 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Batch Learning in Finite-Action Linear Contextual Bandits
Apr 14, 2020We study the sequential batch learning problem in linear contextual bandits with finite action sets, where the decision maker is constrained to split incoming individuals into (at most) a fixed number of batches and can only observe outcomes for the individuals within a batch at the batch's end. Compared to both standard online contextual bandits learning or offline policy learning in contexutal bandits, this sequential batch learning problem provides a finer-grained formulation of many personalized sequential decision making problems in practical applications, including medical treatment in clinical trials, product recommendation in e-commerce and adaptive experiment design in crowdsourcing. We study two settings of the problem: one where the contexts are arbitrarily generated and the other where the contexts are \textit{iid} drawn from some distribution. In each setting, we establish a regret lower bound and provide an algorithm, whose regret upper bound nearly matches the lower bound. As an important insight revealed therefrom, in the former setting, we show that the number of batches required to achieve the fully online performance is polynomial in the time horizon, while for the latter setting, a pure-exploitation algorithm with a judicious batch partition scheme achieves the fully online performance even when the number of batches is less than logarithmic in the time horizon. Together, our results provide a near-complete characterization of sequential decision making in linear contextual bandits when batch constraints are present.
Batched Multi-armed Bandits Problem
Apr 03, 2019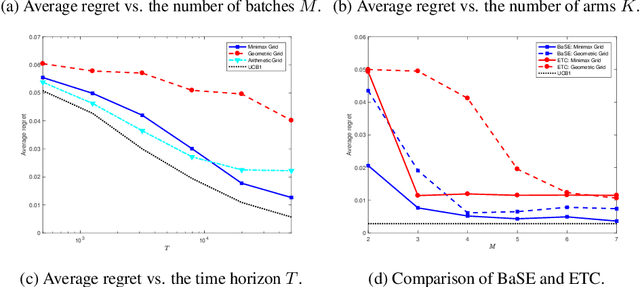
In this paper, we study the multi-armed bandit problem in the batched setting where the employed policy must split data into a small number of batches. While the minimax regret for the two-armed stochastic bandits has been completely characterized in \cite{perchet2016batched}, the effect of the number of arms on the regret for the multi-armed case is still open. Moreover, the question whether adaptively chosen batch sizes will help to reduce the regret also remains underexplored. In this paper, we propose the BaSE (batched successive elimination) policy to achieve the rate-optimal regret (within logarithmic factors) for batched multi-armed bandits, with matching lower bounds even if the batch sizes are determined in a data-driven manner.