 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search
Paper and Code
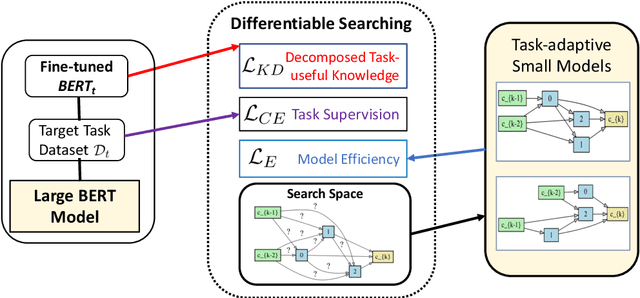
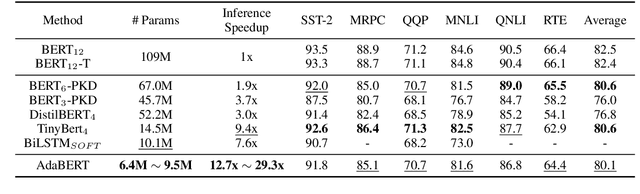
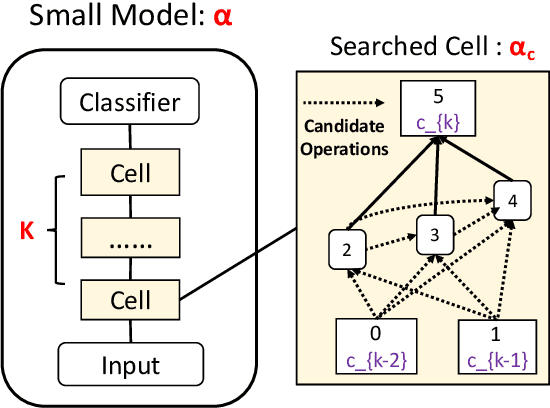
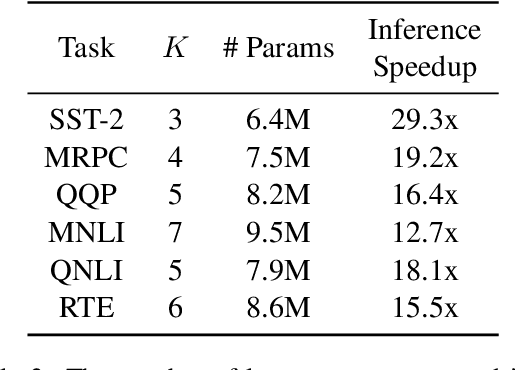
Large pre-trained language models such as BERT have shown their effectiveness in various natural language processing tasks. However, the huge parameter size makes them difficult to be deployed in real-time applications that require quick inference with limited resources. Existing methods compress BERT into small models while such compression is task-independent, i.e., the same compressed BERT for all different downstream tasks. Motivated by the necessity and benefits of task-oriented BERT compression, we propose a novel compression method, AdaBERT, that leverages differentiable Neural Architecture Search to automatically compress BERT into task-adaptive small models for specific tasks. We incorporate a task-oriented knowledge distillation loss to provide search hints and an efficiency-aware loss as search constraints, which enables a good trade-off between efficiency and effectiveness for task-adaptive BERT compression. We evaluate AdaBERT on several NLP tasks, and the results demonstrate that those task-adaptive compressed models are 12.7x to 29.3x faster than BERT in inference time and 11.5x to 17.0x smaller in terms of parameter size, while comparable performance is maintained.