 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Multi-Contact Receding Horizon Planning via Value Function Approximation
Paper and Code
Jun 12, 2023
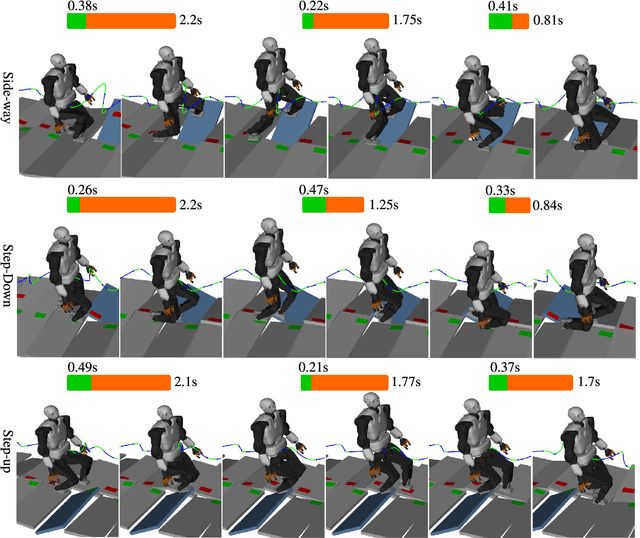


Planning multi-contact motions in a receding horizon fashion requires a value function to guide the planning with respect to the future, e.g., building momentum to traverse large obstacles. Traditionally, the value function is approximated by computing trajectories in a prediction horizon (never executed) that foresees the future beyond the execution horizon. However, given the non-convex dynamics of multi-contact motions, this approach is computationally expensive. To enable online Receding Horizon Planning (RHP) of multi-contact motions, we find efficient approximations of the value function. Specifically, we propose a trajectory-based and a learning-based approach. In the former, namely RHP with Multiple Levels of Model Fidelity, we approximate the value function by computing the prediction horizon with a convex relaxed model. In the latter, namely Locally-Guided RHP, we learn an oracle to predict local objectives for locomotion tasks, and we use these local objectives to construct local value functions for guiding a short-horizon RHP. We evaluate both approaches in simulation by planning centroidal trajectories of a humanoid robot walking on moderate slopes, and on large slopes where the robot cannot maintain static balance. Our results show that locally-guided RHP achieves the best computation efficiency (95\%-98.6\% cycles converge online). This computation advantage enables us to demonstrate online receding horizon planning of our real-world humanoid robot Talos walking in dynamic environments that change on-the-fly.