 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Position Debiasing for Large Language Models
Jan 02, 2024
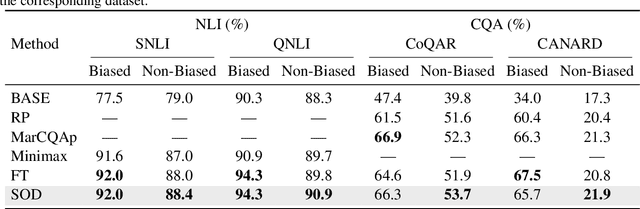


Fine-tuning has been demonstrated to be an effective method to improve the domain performance of large language models (LLMs). However, LLMs might fit the dataset bias and shortcuts for prediction, leading to poor generation performance. Experimental result shows that LLMs are prone to exhibit position bias, i.e., leveraging information positioned at the beginning or end, or specific positional cues within the input. Existing works on mitigating position bias require external bias knowledge or annotated non-biased samples, which is unpractical in reality. In this work, we propose a zero-shot position debiasing (ZOE) framework to mitigate position bias for LLMs. ZOE leverages unsupervised responses from pre-trained LLMs for debiasing, thus without any external knowledge or datasets. To improve the quality of unsupervised responses, we propose a master-slave alignment (MSA) module to prune these responses. Experiments on eight datasets and five tasks show that ZOE consistently outperforms existing methods in mitigating four types of position biases. Besides, ZOE achieves this by sacrificing only a small performance on biased samples, which is simple and effective.
From LSAT: The Progress and Challenges of Complex Reasoning
Aug 02, 2021



Complex reasoning aims to draw a correct inference based on complex rules. As a hallmark of human intelligence, it involves a degree of explicit reading comprehension, interpretation of logical knowledge and complex rule application. In this paper, we take a step forward in complex reasoning by systematically studying the three challenging and domain-general tasks of the Law School Admission Test (LSAT), including analytical reasoning, logical reasoning and reading comprehension. We propose a hybrid reasoning system to integrate these three tasks and achieve impressive overall performance on the LSAT tests. The experimental results demonstrate that our system endows itself a certain complex reasoning ability, especially the fundamental reading comprehension and challenging logical reasoning capacities. Further analysis also shows the effectiveness of combining the pre-trained models with the task-specific reasoning module, and integrating symbolic knowledge into discrete interpretable reasoning steps in complex reasoning. We further shed a light on the potential future directions, like unsupervised symbolic knowledge extraction, model interpretability, few-shot learning and comprehensive benchmark for complex reasoning.
Learning to Ask Conversational Questions by Optimizing Levenshtein Distance
Jun 30, 2021
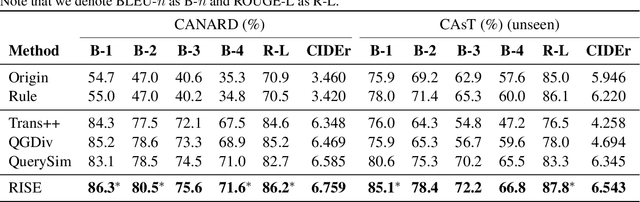


Conversational Question Simplification (CQS) aims to simplify self-contained questions into conversational ones by incorporating some conversational characteristics, e.g., anaphora and ellipsis. Existing maximum likelihood estimation (MLE) based methods often get trapped in easily learned tokens as all tokens are treated equally during training. In this work, we introduce a Reinforcement Iterative Sequence Editing (RISE) framework that optimizes the minimum Levenshtein distance (MLD) through explicit editing actions. RISE is able to pay attention to tokens that are related to conversational characteristics. To train RISE, we devise an Iterative Reinforce Training (IRT) algorithm with a Dynamic Programming based Sampling (DPS) process to improve exploration. Experimental results on two benchmark datasets show that RISE significantly outperforms state-of-the-art methods and generalizes well on unseen data.
Wizard of Search Engine: Access to Information Through Conversations with Search Engines
May 18, 2021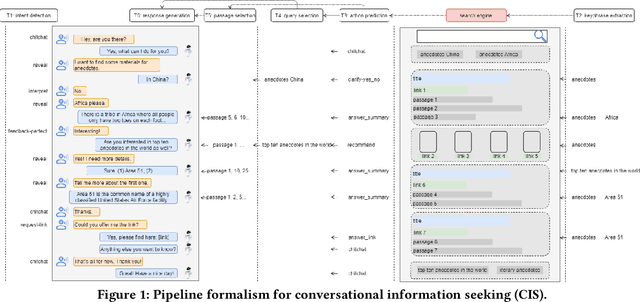


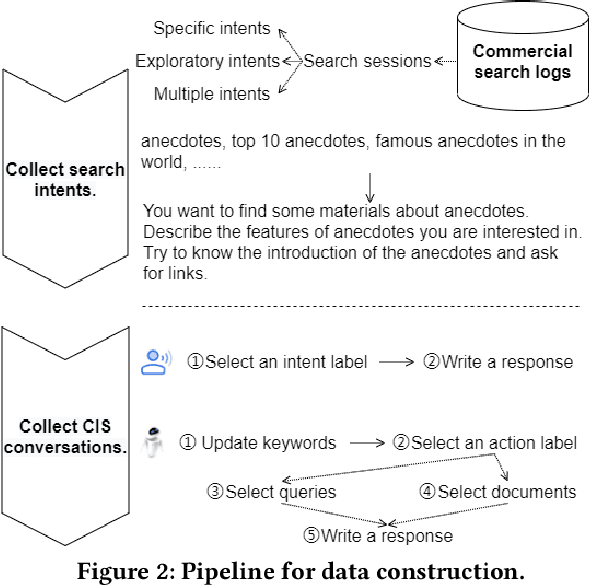
Conversational information seeking (CIS) is playing an increasingly important role in connecting people to information. Due to the lack of suitable resource, previous studies on CIS are limited to the study of theoretical/conceptual frameworks, laboratory-based user studies, or a particular aspect of CIS (e.g., asking clarifying questions). In this work, we make efforts to facilitate research on CIS from three aspects. (1) We formulate a pipeline for CIS with six sub-tasks: intent detection (ID), keyphrase extraction (KE), action prediction (AP), query selection (QS), passage selection (PS), and response generation (RG). (2) We release a benchmark dataset, called wizard of search engine (WISE), which allows for comprehensive and in-depth research on all aspects of CIS. (3) We design a neural architecture capable of training and evaluating both jointly and separately on the six sub-tasks, and devise a pre-train/fine-tune learning scheme, that can reduce the requirements of WISE in scale by making full use of available data. We report some useful characteristics of CIS based on statistics of WISE. We also show that our best performing model variant isable to achieve effective CIS as indicated by several metrics. We release the dataset, the code, as well as the evaluation scripts to facilitate future research by measuring further improvements in this important research direction.