Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatched Multi-armed Bandits Problem
Paper and Code
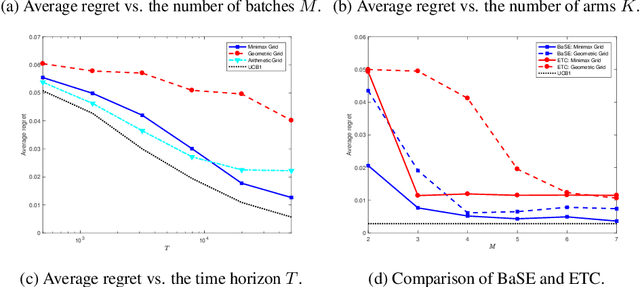
In this paper, we study the multi-armed bandit problem in the batched setting where the employed policy must split data into a small number of batches. While the minimax regret for the two-armed stochastic bandits has been completely characterized in \cite{perchet2016batched}, the effect of the number of arms on the regret for the multi-armed case is still open. Moreover, the question whether adaptively chosen batch sizes will help to reduce the regret also remains underexplored. In this paper, we propose the BaSE (batched successive elimination) policy to achieve the rate-optimal regret (within logarithmic factors) for batched multi-armed bandits, with matching lower bounds even if the batch sizes are determined in a data-driven manner.
View paper on