 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Prompt Tuning for Universal Sound Separation
Nov 30, 2023Universal sound separation (USS) is a task to separate arbitrary sounds from an audio mixture. Existing USS systems are capable of separating arbitrary sources, given a few examples of the target sources as queries. However, separating arbitrary sounds with a single system is challenging, and the robustness is not always guaranteed. In this work, we propose audio prompt tuning (APT), a simple yet effective approach to enhance existing USS systems. Specifically, APT improves the separation performance of specific sources through training a small number of prompt parameters with limited audio samples, while maintaining the generalization of the USS model by keeping its parameters frozen. We evaluate the proposed method on MUSDB18 and ESC-50 datasets. Compared with the baseline model, APT can improve the signal-to-distortion ratio performance by 0.67 dB and 2.06 dB using the full training set of two datasets. Moreover, APT with only 5 audio samples even outperforms the baseline systems utilizing full training data on the ESC-50 dataset, indicating the great potential of few-shot APT.
Separate Anything You Describe
Aug 09, 2023Language-queried audio source separation (LASS) is a new paradigm for computational auditory scene analysis (CASA). LASS aims to separate a target sound from an audio mixture given a natural language query, which provides a natural and scalable interface for digital audio applications. Recent works on LASS, despite attaining promising separation performance on specific sources (e.g., musical instruments, limited classes of audio events), are unable to separate audio concepts in the open domain. In this work, we introduce AudioSep, a foundation model for open-domain audio source separation with natural language queries. We train AudioSep on large-scale multimodal datasets and extensively evaluate its capabilities on numerous tasks including audio event separation, musical instrument separation, and speech enhancement. AudioSep demonstrates strong separation performance and impressive zero-shot generalization ability using audio captions or text labels as queries, substantially outperforming previous audio-queried and language-queried sound separation models. For reproducibility of this work, we will release the source code, evaluation benchmark and pre-trained model at: https://github.com/Audio-AGI/AudioSep.
Power pooling: An adaptive pooling function for weakly labelled sound event detection
Oct 20, 2020
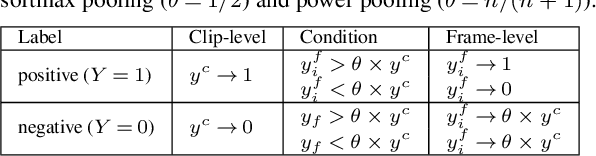

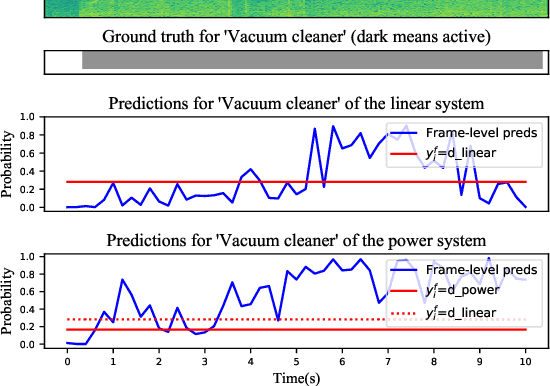
Access to large corpora with strongly labelled sound events is expensive and difficult in engineering applications. Much research turns to address the problem of how to detect both the types and the timestamps of sound events with weak labels that only specify the types. This task can be treated as a multiple instance learning (MIL) problem, and the key to it is the design of a pooling function. In this paper, we propose an adaptive power pooling function which can automatically adapt to various sound sources. On two public datasets, the proposed power pooling function outperforms the state-of-the-art linear softmax pooling on both coarsegrained and fine-grained metrics. Notably, it improves the event-based F1 score (which evaluates the detection of event onsets and offsets) by 11.4% and 10.2% relative on the two datasets. While this paper focuses on sound event detection applications, the proposed method can be applied to MIL tasks in other domains.