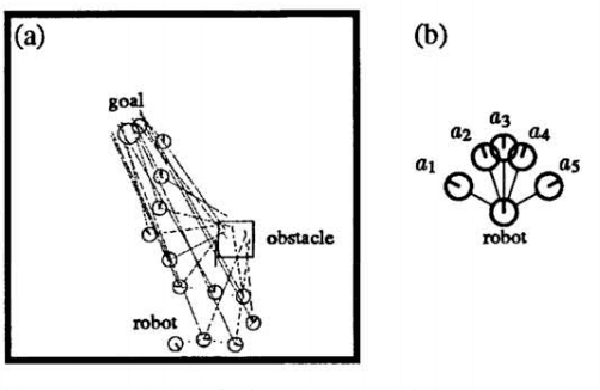

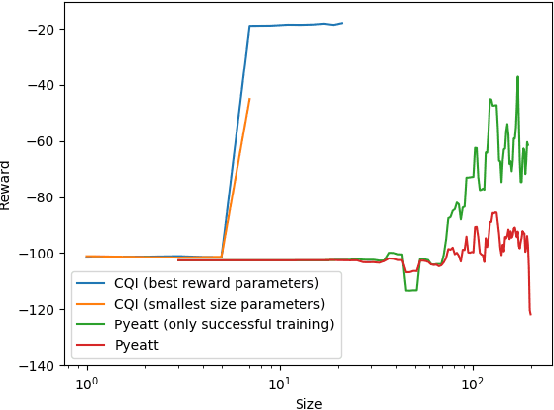
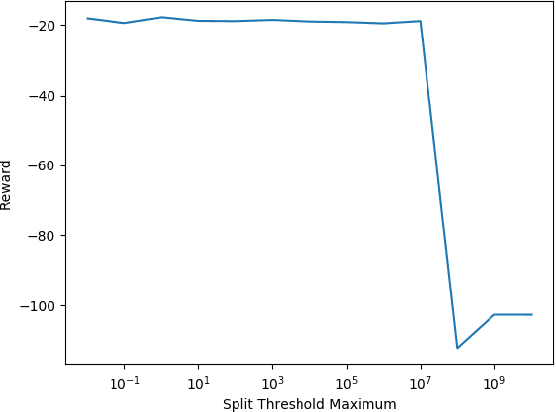
There is a growing desire in the field of reinforcement learning (and machine learning in general) to move from black-box models toward more "interpretable AI." We improve interpretability of reinforcement learning by increasing the utility of decision tree policies learned via reinforcement learning. These policies consist of a decision tree over the state space, which requires fewer parameters to express than traditional policy representations. Existing methods for creating decision tree policies via reinforcement learning focus on accurately representing an action-value function during training, but this leads to much larger trees than would otherwise be required. To address this shortcoming, we propose a novel algorithm which only increases tree size when the estimated discounted future reward of the overall policy would increase by a sufficient amount. Through evaluation in a simulated environment, we show that its performance is comparable or superior to traditional tree-based approaches and that it yields a more succinct policy. Additionally, we discuss tuning parameters to control the tradeoff between optimizing for smaller tree size or for overall reward.
The Impact of Humanoid Affect Expression on Human Behavior in a Game-Theoretic Setting
Jun 10, 2018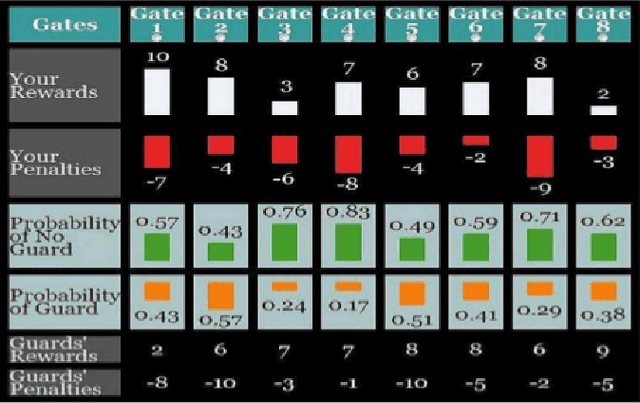
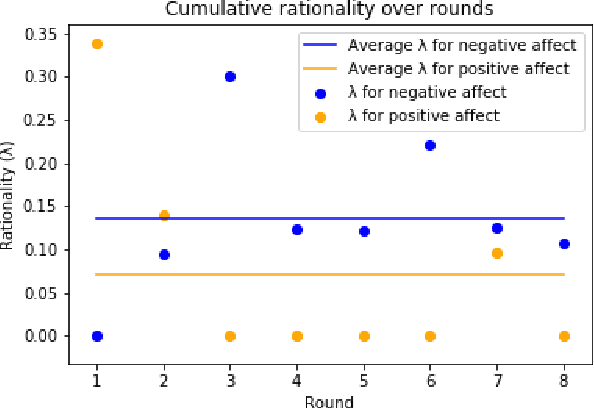
With the rapid development of robot and other intelligent and autonomous agents, how a human could be influenced by a robot's expressed mood when making decisions becomes a crucial question in human-robot interaction. In this pilot study, we investigate (1) in what way a robot can express a certain mood to influence a human's decision making behavioral model; (2) how and to what extent the human will be influenced in a game theoretic setting. More specifically, we create an NLP model to generate sentences that adhere to a specific affective expression profile. We use these sentences for a humanoid robot as it plays a Stackelberg security game against a human. We investigate the behavioral model of the human player.