 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHibikino-Musashi@Home 2019 Team Description Paper
May 29, 2020
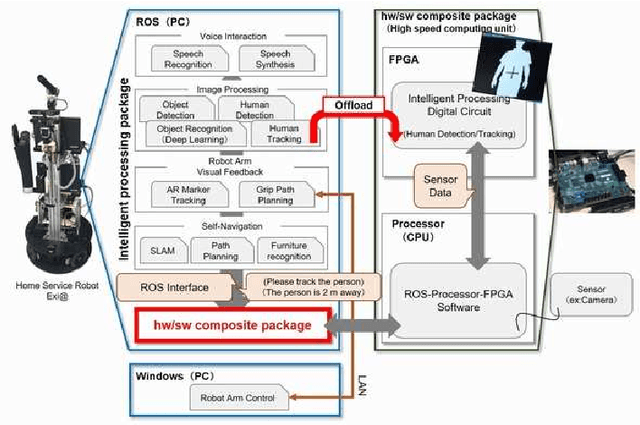
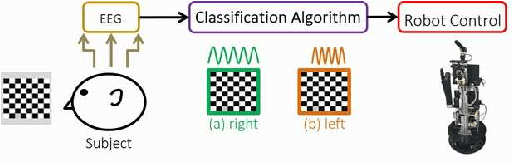
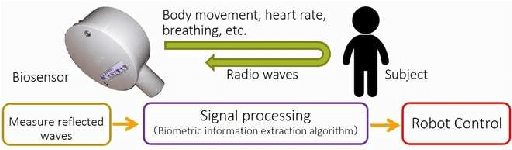
Our team, Hibikino-Musashi@Home (HMA), was founded in 2010. It is based in the Kitakyushu Science and Research Park, Japan. Since 2010, we have participated in the RoboCup@Home Japan Open competition open platform league annually. We have also participated in the RoboCup 2017 Nagoya as an open platform league and domestic standard platform league teams, and in the RoboCup 2018 Montreal as a domestic standard platform league team. Currently, we have 23 members from seven different laboratories based in Kyushu Institute of Technology. This paper aims to introduce the activities that are performed by our team and the technologies that we use.
Hibikino-Musashi@Home 2020 Team Description Paper
May 29, 2020Our team, Hibikino-Musashi@Home (HMA), was founded in 2010. It is based in Japan in the Kitakyushu Science and Research Park. Since 2010, we have annually participated in the RoboCup@Home Japan Open competition in the open platform league (OPL). We participated as an open platform league team in the 2017 Nagoya RoboCup competition and as a domestic standard platform league (DSPL) team in the 2017 Nagoya, 2018 Montreal, and 2019 Sydney RoboCup competitions. We also participated in the World Robot Challenge (WRC) 2018 in the service-robotics category of the partner-robot challenge (real space) and won first place. Currently, we have 20 members from eight different laboratories within the Kyushu Institute of Technology. In this paper, we introduce the activities that have been performed by our team and the technologies that we use.
Caption Generation of Robot Behaviors based on Unsupervised Learning of Action Segments
Mar 23, 2020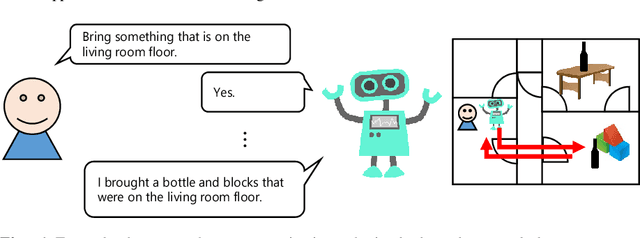


Bridging robot action sequences and their natural language captions is an important task to increase explainability of human assisting robots in their recently evolving field. In this paper, we propose a system for generating natural language captions that describe behaviors of human assisting robots. The system describes robot actions by using robot observations; histories from actuator systems and cameras, toward end-to-end bridging between robot actions and natural language captions. Two reasons make it challenging to apply existing sequence-to-sequence models to this mapping: 1) it is hard to prepare a large-scale dataset for any kind of robots and their environment, and 2) there is a gap between the number of samples obtained from robot action observations and generated word sequences of captions. We introduced unsupervised segmentation based on K-means clustering to unify typical robot observation patterns into a class. This method makes it possible for the network to learn the relationship from a small amount of data. Moreover, we utilized a chunking method based on byte-pair encoding (BPE) to fill in the gap between the number of samples of robot action observations and words in a caption. We also applied an attention mechanism to the segmentation task. Experimental results show that the proposed model based on unsupervised learning can generate better descriptions than other methods. We also show that the attention mechanism did not work well in our low-resource setting.
Multi-Source Neural Machine Translation with Data Augmentation
Oct 16, 2018


