 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-based Adaptive Compliance Method for Symmetric Bi-manual Manipulation
Mar 27, 2023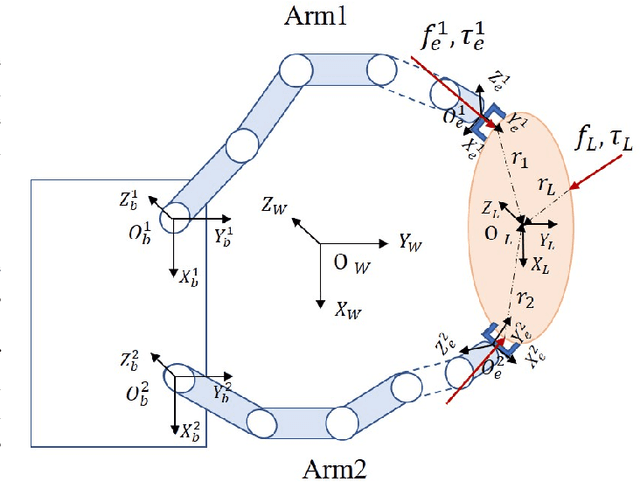
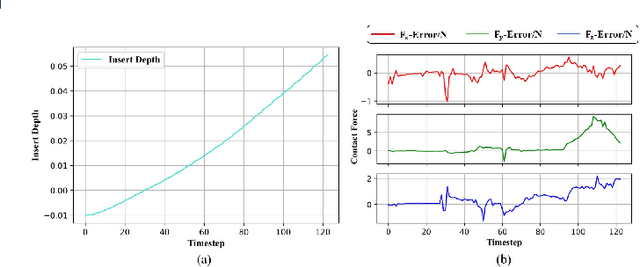
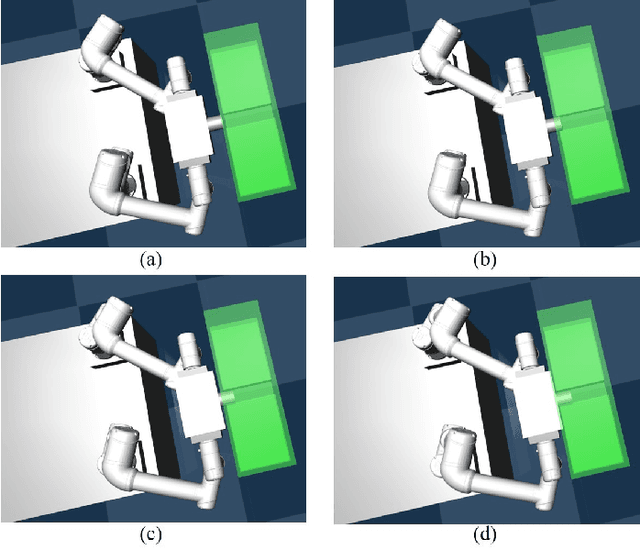
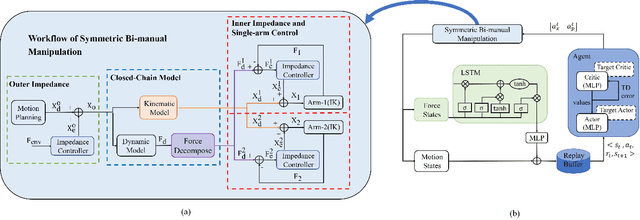
Symmetric bi-manual manipulation is essential for various on-orbit operations due to its potent load capacity. As a result, there exists an emerging research interest in the problem of achieving high operation accuracy while enhancing adaptability and compliance. However, previous works relied on an inefficient algorithm framework that separates motion planning from compliant control. Additionally, the compliant controller lacks robustness due to manually adjusted parameters. This paper proposes a novel Learning-based Adaptive Compliance algorithm (LAC) that improves the efficiency and robustness of symmetric bi-manual manipulation. Specifically, first, the algorithm framework combines desired trajectory generation with impedance-parameter adjustment to improve efficiency and robustness. Second, we introduce a centralized Actor-Critic framework with LSTM networks, enhancing the synchronization of bi-manual manipulation. LSTM networks pre-process the force states obtained by the agents, further ameliorating the performance of compliance operations. When evaluated in the dual-arm cooperative handling and peg-in-hole assembly experiments, our method outperforms baseline algorithms in terms of optimality and robustness.
A RL-based Policy Optimization Method Guided by Adaptive Stability Certification
Jan 02, 2023In contrast to the control-theoretic methods, the lack of stability guarantee remains a significant problem for model-free reinforcement learning (RL) methods. Jointly learning a policy and a Lyapunov function has recently become a promising approach to ensuring the whole system with a stability guarantee. However, the classical Lyapunov constraints researchers introduced cannot stabilize the system during the sampling-based optimization. Therefore, we propose the Adaptive Stability Certification (ASC), making the system reach sampling-based stability. Because the ASC condition can search for the optimal policy heuristically, we design the Adaptive Lyapunov-based Actor-Critic (ALAC) algorithm based on the ASC condition. Meanwhile, our algorithm avoids the optimization problem that a variety of constraints are coupled into the objective in current approaches. When evaluated on ten robotic tasks, our method achieves lower accumulated cost and fewer stability constraint violations than previous studies.
