 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Jun 11, 2026Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
MSVIPER: Improved Policy Distillation for Reinforcement-Learning-Based Robot Navigation
Sep 19, 2022
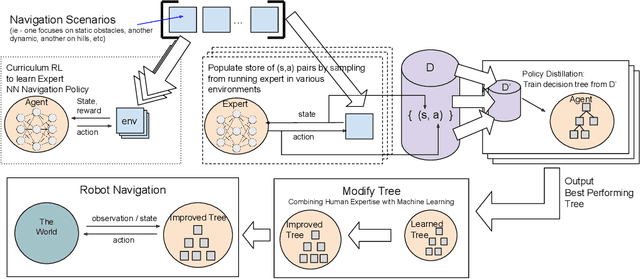
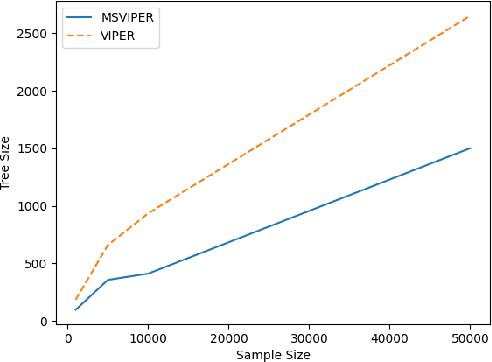

We present Multiple Scenario Verifiable Reinforcement Learning via Policy Extraction (MSVIPER), a new method for policy distillation to decision trees for improved robot navigation. MSVIPER learns an "expert" policy using any Reinforcement Learning (RL) technique involving learning a state-action mapping and then uses imitation learning to learn a decision-tree policy from it. We demonstrate that MSVIPER results in efficient decision trees and can accurately mimic the behavior of the expert policy. Moreover, we present efficient policy distillation and tree-modification techniques that take advantage of the decision tree structure to allow improvements to a policy without retraining. We use our approach to improve the performance of RL-based robot navigation algorithms for indoor and outdoor scenes. We demonstrate the benefits in terms of reduced freezing and oscillation behaviors (by up to 95\% reduction) for mobile robots navigating among dynamic obstacles and reduced vibrations and oscillation (by up to 17\%) for outdoor robot navigation on complex, uneven terrains.
Altered Fingerprints: Detection and Localization
Sep 18, 2018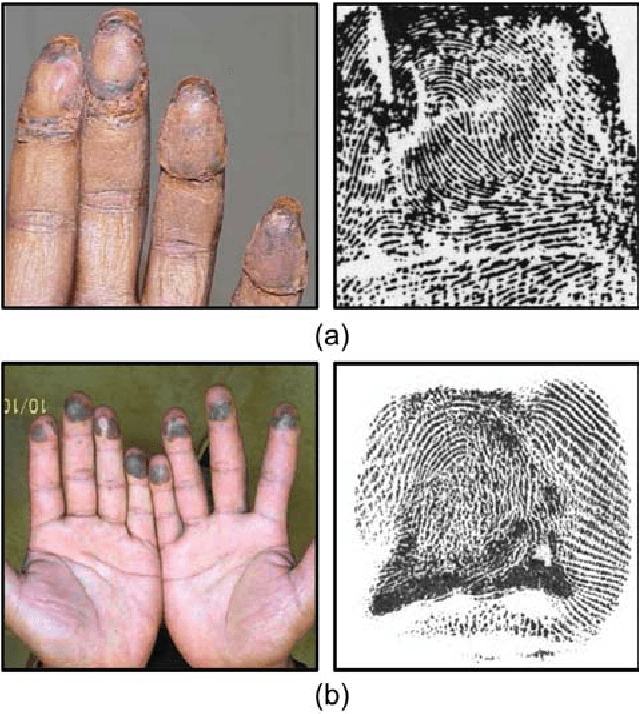

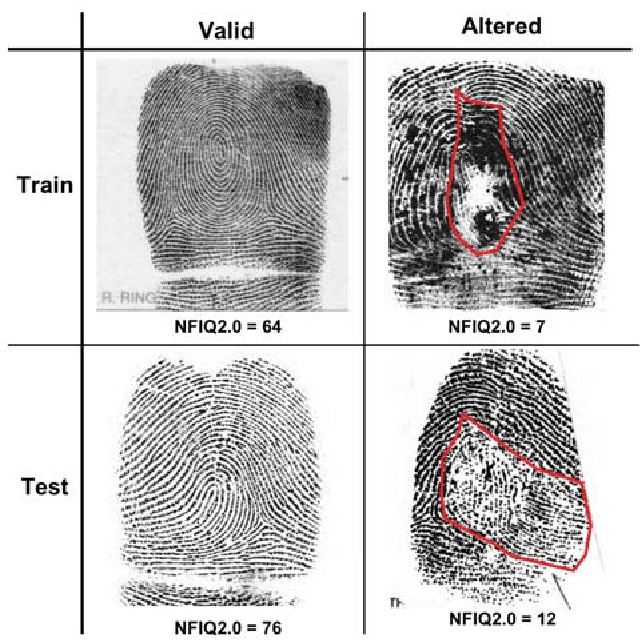
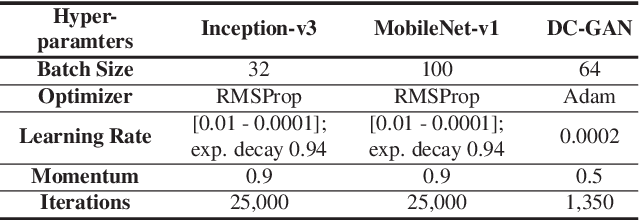
Fingerprint alteration, also referred to as obfuscation presentation attack, is to intentionally tamper or damage the real friction ridge patterns to avoid identification by an AFIS. This paper proposes a method for detection and localization of fingerprint alterations. Our main contributions are: (i) design and train CNN models on fingerprint images and minutiae-centered local patches in the image to detect and localize regions of fingerprint alterations, and (ii) train a Generative Adversarial Network (GAN) to synthesize altered fingerprints whose characteristics are similar to true altered fingerprints. A successfully trained GAN can alleviate the limited availability of altered fingerprint images for research. A database of 4,815 altered fingerprints from 270 subjects, and an equal number of rolled fingerprint images are used to train and test our models. The proposed approach achieves a True Detection Rate (TDR) of 99.24% at a False Detection Rate (FDR) of 2%, outperforming published results. The synthetically generated altered fingerprint dataset will be open-sourced.