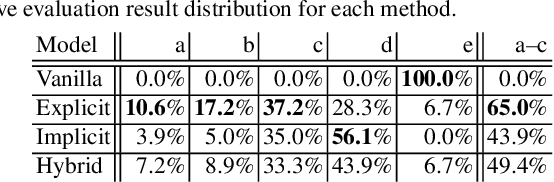
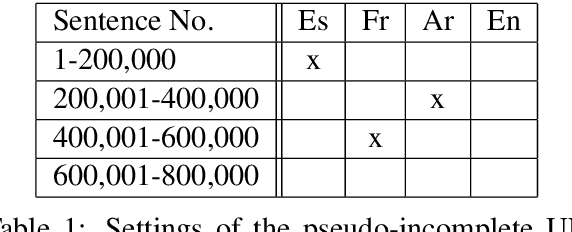
Multi-source translation systems translate from multiple languages to a single target language. By using information from these multiple sources, these systems achieve large gains in accuracy. To train these systems, it is necessary to have corpora with parallel text in multiple sources and the target language. However, these corpora are rarely complete in practice due to the difficulty of providing human translations in all of the relevant languages. In this paper, we propose a data augmentation approach to fill such incomplete parts using multi-source neural machine translation (NMT). In our experiments, results varied over different language combinations but significant gains were observed when using a source language similar to the target language.
Multi-Source Neural Machine Translation with Missing Data
Jun 08, 2018


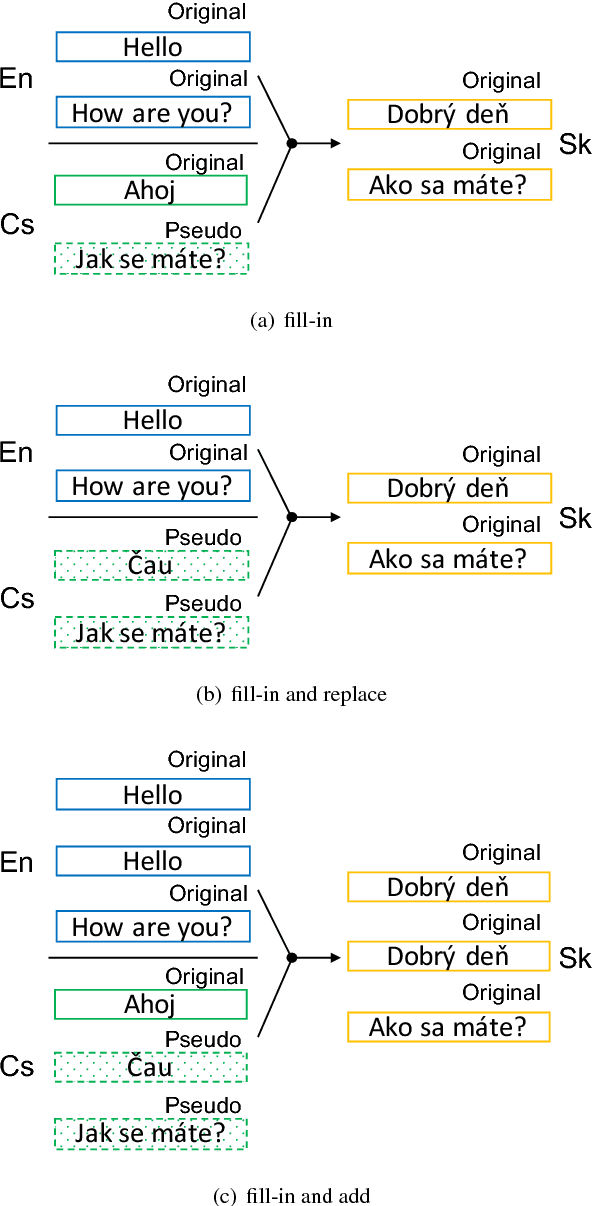
Multi-source translation is an approach to exploit multiple inputs (e.g. in two different languages) to increase translation accuracy. In this paper, we examine approaches for multi-source neural machine translation (NMT) using an incomplete multilingual corpus in which some translations are missing. In practice, many multilingual corpora are not complete due to the difficulty to provide translations in all of the relevant languages (for example, in TED talks, most English talks only have subtitles for a small portion of the languages that TED supports). Existing studies on multi-source translation did not explicitly handle such situations. This study focuses on the use of incomplete multilingual corpora in multi-encoder NMT and mixture of NMT experts and examines a very simple implementation where missing source translations are replaced by a special symbol <NULL>. These methods allow us to use incomplete corpora both at training time and test time. In experiments with real incomplete multilingual corpora of TED Talks, the multi-source NMT with the <NULL> tokens achieved higher translation accuracies measured by BLEU than those by any one-to-one NMT systems.