 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFetusMap: Fetal Pose Estimation in 3D Ultrasound
Paper and Code
Oct 11, 2019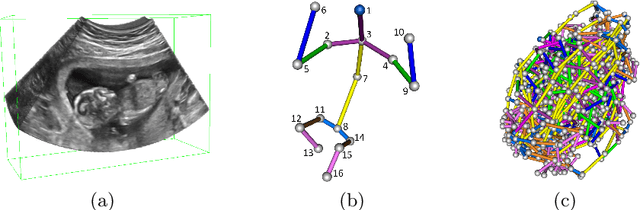
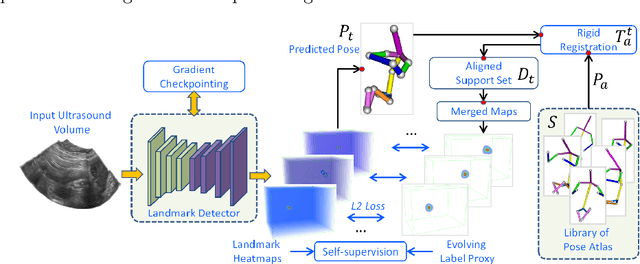
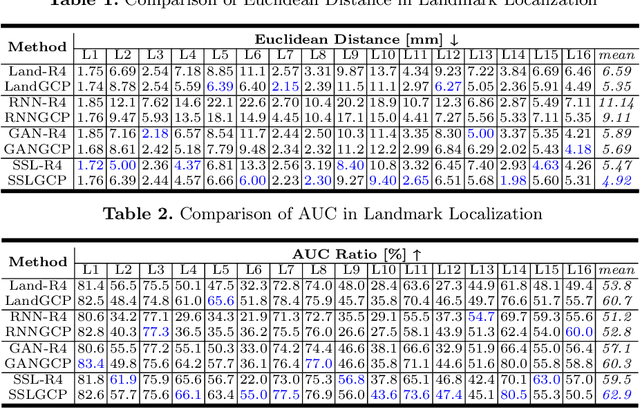
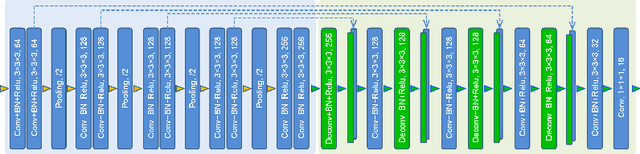
The 3D ultrasound (US) entrance inspires a multitude of automated prenatal examinations. However, studies about the structuralized description of the whole fetus in 3D US are still rare. In this paper, we propose to estimate the 3D pose of fetus in US volumes to facilitate its quantitative analyses in global and local scales. Given the great challenges in 3D US, including the high volume dimension, poor image quality, symmetric ambiguity in anatomical structures and large variations of fetal pose, our contribution is three-fold. (i) This is the first work about 3D pose estimation of fetus in the literature. We aim to extract the skeleton of whole fetus and assign different segments/joints with correct torso/limb labels. (ii) We propose a self-supervised learning (SSL) framework to finetune the deep network to form visually plausible pose predictions. Specifically, we leverage the landmark-based registration to effectively encode case-adaptive anatomical priors and generate evolving label proxy for supervision. (iii) To enable our 3D network perceive better contextual cues with higher resolution input under limited computing resource, we further adopt the gradient check-pointing (GCP) strategy to save GPU memory and improve the prediction. Extensively validated on a large 3D US dataset, our method tackles varying fetal poses and achieves promising results. 3D pose estimation of fetus has potentials in serving as a map to provide navigation for many advanced studies.