Reinforcement Learning with Prior Policy Guidance for Motion Planning of Dual-Arm Free-Floating Space Robot
Sep 03, 2022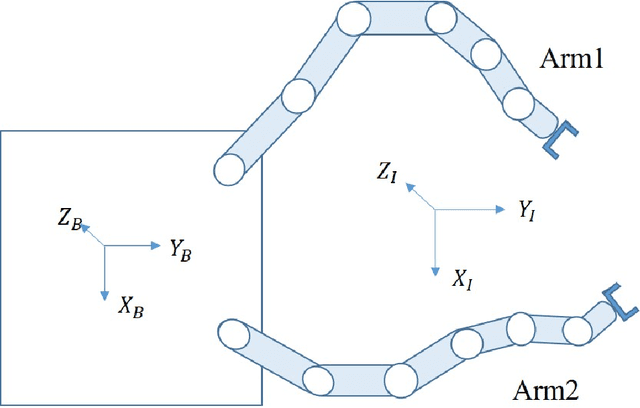

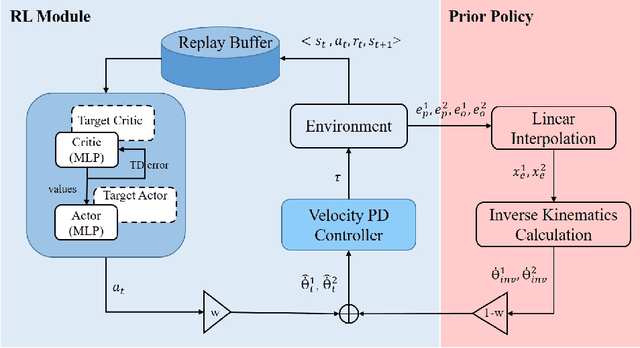

Reinforcement learning methods as a promising technique have achieved superior results in the motion planning of free-floating space robots. However, due to the increase in planning dimension and the intensification of system dynamics coupling, the motion planning of dual-arm free-floating space robots remains an open challenge. In particular, the current study cannot handle the task of capturing a non-cooperative object due to the lack of the pose constraint of the end-effectors. To address the problem, we propose a novel algorithm, EfficientLPT, to facilitate RL-based methods to improve planning accuracy efficiently. Our core contributions are constructing a mixed policy with prior knowledge guidance and introducing infinite norm to build a more reasonable reward function. Furthermore, our method successfully captures a rotating object with different spinning speeds.
A Learning System for Motion Planning of Free-Float Dual-Arm Space Manipulator towards Non-Cooperative Object
Jul 06, 2022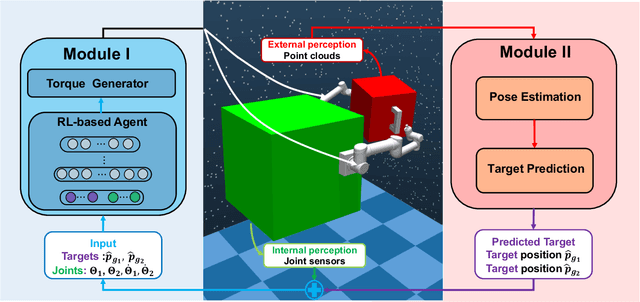
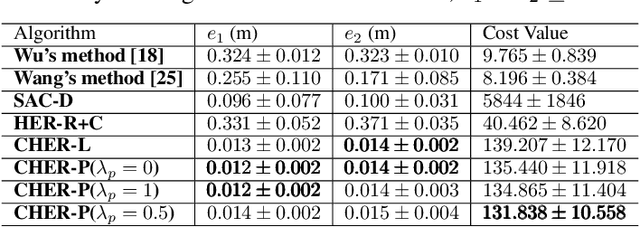
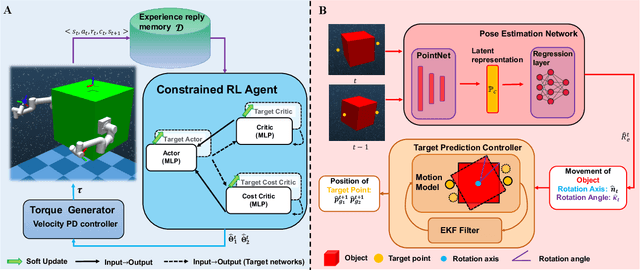
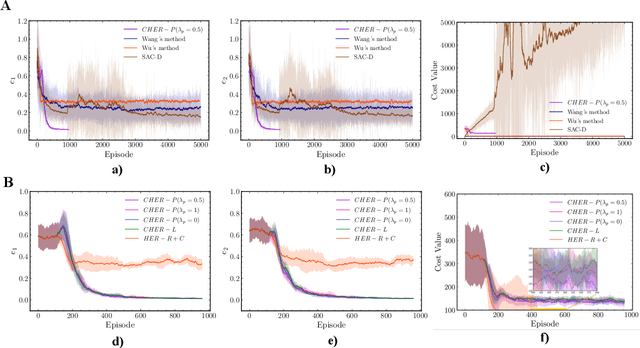
Recent years have seen the emergence of non-cooperative objects in space, like failed satellites and space junk. These objects are usually operated or collected by free-float dual-arm space manipulators. Thanks to eliminating the difficulties of modeling and manual parameter-tuning, reinforcement learning (RL) methods have shown a more promising sign in the trajectory planning of space manipulators. Although previous studies demonstrate their effectiveness, they cannot be applied in tracking dynamic targets with unknown rotation (non-cooperative objects). In this paper, we proposed a learning system for motion planning of free-float dual-arm space manipulator (FFDASM) towards non-cooperative objects. Specifically, our method consists of two modules. Module I realizes the multi-target trajectory planning for two end-effectors within a large target space. Next, Module II takes as input the point clouds of the non-cooperative object to estimate the motional property, and then can predict the position of target points on an non-cooperative object. We leveraged the combination of Module I and Module II to track target points on a spinning object with unknown regularity successfully. Furthermore, the experiments also demonstrate the scalability and generalization of our learning system.